

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Chaque année, le nombre d’incidents et d’attaques ne cesse d’augmenter. Quelles que soient les méthodes d’intrusion utilisées par les attaquants, elles évoluent rapidement et aucun système d'information n'est sûr à 100 %. Beaucoup de travaux traitent du sujet de la détection d’intrusion en temps réel sous l'angle des systèmes IDS dits « passifs ». Sur la même échelle de temps et le même spectre d’analyse (un paquet, une requête), nous trouvons également des systèmes dits « actifs » de prévention d’intrusion (IPS, WAF) qui bloquent le trafic suspect. Il faut préciser que ces sondes IDS/IPS servent à détecter des tentatives d'intrusion, mais pas au sens d'attaques réussies. Elles remontent des événements en temps réel et visent à identifier de manière proactive ou réactive des comportements malveillants. Les plus efficaces d’entre elles peuvent inclure, dans leur mécanisme d’alerte, une information liée au succès de l’attaque.
1. Un cadre juridique et de sécurité de l'information
1.1 Les enjeux de la sécurité des systèmes d'information
Les risques d’atteinte aux données et aux systèmes informatiques selon des critères de disponibilité, d’intégrité et de confidentialité constituent les enjeux de la sécurité des systèmes d'information. Des simples défacements de sites web (lesquels se multiplient [1]) aux attaques synchronisées contre des infrastructures complexes, l’échelle des possibles s’élargit et aucune voie ne doit être écartée en termes de détection d’intrusion.
Par le passé, les attaques informatiques exploitaient majoritairement des failles systèmes ou réseaux. Aujourd’hui, le nombre de vulnérabilités applicatives reste élevé et les délais entre la découverte d’une vulnérabilité et son exploitation ont diminué fortement. L’exploitation de vulnérabilités informatiques comme celles décrites par le top 10 OWASP [2] vise à porter atteinte à l’intégrité ou la disponibilité du système d'information avec la possibilité de contamination virale.

De nouvelles vulnérabilités sont découvertes, mais non rendues publiques par leurs inventeurs (connues sous le nom d’exploit zero-day) et font l’objet d’un commerce souterrain lucratif entre organisations et pirates informatiques.
Les attaquants peuvent scanner un nombre important de machines à la recherche de ces vulnérabilités. Une fois la faille applicative découverte, la machine peut être infectée par un code malveillant (le ver) qui se propagera par copie de lui-même à des milliers de machines et ce, dans un laps de temps très court. En 2003, le ver SQL Slammer (code informatique de 376 bytes) contenu dans un seul paquet UDP exploitait une vulnérabilité de Microsoft SQL Server. Il s'est propagé très rapidement (moins de 10 minutes) sur le réseau Internet. Il a eu des conséquences néfastes sur certains réseaux d’opérateurs (surcharge de bande passante et trafic réseau ralenti ou interrompu) et de nombreuses infrastructures critiques dont le système était vulnérable. Au total, ce sont 200.000 serveurs qui ont été infectés dans le monde avec un impact tant sur le plan de la productivité que financier. En réaction, il ne restait plus qu’au fournisseur de transit de poser une ACL (filtrer 1434/udp) pour éviter de perdre son réseau et enrayer la propagation du ver.
D'après le rapport APWG [4] portant sur le second semestre de l’année 2012 des activités de détection et de lutte contre le phishing, 123.486 attaques de phishing ont été observées à travers le monde. Le nombre d’attaques est en augmentation constante : 83.462 au second semestre 2011 et 93.462 au premier semestre 2012. Selon le rapport, cette augmentation s'explique par le fait que les fraudeurs ciblent tout particulièrement les serveurs virtuels partagés sur des hébergements mutualisés. Ces serveurs virtuels partagés agissent comme un effet de levier. Le principal danger réside sans doute dans le développement du phénomène des machines « zombies » ou des serveurs sous hébergement « freehost » et leur constitution en « botnets ». Fin 2012 et pour 2013, les hébergements mutualisés ont été pris majoritairement pour cible par les attaquants. Ces fermes de serveurs hébergeant du cPanel et des CMS comme Wordpress ou Joomla, ont permis de constituer un réseau botnet et perpétrer des attaques DDos, du type itsoknoproblembro [5] contre les banques américaines. Au total, ce sont 10.000 à 100.000 serveurs compromis qui ont servi à toutes sortes d'activités malveillantes comme du DDos, la distribution de codes malveillants (ver, virus, chevaux de Troie et autres menaces) et bien sûr du phishing. Ces serveurs sont le plus souvent exposés à des vulnérabilités applicatives et à des mots de passe trop faibles.
Le Google Online Security Blog [6] rapporte qu'approximativement, 12 à 14 millions de requêtes de recherche par jour, conduisent à des sites compromis. Un grand nombre de ces sites web sont dits légitimes et libèrent un code malveillant pour infecter le poste client du visiteur. Cette attaque appelée « Drive-by download » exploite une vulnérabilité dans le navigateur pour exécuter un code malveillant sur le poste du visiteur, et ce à son insu.
Le danger réside également dans le développement par certains pays des capacités de lutte informatique offensive (LIO) et en premier lieu des techniques virales sophistiquées. Ces pays n’hésitent pas à les mettre en œuvre à des fins d’espionnage étatique et économique (vol de propriété intellectuelle, de données financières, etc.). La mondialisation génère de nouvelles menaces et dangers visant les États, les infrastructures critiques et les services stratégiques financiers, socio-économiques, etc.
En avril 2013, le Livre blanc sur la défense et la sécurité nationale [7] précise que les cyberattaques « constituent une menace majeure, à forte probabilité et à fort impact potentiel », que cet impact de sécurité lié aux « tentatives de pénétration de réseaux numériques » sont les vols d'informations à des fins d'espionnage au sein des systèmes d'information de l'État ou ceux des entreprises. Ces intrusions sont quotidiennes. C'est par des mesures législatives et réglementaires que ces grandes entreprises nationales ou privées, qualifiées « opérateurs d'importance vitale » et qui exploitent des infrastructures critiques (banques, transport, énergie, etc.) auront à prendre « les mesures nécessaires pour détecter et traiter tout incident informatique touchant leurs systèmes sensibles ».
En termes d’atteinte à l’image de l’entreprise, ces intrusions sont amenées à être médiatisées. Par exemple, l'année 2011 a été marquée par l'attaque ciblée sur le ministère de l’Économie et des Finances de Bercy ou celle contre la société RSA Security spécialisée dans le domaine de l’authentification forte [8].
1.2 Les contraintes légales
Jusqu’en 1986, peu de textes de loi réglementent le piratage informatique ou ce que l’on qualifie aujourd’hui de cybercriminalité. L’absence de répression pénale spécifique à ces actes posait des problèmes aux juristes. De nos jours, s'introduire sans autorisation dans un système de traitement automatisé de données, le détourner ou s'en servir pour un flux de données sortant, sont des actes délictueux et réprimés au pénal.

C’est la loi dite Godfrain du 5 janvier 1988, n°88-19, relative aux atteintes aux Systèmes de Traitement Automatisés de Données (STAD) qui préfigure en la matière. Son objectif est de protéger les systèmes d’information (confidentialité, intégrité, disponibilité des données) et de réprimer la fraude informatique. On ne retrouve aucune définition du STAD dans le Code Pénal. L'Assemblée Nationale a refusé de figer l’état du droit en donnant une définition. La jurisprudence se réfère donc à la définition proposée par le Sénat : « Tout ensemble composé d’une ou plusieurs unités de traitement, de mémoires, de logiciels, de données, d’organes d’entrées-sorties et de liaisons qui concourent à un résultat déterminé ».
Lorsque l'on fait référence à la réglementation en lien avec à la détection d’intrusion, on pense à la loi Godfrain et aux articles 323-1 à 323-7 C. pén. qui définissent et répriment l'intrusion sur un système d'information.
En droit pénal, pour que l'imputabilité soit admise, il faut qu'il y ait un élément moral (un accès sans droit et en connaissance de cause) ou une volonté consciente et délibérée de commettre l’élément matériel de l’infraction (un accès non autorisé suivi d’un maintien dans le STAD). Force est de constater que les systèmes de traitement automatisé de données sont aujourd'hui au cœur d'un contentieux pénal et font l'objet d'interprétations jurisprudentielles :
- Le piratage informatique ou l'intrusion sur des systèmes informatiques avec accès et maintien frauduleux dans tout ou partie d'un système de traitement automatisé de données (art. 323-1 C. pén.) ;
En octobre 2012, le tribunal correctionnel de Rennes, dans l'affaire de la Banque de France a relaxé le prévenu qui après avoir saisi un mot de passe au hasard (123456), s'était introduit sur un serveur vocal non identifié ayant permis l'accès à un menu technique sensible. La loi incrimine le maintien irrégulier dans un système de la part de celui qui y serait entré par inadvertance, ou de la part de celui qui, y ayant régulièrement pénétré, se serait maintenu frauduleusement. Or, en l'absence de preuve de la volonté de s'introduire sur un système d'information protégé (art. 323-1 C. pén. reprenant les accès « frauduleux ») et sans message d'information spécifique ou blocage technique particulier marquant nettement que l'accès au SI était réservé, l'intrusion n'a pas été qualifiée. - Nuire au fonctionnement, ajouter, modifier ou détruire des données (art. 323-2 et 323-3 C. pén.) ;
Rares sont les cas de jurisprudence en France qui traitent des attaques par déni de service.
Le 15 novembre 2011, la cour d'appel de Bordeaux a renvoyé M. Cédric M. des fins de la poursuite pour des attaques en déni de service sur le serveur informatique de la société C-Discount. D'une part, les compétences de l'attaquant ont démontré l'absence de volonté de bloquer le système. D'autre part, le nombre insuffisant de connexions générées durant un temps limité au regard des ressources du serveur d'hébergement ont démontré l'absence de preuves d'une entrave et d'une perturbation sensible sur le site web de la victime. - L'utilisation des outils logiciels ou matériels destinés au piratage (art. 323-3-1 C. pén.) ;
L'introduction volontaire d'un programme « sniffer » dans un système de traitement automatisé de données ainsi que l'introduction frauduleuse de données dans ce même système ont été jugées comme des délits par le tribunal de grande instance de Paris [9] au titre des articles 323-3 et 323-3-1 C. pén. - Participer à « un groupement formé ou à une entente établie » de pirates (art. 323-4 C. pén.) ;
La plupart des jurisprudences basées sur cet article précisent que « l'entente » doit se concrétiser par un ou plusieurs faits matériels (e.g. échange d'informations) ayant pour finalité de commettre des atteintes à un système informatique. - Les peines complémentaires et la responsabilité des personnes morales (art. 323-5 et 323-6 C. pén.) ;
- La tentative des délits prévus par les articles 323-1 à 323-3-1 est punie des mêmes peines (art. 323-7 C. pén.).
Cette notion de « tentative » pose un vrai problème de preuve. Suite à une plainte contre X du Garde des Sceaux, la cour d'appel de Rennes a relaxé le 30 avril 2009, un prévenu pour intrusion dans le STAD. Ce dernier avait mené une attaque par injection de code SQL sur la base de données ORACLE pour en « déceler » les failles de sécurité. La cour d'appel a rendu un arrêt d'espèce faute de preuves suffisantes.
Depuis le 21 juin 2004, la loi dite Godfrain a été renforcée par la loi n°2004-575 pour la confiance dans l'économie numérique (LCEN) qui a aggravé les peines.
Concernant la responsabilité du représentant légal de l'entreprise, elle pourrait être recherchée, au titre du délit de manquement à la sécurité et des articles 226-15, 226-16 C. pén. et suivants relatifs à l'atteinte au secret des correspondances et aux libertés individuelles. Ainsi, l'article 226-15 limite les actes de surveillance qui pourraient être engagés pour garantir la sécurité du réseau informatique.
En matière de détection d'intrusion, il est parfois délicat d'apprécier les actions techniques à mener tout en restant dans le respect du droit et sans exposer sa propre responsabilité ou celle du représentant légal de l'entreprise. En cas d'intrusion avérée et du dépôt d'une plainte, les journaux d'activité doivent être recevables en termes de preuve. Leur contenu et leur existence doivent être valables aux yeux d’un juge. Tout système de traitement automatisé de données contenant des données à caractère personnel doit faire l'objet d'une déclaration préalable auprès de la CNIL (Commission Nationale de l'Informatique et des Libertés) en fonction de la finalité du traitement des données concernées. On pense donc aux journaux de connexions, de sécurité d'un IDS ou d'un pare-feu qui doivent faire l'objet d'une attention toute particulière si les adresses IP permettent de remonter jusqu'à l'individu. L'article 2 de la Directive européenne 2006/24/CE, concernant le traitement des données à caractère personnel et la protection de la vie privée dans le secteur du commerce électronique inclut l'adresse IP dans les données à caractère personnel. Toutefois la question demeure confuse en France et aucune jurisprudence ne vient confirmer de façon claire et entière ce point.
Dans la recherche des traces d'intrusion, on identifie rapidement le dernier « rebond » avant intrusion. À ce niveau, on peut solliciter la bienveillante collaboration de l'administrateur distant, mais toute mesure offensive qui consisterait à pirater le site de rebond pour identifier l'origine de l'attaque, mettrait l'entreprise dans l'illégalité au titre de l'article 323-1 C. pén. et alinéas suivants. À ce sujet, le concept de vigilantism (auto-défense) que l'on retrouve chez les anglo-saxons entre en contradiction avec les réglementations nationales.
Deux autres problématiques viennent s'ajouter : celle du lieu de commissionnement du délit et celle du lieu d'implantation de la ressource investiguée (e.g. serveur web hébergé sur une solution de stockage Cloud). On pourrait imaginer le scénario suivant où une entreprise française est victime d'une intrusion effectuée depuis un État de l’Afrique centrale et dont les ressources compromises sont sur le territoire américain. Le dépôt de plainte par la victime pourra aisément s'effectuer sur le territoire français, mais l'analyse des supports et la recherche du ou des auteurs, indépendamment des possibilités techniques, devra prendre en compte la territorialité et les différents régimes juridiques des États concernés par cette intrusion. L’enquêteur ne pourra pas accéder aux données. Il devra localiser précisément les adresses IP du ou des serveurs à l'origine de l'intrusion. Pour obtenir les données, il devra solliciter la conservation de celles-ci (point de contact H24/7 sous la gérance du G8 ou Interpol) et disposer d’une commission rogatoire internationale adressée aux autorités américaines pour se les faire remettre.
2. Un cadre technique et architectural
2.1 Description d’un système de détection d’intrusion
Dans le domaine de la standardisation des IDS, le groupe de travail IDWG (Intrusion Detection Exchange Format) de l’IETF (Internet Engineering Task Force) décrit un modèle d’architecture d’un système de détection d’intrusion.
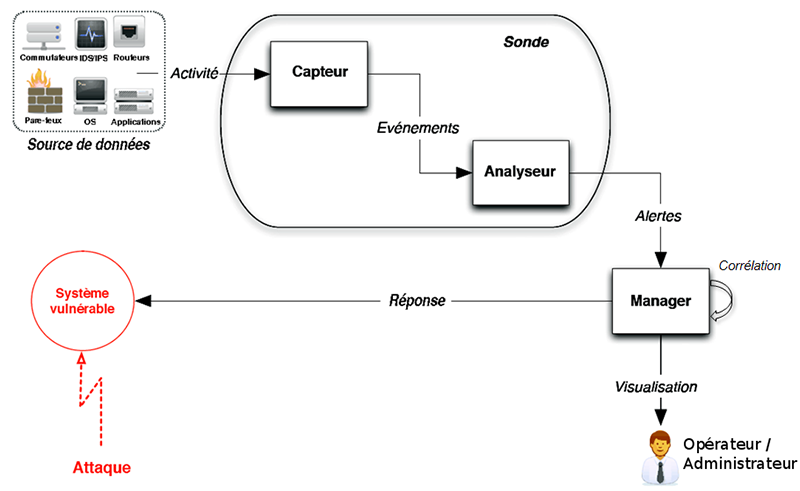
Comme illustré dans la figure 4 (vue macroscopique) [10], l’architecture IDWG d’un système de détection d’intrusion contient des capteurs qui collectent les données brutes vues comme une suite d’octets (reflet direct d’une activité) depuis une source de données (interface réseau, journaux système, etc.), détecte les événements et les envoient à un analyseur. Un ou plusieurs capteurs associés à un analyseur constituent l’environnement d’une sonde de détection d’intrusion. L’analyseur est un processus chargé de filtrer et de qualifier les événements. Il lève une alerte si un événement est intéressant (Event of Interest ou EOI) au regard de la sécurité du système d’information. Ce peut-être l'ouverture inattendue d'une session Telnet, les entrées des fichiers de journaux système qui retracent un utilisateur qui tente d'accéder à des fichiers dont il n'a pas les droits d'accès ou des échecs de connexion répétés, etc. Les alertes (et donc les événements associés) sont transmises de l’analyseur vers le gestionnaire d’alertes (manager) qui notifie un opérateur humain (console de supervision, trappe SNMP, envoi d’un e-mail). Les événements doivent être convertis dans un format de message d’alertes (e.g. IDMEF) avant d’être transmis. Cette normalisation est nécessaire pour homogénéiser les alertes indépendamment des modèles de sondes et des sources de données. L’opérateur de sécurité valide les alertes et met en place des contre-mesures appropriées (réponses) qui peuvent être automatisées. L’administrateur sécurité (composante humaine) configure la sonde et le gestionnaire d’alertes conformément à la politique de sécurité. Il est à noter que l’opérateur et l’administrateur peuvent être la même personne.
Dans le cadre d’un environnement réel, il n’y a pas d’architecture type. Certains IDS vont combiner ces entités fonctionnelles dans un seul module. D’autres solutions vont s’appuyer sur des applications externes pour compléter le système de détection d’intrusion (e.g. Suricata [11]).
Tous les équipements de sécurité (pare-feu, systèmes de détection d’intrusion, etc.) ou les systèmes et équipements réseau (routeurs, serveurs, etc.) d’un système d’information susceptibles de remonter des événements, vus comme des signaux, permettent de construire une perception de l’état du système d’information et donc participent à la détection d’intrusion. Tous ces événements qui se présentent sous la forme de données brutes doivent pouvoir faire l'objet d'un pré-filtrage à la source avant d'être triés et qualifiés par le moteur de corrélation. Ainsi, certains événements inscrits dans les journaux du système d’exploitation et des applications peuvent être écartés de l’analyse. À titre d'exemple, la trace d'une élévation de privilèges avec la commande « su - » sur les horaires de présence des administrateurs systèmes, n'aura pas besoin d'être surveillée.
Une architecture globale de supervision peut également être construite autour d’une solution très structurante comme le SOC (Security Operation Center ou centre opérationnel de sécurité). Le SOC permet non seulement de couvrir un large spectre de données provenant de différentes sources (modules IDS/IPS, pare-feu, routeur, postes de travail, application, serveur, équipement réseau, etc.), mais aussi d'avoir une vision globale de la sécurité du système supervisé.
L’architecture SOC est composée d’une base de connaissance de toutes les informations relatives à l’infrastructure réseaux et systèmes (e.g. les adresses IP, les noms des machines, les applications installées sur chaque machine et leur version, etc.) et des vulnérabilités (systèmes d’exploitation, applications, réseaux, etc.) qui pourraient être exploitées par un attaquant pour s’introduire dans le système. Ces informations structurelles permettent de coupler une information d’état telle que la vulnérabilité d’un serveur à une information d’action telle que la détection de cette attaque à destination du serveur en question.
Avant de configurer les sondes, de concevoir des règles d’analyse et de corrélation des alertes, il est nécessaire d’évaluer à chaque changement du système à superviser et à chaque nouvelle vulnérabilité découverte, le niveau de sécurité d’une l’infrastructure IT.
Cette évaluation permet de déterminer si une intrusion sur le système est possible et si elle peut s’avérer critique. L’évaluation de la criticité d’un événement est une des opérations les plus difficiles dans la mesure où elle prend en compte, d’une part, l’importance de la ressource cible et, d’autre part, l’impact de l’attaque sur cette ressource. Les tests d’intrusion font partie intégrante de cette évaluation et participent à améliorer la qualité du diagnostic.
Le SOC va également tenir compte des aspects de la politique de sécurité en termes de contrôle d’accès (e.g. l’authentification des administrateurs) et d’opérations autorisées (e.g. le scan de ports depuis une adresse IP spécifique dans le cadre d’un audit de sécurité). Tout autre comportement traité par les sondes sera alors vu comme une tentative d’intrusion.
2.2 Les technologies d’analyse et leurs limites
En tant que moteur d'analyse, les méthodes de détection sont au cœur des technologies de détection d'intrusion. Elles analysent les informations au sein d’un flux de données qu'elles surveillent et remontent des alarmes dès qu'elles détectent un trafic malveillant. Les différentes méthodes de détection peuvent être étudiées selon deux approches : l'approche par scénario et l'approche comportementale (appelée aussi détection d’anomalies).
L’approche par scénario se base sur la connaissance des attaques connues et des vulnérabilités. Cette méthode, basée sur la reconnaissance de signatures d’attaques, consiste à détecter toute action qui n’est pas explicitement identique aux motifs caractéristiques d’une d'attaque connue comme acceptable. La recherche de motifs (à partir d’algorithmes de « pattern matching ») dans les en-têtes et les données utiles des paquets réseau est la forme la plus courante de détection par scénario. Le motif est représenté par une chaîne de caractères.
L’exemple trivial qui suit est une signature extraite de la base de règle Snort. Cette règle permet d’analyser la chaîne précisée par le champ « content » et détecter l’exploitation d’une vulnérabilité critique liée à l'extension JCE (Joomla! Content Editor).
alert tcp $EXTERNAL_NET any -> $HOME_NET 80 (msg:"Attaque Joomla"; flow:established,to_server; content:"/editice/images/stories/0day.php"; nocase)
La chaîne de caractères correspondant à l'URL permet d'introduire une porte dérobée (« 0day.php ») par la méthode POST sur le serveur web.
Il existe d'autres méthodes d'approches par scénario, parmi lesquelles on peut citer les systèmes experts en détection d'intrusion ou les réseaux de Petri (RdP) colorés pour décrire de façon plus naturelle des événements reliés entre eux et permettre aux administrateurs systèmes et réseaux d'écrire leurs propres signatures d'attaques.
Voici un exemple simple de RdP où quatre tentatives de connexion infructueuses dans la minute déclenchent une alerte [12] :

Ainsi, la transition n'est validée et son franchissement n'est possible que s'il y a un jeton dans la place en amont et si la tentative de connexion a échoué. Le temps correspondant à la première tentative de connexion infructueuse est stocké dans le jeton de la variable t1. La transition en S5 et une différence de temps entre t2 et t1 inférieure ou égale à 60 secondes déclenchent une alerte.
Les méthodes de détection à base de signatures s’apparentent en termes de fonctionnalités aux scanners de virus qui peuvent détecter tous les modèles d'attaques connus. Pour détecter les événements malveillants, il est nécessaire de posséder une base de données de signatures de toutes les attaques connues et leurs variantes. Elle devra être actualisée et enrichie de façon régulière à défaut d’entraîner des faux négatifs.
L’approche par scénario est facile à contourner, car seules les attaques connues seront détectées. Un attaquant pourra alors exploiter des encodages de caractères différents ou jouer sur la représentation des données (les espaces, les fins de lignes, la représentation des répertoires, etc.) et ainsi déguiser son attaque afin qu’elle ne soit pas détectée.
D'autres techniques d'évasion classiques comme la fragmentation IP, la segmentation TCP, ainsi que les types d'invalidité (somme de contrôle incorrecte, taille de fenêtre TCP invalide, etc.) ou les flux de données chiffrées permettent de déjouer la capacité d'un IDS à détecter une activité malveillante. Aujourd'hui, les IDS/IPS implémentent des préprocesseurs qui permettent de reconstruire correctement les couches du modèle OSI, de détecter automatiquement les protocoles et d'étudier les négociations SSL/TLS. Cependant, les piles TCP/IP présentent de nombreuses caractéristiques différentes selon les systèmes d'exploitation et l'attaquant peut jouer de ces différences d'interprétation des RFC.
Enfin, lorsque le nombre de signatures est élevé et le trafic réel est important (de quelques centaines de Mb/s à quelques Gb/s [13]), la mise en correspondance de chaînes de caractères (ou expressions régulières) à la totalité ou à une partie des données peut s'avérer consommatrice en termes de performance et d’utilisation des ressources système (entrées/sorties, temps processeur).
L’approche comportementale ou détection d’anomalies consiste à mesurer une déviance par rapport à un modèle de comportements légitimes. C’est aussi l'une des méthodes de détection les plus courantes. Il s’agit tout simplement d'ignorer tout ce qui est « normal » et déclencher une alerte si l'événement s'écarte de la « normale ». Un détecteur d'anomalie fonctionne avec l'hypothèse que les événements malveillants diffèrent des actions normales (ou légitimes). Ainsi, les attaques sont détectées avec la découverte de ces différences. Les détecteurs d'anomalies créent des profils à partir des données recueillies du système observé (utilisateurs, applications, flux réseaux, etc.) sur une période appelée « phase d'apprentissage ». Un profil est caractérisé par une métrique (variable quantitative X décrivant un comportement légitime sur une période de temps donnée) et un modèle statistique (détecter si le nombre d'occurrences X correspond à la valeur de X déjà observée) ou probabiliste. Ensuite, les détecteurs collectent les événements et utilisent une variété de mesures afin de déterminer à quel moment l'activité surveillée, dévie d'une façon significative au modèle de comportement « normal ». Auquel cas, une alerte est déclenchée.
L’ensemble des activités intrusives est croisé uniquement avec l'ensemble des activités dites anormales. Puisque le comportement « normal » peut dévier de façon brusque (e.g. installation d’une nouvelle application) et que la portée du modèle ne peut couvrir l’ensemble des comportements possibles d’un système d’information, ce modèle génère de nombreux faux positifs et faux négatifs. En outre, il sera facile pour un attaquant de faire dévier graduellement son comportement du comportement normal. Ses actions, assimilées par le modèle à un profil utilisateur, ne seront alors pas détectées.
2.3 L’exploitation des données à traiter
La complexité et la singularité des gros réseaux sont très difficiles à appréhender par l’expertise humaine. Selon la taille et la topologie du réseau, la configuration des sondes et leur emplacement, il n’est pas rare de voir des milliers d’alertes par jour et par sonde. Dans ce cas, il est humainement impossible de distinguer les tentatives d’attaques réussies ou bien les faux positifs (événement détecté comme une attaque alors qu’il ne s’agit pas d’un réel événement d’intrusion). Pour gérer un tel volume et pour séparer le bon grain de l'ivraie, la corrélation d’alertes doit permettre de réduire le nombre d’alertes soumis à l’opérateur tout en améliorant la qualité de son diagnostic et lui permettre de suivre l’attaque dans son contexte global.
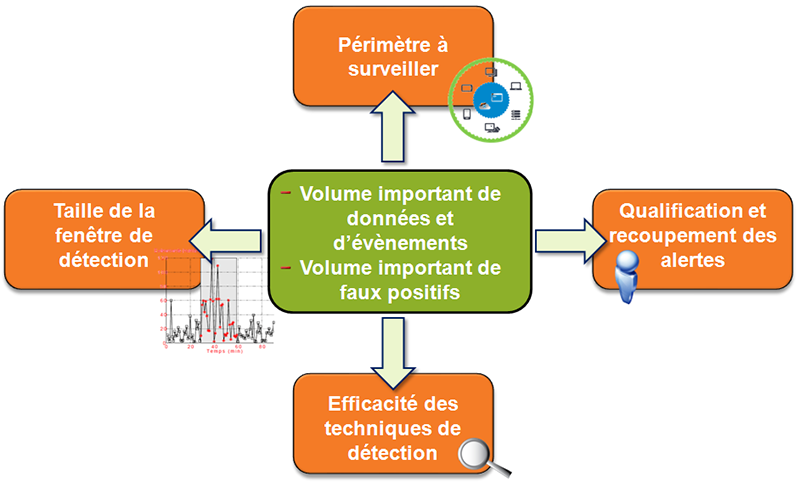
2.3.1 Réduction du volume d'alertes
Plusieurs raisons peuvent expliquer le volume important d’alertes. D’une part, les sondes génèrent un pourcentage important de faux positifs, que la sonde soit positionnée à l’extérieur d’un pare-feu, dans une zone démilitarisée ou dans le réseau interne. Un capteur (ou générateur d’événements) placé à l’extérieur d’un pare-feu offre un emplacement intéressant. Cela permet au capteur d’intercepter toutes les attaques en provenance du réseau Internet. Par contre, la sonde sera exposée à un grand nombre d’attaques par balayage (ex. : inondation de SYN dans le trafic TCP), générées par des outils automatisés et multipliera les alertes. La réduction des faux positifs imputable à l’algorithme de détection de la sonde passe inévitablement par l’amélioration des techniques de détection, mais cette amélioration sera à fortiori coûteuse en termes de performance (temps d’analyse ou dans la mesure où les analyseurs diffèrent d’un IDS à un autre, montée en charge par ajout de composants logiques à l’architecture). Cela passera également par la communication des données contextuelles entre les sondes et une analyse toujours plus fine des fausses alertes par l'administrateur sécurité ce qui le conduira à modifier, voire désactiver certaines règles et signatures de détection. C’est l’exemple des serveurs mandataires web internes à l’infrastructure qui dans leur fonctionnement normal établissent de nombreuses connexions TCP/IP sur une fenêtre de temps très courte. Dès lors, ce comportement, s’il n’est pas intégré dans la configuration des sondes, peut être assimilé à une activité intrusive (un balayage d’adresses IP) et détecté par l’IDS comme une alerte de sécurité alors que le trafic est légitime et dirigé vers le WAN.
D’autre part, les sondes multiplient la quantité globale d’alertes et par conséquent contribuent à l’excès d’alertes. La corrélation implicite d’alertes qui consiste à mettre en évidence des relations intrinsèques entre les alertes va permettre de réduire les grandes quantités d’alertes générées par les systèmes de détection d’intrusion. Plusieurs approches coexistent :
- La récurrence : certaines attaques (e.g. le déni de service) se caractérisent par des événements répétés. Une sonde qui associera une alerte à chaque événement sera à l’origine d’alertes récurrentes. Une fonction de corrélation implémentée au niveau du gestionnaire d’alertes permettra de fusionner ces alertes.
- La redondance : malgré des événements très disparates, les alertes remontées par plusieurs sondes peuvent concerner une même attaque. La corrélation des alertes peut provenir aussi bien du réseau que des équipements qui le peuplent. Ainsi, la signature d’une requête malicieuse adressée à un serveur web peut être détectée dans un paquet (capteur agissant au niveau des envois TCP) et dans une entrée d’un fichier journal applicatif (capteur agissant au niveau applicatif).
- L’agrégation : certaines alertes partagent une série d'attributs similaires. Ce peut être le type d’attaque, l’adresse IP source et de destination qui caractérisent une attaque. La similarité entre les alertes sur une fenêtre de temps sera le produit des similarités entre ces attributs. Ainsi, lors d'une attaque en déni de service réparti, l'adresse IP de destination et le type d'attaque auront un taux de similarité proche de 100 % pour l'ensemble des alertes. Par contre, l'adresse IP source aura un taux proche de 0 %. Ces alertes seront agrégées pour un traitement spécifique.
2.3.2 La connaissance des scénarios d’attaque
L'anatomie d'une intrusion est formée de scénarios d'attaque de plus en plus complexes, variés et constitutifs de plusieurs sous-attaques. Identifier un comportement caractéristique d’une progression sur un arbre d’attaque pour atteindre un même objectif (augmentation de privilèges, vol d’informations, dénis de service, etc.) est une autre composante de la détection d'intrusion. Pour cela, nous avons besoin de lier dynamiquement des événements aux stratégies d'attaque globale afin de fournir une surveillance des intrusions qui soit à la fois proactive et réactive.
Pour illustrer la corrélation explicite qui consiste à exprimer explicitement des relations entre des flux d’alertes sous la forme de scénarios d’attaques, nous allons nous intéresser aux travaux de M. J. Cloppert. En 2009, conjointement avec l'autorité de certification de Lockheed Martin, il s'est inspiré du processus qui régit les frappes militaires. Il a avancé le concept de « Kill Chain » ou « Chaîne de frappe » qu'il a appliqué aux intrusions dans un système d'information. Ce nouveau concept décrit la construction d'une attaque en 6 étapes séquentielles. Ces différentes phases constituent une grille de lecture et d'action pour l'attaquant.

- Phase 1 : l’attaquant collecte toutes sortes d’informations via les moteurs de recherche et/ou les réseaux sociaux afin d'identifier et sélectionner une cible ou un ensemble de cibles. L’attraction d’une cible va dépendre des motivations de l’attaquant et des vulnérabilités découvertes lors de l’investigation.
- Phase 2 : l’attaquant arme sa charge (e.g. il exploite une vulnérabilité connue du logiciel Adobe Reader et installe un cheval de Troie dans un document PDF).
- Phase 3 : l’attaquant dirige sa charge vers sa victime (e.g. il envoie un fichier infecté joint à un e-mail).
- Phase 4 : l’attaquant infecte la machine de la victime (e.g. le code malveillant s’auto-exécute à l’ouverture du fichier par la victime).
- Phase 5 : l’attaquant établit un canal de communication avec la machine compromise et accède à son environnement (e.g. il télécharge de nouveaux outils, élève ses privilèges, écoute le trafic réseau, se déplace de machine en machine, etc.).
- Phase 6 : l’attaquant collecte et chiffre les données avant de les transférer vers un hôte distant.
En général, les systèmes de détection d'intrusion se focalisent sur une ou deux étapes de la chaîne : la détection des événements dans la phase d'exploitation (identifier un shellcode connu ou la signature d'un fichier binaire) ou C&C. C’est alors à l’administrateur de sécurité qu’incombe l’identification de la stratégie d’attaque à partir de l’ensemble des alertes. L’approche décrite par Michael J. Cloppert, consiste à recouper les événements de sécurité dans un contexte d'analyse globale et prédictive de l'attaque. Plutôt que de focaliser notre attention sur des événements de sécurité réseau ou système pris isolément, il est préférable de corréler les alertes et les événements associés selon des vecteurs d'attaque (ou méthodes utilisées par l’attaquant pour atteindre ses objectifs [14]). Par ailleurs, certains événements seront filtrés et pourront être ignorés s’ils n'apportent aucune valeur à la chaîne. Prenons l’exemple d’un anti-virus qui remonte une alarme et détecte (phase 4) un code malveillant dans une pièce jointe d’un courrier électronique. Non seulement, cet événement va permettre de reconstituer une session complète d’attaque, mais corrélé avec d’autres événements de même nature à des temps différés, il peut être l’indicateur d’une attaque persistante.
Qu’il s’agisse d'une analyse différée de l'attaque (analyse post-mortem ou approche forensique dans le cadre d’enquêtes après incident) ou en temps réel (approche proactive et réactive), les techniques de corrélation d’alertes appliquées à la détection d’intrusion optimisent le traitement des alertes et améliorent considérablement l’efficacité des détections. Toutefois, il est important de souligner que l’administrateur de sécurité aura toujours à effectuer un travail manuel de qualification et de recoupement des alertes avec comme seuls indicateurs, les attributs de l’alerte, le succès ou l’échec de l’attaque référencée par l’alerte et le niveau de sévérité affiché sur son tableau de bord (fonction de la vulnérabilité exploitée et de son système d'évaluation CVSS [15]) et qualifié au niveau d’une base de connaissance.
3. Un cadre opérationnel et organisationnel
3.1 Étude et choix d’une solution de détection d’intrusion
Concernant la source de données, la première chose à considérer lors de l’étude d'une solution de détection d'intrusion est le choix d'une sonde de détection : HIDS et NIDS (Network-based Intrusion Detection System). L'évaluation des sondes pourra s'appuyer sur une grille de notation intégrant les critères suivants :
- Méthodes et capacités de détection ;
- Performance en conditions de charge élevées;
- Résistance aux techniques d'évasion ;
- Exploitation des données à traiter ;
- Ergonomie des interfaces d’administration et d’exploitation ;
- Coûts de la solution.
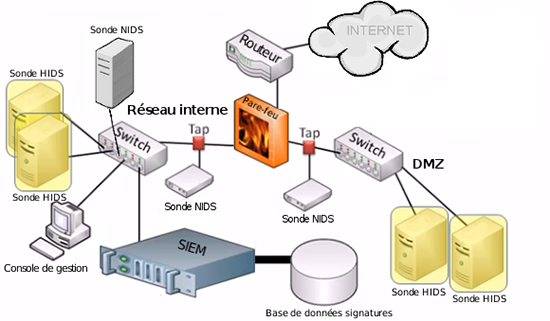
Un HIDS aura un impact sur le serveur en termes de performance, car il va consommer une partie des ressources de ce serveur. Concernant l'installation d'un ou plusieurs NIDS, il faudra tenir compte de la disponibilité de points de raccordements permettant d'écouter le réseau. Le positionnement d’une sonde de détection dépend des contraintes propres à l’architecture. À l’extérieur du pare-feu (côté WAN), la sonde NIDS est plus proche des attaquants, mais va lever un volume important d’alertes en raison d’attaques classiques (e.g. balayage de port) qui seront très certainement bloquées par le pare-feu. Une sonde NIDS à l’intérieur d’un pare-feu (côté LAN), sera moins exposée aux bruits de fond résiduels et aux faux-positifs qui en résultent.
Par ailleurs, il peut être nécessaire de configurer la sonde NIDS avec deux interfaces réseaux. La première effectuera une surveillance en mode « promiscuous ». Dans ce mode, on capture tous les paquets qui passent par le lien réseau, qu’ils soient ou non adressés à la sonde. La seconde sera placée sur un VLAN (Virtual Local Area Network) dédié pour communiquer avec le système de gestion des événements et la console de gestion. En ce qui concerne les sondes HIDS, elles devront être déployées sur les serveurs critiques.
La figure 8 schématise une architecture classique et les différents emplacements possibles des sondes de détection.
3.2 Les défis liés à la détection d’intrusion
La sécurité de l’information ne se limite plus à une approche purement technique. Aujourd’hui, certaines entreprises ont conscience que quelques briques technologiques, logicielles ou matérielles, ne suffisent plus à protéger leurs informations critiques. Désormais, ces entreprises s’orientent vers le management de la sécurité, dans une approche globale, aussi bien organisationnelle, technologique que juridique.
L'étude du cabinet d'audit PriceWaterhouseCoopers auprès de 3 877 entreprises dans 78 pays « fait ressortir que plus d’une entreprise sur deux déclare que le Directeur des Systèmes d’Information est, in fine, propriétaire des risques de cybercriminalité. Seulement, une entreprise sur cinq (5 % en France) déclare ainsi que cette responsabilité est, in fine, du ressort de la Direction Générale ou du Conseil d’Administration » [16]. Or, un facteur déterminant dans la réussite d’un projet de sécurité de l’information, s’intégrant ou non dans un système de gestion de la sécurité de l'information (ISMS ou Information Security Management System), est l’engagement réel et affiché de la structure dirigeante et des managers intermédiaires de l’organisation.
La prise en compte de la gestion des risques au sein du SI permet de considérer la sécurité de l’information comme un processus métier transverse et une réelle composante de la stratégie d'entreprise.
Ainsi, un projet de détection des intrusions qui s’inscrit dans un contexte de gestion des risques, dépasse la seule compétence des équipes techniques, du RSSI.
Le processus de la gestion des risques de sécurité des SI peut être résumé en six phases principales :
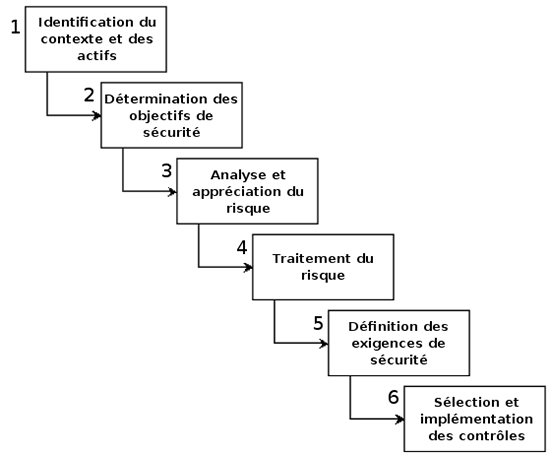
Les trois premières phases conduisent à identifier, analyser et apprécier les risques de sécurité.
En phase 4, nous pouvons les accepter et ne rien faire, ou les transférer en externalisant une activité par exemple, voire les réduire en agissant sur leurs origines ou leurs conséquences.
En phase 5, des exigences de sécurité peuvent alors être déterminées afin de réduire le risque. Nous choisissons des mesures à mettre en œuvre pour atteindre ces objectifs de sécurité et elles vont être le fondement de la politique de sécurité. Par exemple, des contrôles techniques peuvent être choisis comme la détection des intrusions sur le réseau du SI.
Un système de détection d’intrusion qui s’inscrit dans ce contexte de gestion du risque, devra être perçu et accompagné par des moyens humains et financiers nécessaires à sa mise en œuvre.
En premier lieu, l’approche purement financière dans le choix de la conduite ou non d’un projet de détection des intrusions est un élément déterminant. Beaucoup de projets n’aboutissent pas, car aucune évaluation du retour sur investissement en sécurité informatique (ROSI ou Return On Security Investment) par les DSI ou les RSSI n’est réalisée. Selon les secteurs d’activités, la ligne budgétaire consacrée à la sécurité de l’information est assimilée à un centre de coût et non de profit. Dans un second lieu, l’approche « évaluation des risques » moins financière et plus qualitative est un argument important, mais non suffisant. La mise en place de solutions de détection des intrusions doit s’accompagner d’une évaluation du ROSI.
Le CLUSIF propose un état de l'art [17] autour d’un modèle de coût et de la notion de ROSI. Mais il n'y a pas de consensus clair autour de la définition de ROSI. La définition orientée incidents de sécurité est celle que nous retiendrons.
Toute la difficulté est de pouvoir estimer la valeur exacte de chaque incident de sécurité lié à une intrusion et sa probabilité d'occurrence. La réalisation préalable d'une analyse des risques de sécurité des systèmes d'information facilitera ce travail, car elle intègre une évaluation des actifs du SI, du facteur d’exposition du système (EF ou Exposure Factor) et des vulnérabilités d’une infrastructure globale pouvant être exploitées par une ou plusieurs menaces connues ou inconnues.
Enfin, réagir de manière appropriée à une intrusion est surtout une question d’organisation et de procédures qui doivent être définies et appliquées par les équipes informatiques en réponse aux incidents.
Comment traiter l’alerte, comprendre l’incident et le clôturer ? Quelles sont les mesures conservatoires à prendre ? Qui alerter (le responsable sécurité, le CERT, la direction métier, la direction générale, la gendarmerie, etc.) ?
Les activités relatives à la détection d’intrusion doivent s’appuyer sur des actions précises et des rôles alloués à chacun, des outils dont l’informaticien a besoin et les résultats qu’il doit produire sous conditions de présentation, de contraintes de réactivité ou d’astreinte.
Les éléments collectés lors de la phase de détection et la qualification de l’intrusion ne suffisent pas eux seuls. Il est également nécessaire d'évaluer une stratégie de réponse en fonction de la criticité du système compromis et de l'impact d'une interruption de service du système.
- activation d’une cellule de crise ;
- délai de remise en production ;
- implication des relations publiques et communication appropriée ;
- volonté de répondre à une attaque ;
- volonté de poursuivre légalement l'attaquant.
Conclusion
En conclusion de cet article, nous avons vu que la surface d’attaque du système d'information des organisations pour les cybercriminels pouvait être importante. Le Code pénal français offre aujourd'hui des dispositions juridiques pour lutter contre les intrusions dans un STAD, mais qui peinent à être mises en œuvre lorsque l'investigation dépasse nos frontières. Une coopération internationale est nécessaire. L'impact en termes de perte de données ou de notoriété peut être considérable pour ces organisations. Aussi, la prolifération de ces nouvelles menaces et les limites de la sécurité périmétrique (pare-feux majoritairement pour ne pas dire exclusivement mis en œuvre pour la protection des infrastructures réseau) à pouvoir y répondre, conduisent les organisations à s'intéresser aux technologies de détection d'intrusion.
La problématique de la détection d'intrusion est souvent vue comme l'association de trois ou quatre événements sur une fenêtre de temps très courte et à partir d’une source unique, mais c'est bien plus que cela, et c'est de là qu'en vient la difficulté, de par les contraintes que cela induit : périmètre à surveiller et criticité des ressources à protéger, architecture et positionnement des mécanismes de détection, nombre d'équipements qui remontent des événements, taille de la fenêtre de détection, capacité de recherche et de corrélation des logs (SIEM), efficacité des techniques de détection et identification de signaux faibles « noyés » dans un volume important de données (problématique Big Data), etc.
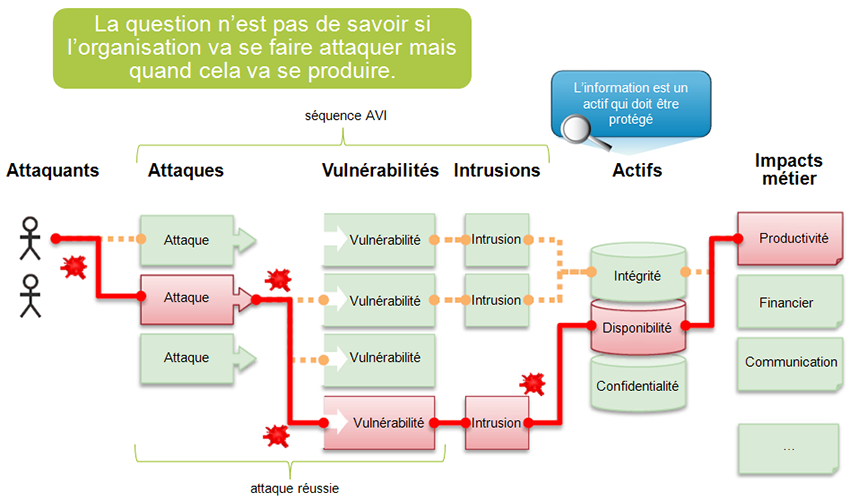
Enfin, la question n’est plus de savoir si l’organisation va se faire attaquer, mais quand cela va se produire. Bien que la détection d’intrusion repose sur des technologies, qui de surcroît évoluent, certains facteurs non techniques doivent également être pris en compte par une organisation souhaitant intégrer une solution de détection d’intrusion. La mise en place d’un système de détection d’intrusion est un projet structurant. Il est donc important d’évaluer les critères organisationnels et économiques avant d’étudier les critères techniques. De même que son inscription dans une politique globale de sécurité informatique et son intégration dans un processus de gestion des risques de sécurité des systèmes d’information conditionneront la réussite du projet.
Références
[1] ZONE-H. Disponible à l'adresse : http://www.zone-h.org/archive/filter=1
[2] OWASP Top 10-2013 rc1 « The Ten Most Critical Web Application Security Risks », 2013
[3] Base de données de vulnérabilités. [Consulté le 15 septembre 2013]. Disponible à l’adresse :
http://www.cvedetails.com/browse-by-date.php
[4] Anti-Phishing Working Group, « Rapport semestriel de l’APWG 2H2012 », avril 2013. Disponible à l’adresse :
http://docs.apwg.org/reports/APWG_GlobalPhishingSurvey_2H2012.pdf
[5] Prolexic, « Threat Advisory to Detail Massive DDoS Threat from itsoknoproblembro », 03 janvier 2013. Disponible à l’adresse :
http://www.prolexic.com/news-events-pr-threat-advisory-ddos-itsoknoproblembro.html
[6] Niels Provos, « Safe Browsing - Protecting Web Users for 5 Years and Counting », 19 juin 2012. Disponible à l'adresse :
http://googleonlinesecurity.blogspot.fr/2012/06/safe-browsing-protecting-web-users-for.html
[7] « Livre blanc - défense et sécurité nationale », http://www.sgdsn.gouv.fr/IMG/pdf/Livre-Blanc.pdf, 2013
[8] RSA FraudAction Research Labs, « Anatomy of an Attack », 01 janvier 2011. Disponible à l'adresse :
http://blogs.rsa.com/anatomy-of-an-attack/
[9] TGI Paris, 16 déc. 1997: Gaz. Pal. 1998. 2. Somm. 433, note Rojinsky.
[10] Hervé DEBAR, « Détection d’intrusions : corrélation d'alertes », 2004
[11] « Présentation de l'IDS/IPS Suricata », MISC 66, mars-avril 2013
[12] H. Debar, M. Dacier, A. Wespi, « Towards a taxonomy of intrusion-detection systems », Computers Networks, Volume 31, Issue 9, 1999, p. 809
[13] Suricata, to 10Gbps and beyond : http://home.regit.org/2012/07/suricata-to-10gbps-and-beyond/
[14] Simon Hansman, Ray Hunt, « A taxonomy of network and computer attacks », juin 2004, p. 6.
[15] http://www.cvedetails.com/cvss-score-charts.php
[16] PriceWaterhouseCoopers, « La fraude en entreprise : tendances et risques émergents », 6e édition Global Economic Crime Survey 2011
[17] CLUSIF, « Retour sur l'investissement en sécurité des SI : quelques clés pour argumenter », octobre 2004, p.9. Disponible à l’adresse : http://www.clusif.asso.fr/fr/production/ouvrages/pdf/RoSI.pdf