

La gestion des capabilities est un mécanisme de sécurité du noyau Linux concourant à assurer un confinement d’exécution des applications s’exécutant sur le système en affinant les possibilités d'appliquer le principe du moindre privilège.
1. Confinement d’exécution
Le confinement d’exécution désigne tous les mécanismes réduisant les privilèges d'un processus en activité sur le système. Cette réduction porte sur les différentes actions que peut réaliser le processus : entrées / sorties dans certaines portions du système de fichiers, envoi de signaux, passage d'une interface en mode promiscuous, etc. Le périmètre est assez large, c'est la raison pour laquelle le confinement d’exécution repose sur un ensemble de mécanismes divers. Nous allons en dresser un diaporama (non exhaustif) et essayer de situer ces mécanismes les uns par rapport aux autres en dépilant les couches une par une.
1.1 Séparation de privilèges
Les programmes historiques tels que le serveur de mail Sendmail se présentent sous la forme d'un exécutable unique. C'était quelque chose d'acceptable lorsque les actions réalisées par les programmes étaient assez simples. Au vu de la croissance des fonctionnalités au sein de ces applications, il est nécessaire de les éclater en sous-programmes travaillant de concert pour assurer le service. Ainsi, le serveur Postfix de génération postérieure à Sendmail décompose le service de transfert de mails en plusieurs petits programmes.
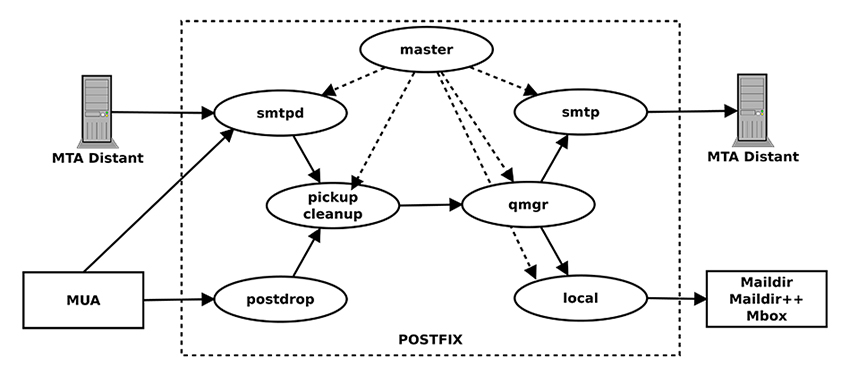
Dans la figure 1, nous voyons qu'un programme « master » (s’exécutant en root) exécute plein de petits sous-programmes concourant tous à la gestion du transfert de mails. Prenons le cas d'un mail traversant notre service Postfix (s'il est utilisé, par exemple, comme filtre antispam). Le service va recevoir une connexion SMTP sur le port 25 TCP. Le processus « master » va invoquer le processus smtpd pour gérer la socket TCP. Une fois que les données sont reçues, « master » invoque « pickup » pour mettre le message en file d'attente de traitement. Ensuite « master » appelle « qmgr » pour traiter le message. Enfin « master » invoque « smtp » qui va réaliser une connexion TCP sur le port 25 du serveur mail de destination. Au niveau développement, ce type d'architecture produit un code court pour chaque fonction, l'audit est facilité. Combiné avec le principe du moindre privilège, la séparation de privilèges augmente considérablement la sécurité des applications.
1.2 Moindre privilège
Une fois les fonctionnalités éclatées en sous-programmes, l'idée du moindre privilège est de donner à chacun d'eux uniquement les droits dont il a besoin. Le principe est simple, la réalisation autrement plus compliquée. Une grande diversité de mécanismes existe pour appliquer ce principe. Dans notre exemple basé sur Postfix, lorsque « master » invoque smtpd il commence par accomplir toutes les actions réalisables uniquement par root : ouvrir une socket sur un port privilégié, éventuellement se chrooter, etc. Ensuite il réalise un setuid pour emprunter une identité d’exécution moins privilégiée sur le système. Ce cheminement est un schéma assez classique de l'application du moindre privilège pour une application donnée. Nous allons voir que d'autres mécanismes que le changement d'identité peuvent être utilisés.
2. Le contrôle d'accès sous Linux
Le contrôle d'accès, autrefois très simple (car basé sur un tuple <utilisateur,permission,objet>), s'est complexifié sur les systèmes actuels. Ce modèle a évolué vers des politiques plus complètes disposant de permissions beaucoup plus fines. Certains systèmes de contrôle d'accès peuvent descendre jusqu'à la granularité de l'appel système. La surface de code de ces systèmes et leur nombre croissant ont entraîné la création d'une couche modulaire dédiée à la sécurité du contrôle d'accès : les LSM (Linux Security Modules) [LSM]. Les LSM implémentent des hooks dans les fonctions standards du noyau. Toutes les actions résultantes des appels à ces fonctions sont donc interceptées par les modules constituant la chaîne LSM. On notera que les capabilities sont maintenant implémentées comme un module LSM.
2.1 DAC
Le contrôle d'accès sous Linux est, par défaut, de type DAC : Discretionnary Access Control, ou contrôle d'accès discrétionnaire. Cela signifie que les droits sur un objet sont laissés à la discrétion du propriétaire de l'objet. Si vous êtes propriétaire d'un fichier, vous pouvez fixer n'importe quels droits dessus. Cette approche a comme principal problème que la politique de sécurité évolue en fonction des utilisateurs. Elle est donc dans un état non déterminable par l'administrateur du système. De plus, l'implémentation du DAC sous Linux se résume essentiellement à placer des droits sur des fichiers. Enfin, comme tout est fichier, le spectre est finalement assez large. Dans ce modèle, l'utilisateur root outrepasse tout le contrôle d'accès.
2.2 MAC
Le MAC : Mandatory Access Control, ou contrôle d'accès mandataire est également disponible sous Linux. Ce type de contrôle d'accès définit une politique de sécurité pour le système à laquelle même root doit se soumettre. L'implémentation la plus connue du MAC sous Linux est SELinux (Security Enhanced Linux) [SELinux] basé sur l'architecture flask [FLASK]. Cette implémentation supporte le modèle de sécurité TE (Type Enforcement) [TE]. Le TE consiste à labelliser le système. Chaque entité du système se voit attribuer un label. Ensuite, il faut fournir une politique de sécurité définissant les actions autorisées entre les labels. Ce qui n'est pas autorisé explicitement par la politique est interdit. Ici, on voit que la granularité est beaucoup plus fine qu'avec le DAC. Par exemple, tous les processus peuvent écrire dans /tmp. Si une politique TE est fournie pour le programme et qu'elle n'autorise pas l'écriture dans /tmp, l'opération sera refusée par la couche SELinux et l'écriture échouera. La complexité d'administration de la politique de sécurité est proportionnelle à la finesse de la granularité de la protection.
Le modèle de sécurité le plus populaire est le TE, mais il en existe d'autres tels que BellLapudala [BL] et son évolution Biba [Biba] qui traitent essentiellement de la confidentialité et de l'intégrité grâce à une politique très simple (sur le papier) : « no write up and no read down » pour Biba (intégrité) et « no write down and no read up » pour BellLapudala (confidentialité).
Dans le modèle MAC, même root est soumis au contrôle d'accès. Le leitmotiv de SELinux est « confining the omnipotent root ». Il faut bien comprendre qu'avec ce modèle, root est obligé de suivre une politique de sécurité. C'est un modèle qui impose des contraintes.
3.3 Et sinon ?
Nous avons vu que le DAC se heurte à certaines limites en termes de sécurité et que le MAC était assez compliqué à gérer. Donc niveau moindre privilège simple à mettre en œuvre, n'existe-t-il rien de mieux que le classique chroot -> setuid avec des permissions restreintes sur le système de fichiers ? Hé bien si, sous Linux il existe une possibilité assez méconnue consistant à manipuler les capabilities des processus. Prenons par exemple un service tournant sous l'identité root. Dans une configuration courante, il s’exécute avec des droits illimités sur le système. Dans une configuration DAC, il est tout à fait permis au service de changer les droits sur les fichiers du système, de changer d'identité, de créer des utilisateurs, etc. L'idée de SELinux (et de toutes les autres implémentations du MAC que l'on peut trouver dans le noyau Linux) est de le contraindre à suivre une politique. L'approche des capabilities est différente : on juge que le programme s’exécutant avec les droits root est responsable et qu'il abandonne les privilèges dont il n'a pas besoin pour prévenir une escalade de privilèges en cas d'exploitation. Si on va jusqu'au bout du raisonnement, on peut utiliser les capabilities pour faire tourner un programme root avec une identité banalisée en ajoutant à cette identité quelques privilèges normalement réservés à l'administrateur.
4. Les capabilities
Les capabilities sont intégrées aux LSM (Linux Security Modules). Chaque opération privilégiée est associée à une capability. Par exemple, l'appel système setuid ne peut être réalisé que par des processus disposant de la capability cap_setuid. Ces capabilities sont réparties en trois sets (ou ensembles) : « effective », « permitted » et « Inheritable ». Lorsqu'un processus a une capability dans les sets « effective » et « permitted » il peut l’utiliser. Par exemple, si un processus dispose de la capability cap_setuid dans ces deux sets, il peut alors invoquer l'appel système setuid. Définition des trois sets :
- Permitted : contient les capabilities permises (mais pas nécessairement utilisées) pour un processus. Une capability doit ABSOLUMENT être présente dans ce set pour pouvoir être utilisée. Les capabilities de ce set peuvent aussi être ajoutées au set « Inheritable » par les processus ne disposant pas de la capability CAP_SETCAP. Ceux qui la possèdent ne sont pas soumis à cette restriction ;
- Effective : contient les capabilities autorisées par le noyau pour le processus ;
- Inheritable : contient l'ensemble des capabilities conservées lors d'un appel à execve (recouvrement de l'espace mémoire d'un processus par un autre). Les capabilities de ce set peuvent être passées au set « Permitted » du programme appelé.
Cependant, l'utilisation des capabilities ne se limite pas aux processus. Elles se placent également sur les fichiers exécutables. Chaque exécutable possède également les trois sets sus-nommés. Ils sont évalués avec ceux du processus l'invoquant, via un execve, pour déduire le contenu des sets du processus résultant. Les règles sont les suivantes pour calculer les trois sets du processus résultant :
- Permitted : ces capabilities sont automatiquement ajoutées dans le set « Permitted » du processus résultant. Peu importe le contenu du set « Inheritable » du processus ayant invoqué l'execve ;
- Inheritable : un ET logique est réalisé entre le contenu de ce set et le set « Inheritable » du processus à l'origine du execve. Le résultat est ajouté au set « Permitted » du processus résultant ;
- Effective : en fait, il s'agit plutôt d'un flag que l'on positionne sur chaque capability. Si on ajoute une capability dans ce set, cela veut dire que si elle est également présente dans le set « Permitted » calculé pour le processus résultant alors elle se retrouve également dans son set « Effective ».
Voila pour les règles de fonctionnement des capabilities, nous allons voir comment cela fonctionne côté utilisateur et côté noyau.
4.1 Niveau utilisateur
Au niveau utilisateur (enfin plutôt administrateur système), on va surtout manipuler les capabilities sur les fichiers. C'est-à-dire que l'on va donner quelques privilèges à un exécutable afin qu'il ne tourne pas avec l'identité root. De manière classique pour que les utilisateurs puissent exécuter un programme nécessitant des droits root, on peut lui positionner le bit SUID. Ce bit particulier exécute le programme avec les droits du possesseur de l’exécutable et non ceux du lanceur. Un exemple typique est ping :
root@capng:/testcap# ls -al /bin/ping
-rwsr-xr-x 1 root root 36136 avril 12 2011 /bin/ping
Le SUID est identifié par le bit « s » mis en évidence dans la sortie de ls. Supprimons-le :
root@capng:/testcap# chmod u-s /bin/ping
root@capng:/testcap# ls -al /bin/ping
-rwxr-xr-x 1 root root 36136 avril 12 2011 /bin/ping
Testons en tant que l'utilisateur « toto » :
toto@capng:/testcap$ ping www.google.fr
ping: icmp open socket: Operation not permitted
Nous pouvons ajouter la capacité cap_net_raw dans les sets « permitted » et « effective » (pe) du fichier exécutable ping. Cet ajout se fait avec la commande setcap (getcap pour afficher les capabilities d'un exécutable) :
root@capng:/testcap# setcap cap_net_raw=pe /bin/ping
root@capng:/testcap# getcap /bin/ping
/bin/ping = cap_net_raw+ep
Testons à nouveau en tant que l'utilisateur « toto » :
toto@capng:~$ ping -c 1 www.google.fr
PING www.google.fr (173.194.40.152) 56(84) bytes of data.
64 bytes from par10s10-in-f24.1e100.net (173.194.40.152): icmp_req=1 ttl=63 time=1.83 ms
--- www.google.fr ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 1.838/1.838/1.838/0.000 ms
Ça marche ! Le souci est que la capability cap_net_raw de ping est appliquée pour tous les utilisateurs. D'après les règles de transitions vues en introduction, nous avons placé la capability dans le set « Permitted » et nous l'avons activée dans le set « Effective ». Ainsi, quelles que soient les capabilities du processus appelant, ping s’exécutera avec cette capability dans son set « Effective ».
On pourrait vouloir restreindre cela à certains utilisateurs. C'est tout à fait possible en plaçant des capabilities à activer pour un utilisateur donné dans le set « Inheritable » du processus de son shell. Voyons ce qu'il en est par défaut pour « toto » :
toto@capng:~$ /sbin/getpcaps $$
Capabilities for `2630': =
La commande getpcaps suivie du PID affiche les capabilities du processus attaché au PID. La variable $$ renvoie le PID du shell en cours d'exécution. L'astuce pour donner des capabilities au shell d'un utilisateur est d'utiliser un (Pluggable Authentication Modules) PAM, le pam_cap. Les PAM s’exécutant en root, il est tout à fait possible de placer des capabilities sur le shell qui est invoqué à la connexion. Il faut juste ajouter une entrée au fichier /etc/security/capability.conf :
cap_net_raw toto
none *
Ici, on ajoute la capability cap_net_raw au set « Inheritable » du shell de l'utilisateur toto. Vérifions au login :
toto@capng:~$ /sbin/getpcaps $$
Capabilities for `2651': = cap_net_raw+i
Modifions les capabilities positionnées sur ping :
root@capng:/testcap# setcap cap_net_raw=ie /bin/ping
root@capng:/testcap# getcap /bin/ping
/bin/ping = cap_net_raw+ei
Testons avec « toto » :
toto@capng:~$ ping -c 1 www.google.fr
PING www.google.fr (173.194.40.152) 56(84) bytes of data.
64 bytes from par10s10-in-f24.1e100.net (173.194.40.152): icmp_req=1 ttl=63 time=2.28 ms
--- www.google.fr ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 2.280/2.280/2.280/0.000 ms
Et avec « titi » :
titi@capng:~$ /sbin/getpcaps $$
Capabilities for `2674': =
titi@capng:~$ ping -c 1 www.google.fr
ping: icmp open socket: Operation not permitted
L'utilisateur toto a la capability cap_net_raw dans le set « Inheritable » de son shell (qui est le processus réalisant le fork -> execve du ping). On l'a également positionné sur le set « Inheritable » du fichier exécutable. Le résultat du ET logique l'ajoute donc dans le set « Permitted » du processus résultant. Or, sur l'exécutable, le flag du set « Effective » est activé pour cette capability. Elle est donc ajoutée dans le set « Effective » du processus résultant. Victoire !
Avec un utilitaire comme ping, cela peut paraître bien accessoire. Il est utilisé depuis des années, n'a pas une surface de code monstrueuse et n'offre pas beaucoup de biais à l'utilisateur. Par contre, avec un programme comme nmap qui nécessite des droits root pour faire de l'OS fingerprinting (reconnaissance de système d'exploitation grâce aux spécificités de la pile réseau cible) c'est plus intéressant. Nmap dispose de tout un système de plugins avec un langage particulier. La surface de code est donc beaucoup plus conséquente [nmap].
4.2 Niveau noyau
Pour le noyau, les capabilities sont attachées à deux objets : les tâches (tasks, processus) et les fichiers. Un set de capabilities est représenté de la manière suivante (linux/capability.h) :
typedef struct kernel_cap_struct {
__u32 cap[_KERNEL_CAPABILITY_U32S];
} kernel_cap_t;
Avec la variable _KERNEL_CAPABILITY_U32S définie à 1 ou 2 selon que le nombre de capabilities disponible est inférieur ou supérieur à 32. Pour les processus, cette structure est utilisée dans la structure cred (linux/cred.h). Cette structure représente le contexte de sécurité d'un processus en cours d'exécution.
struct cred {
[...]
kernel_cap_t cap_Inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
[...]
}
On retrouve bien les trois vecteurs « Inheritable », « Permitted » et « Effective » plus un quatrième « Bounding » dont nous reparlerons un peu plus tard. Cette structure est bien rattachée à la structure task_struct qui représente une tâche (processus) en cours d’exécution (sched.h) :
struct task_struct {
[...]
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
[...]
}
Nous avons deux pointeurs sur la structure cred. Le premier (real_cred) est utilisé par le processus lorsqu'un autre processus essaye d’interagir avec lui. Le second (cred), lorsque le processus essaye d'agir sur un autre. Sauf cas particulier, les deux pointeurs pointent sur la même instance de la structure cred. En fait, c'est l'histoire du RUID (Real UID) et de l'EUID (Effective UID).
Pour les fichiers, la commande setcap fait appel au syscall setxattr :
root@capng:/testcap~# strace -e setxattr setcap cap_net_raw=ei /bin/ping
setxattr("/bin/ping", "security.capability", "\x01\x00\x00\x02\x00\x00\x00\x00\x00 \x00\x00\x00\x00\x00\x00\x00\x00\x00", 20, 0) = 0
Les attributs étendus (xattr, eXtended ATTRibutes) sont des métadonnées non interprétées par le système de fichiers. Ici, ils vont être utilisés pour stocker les structures kernel_cap_t associées aux fichiers. Le prototype de la fonction est (fs/xattr.c) :
setxattr(struct dentry *d, const char __user *name, const void __user *value, size_t size, int flags)
En argument, on a un objet dentry. La structure dentry correspond à un cache au niveau de VFS (Virtual FileSystem).
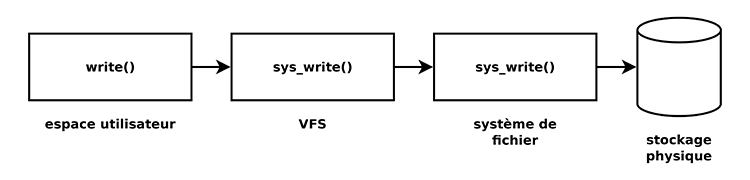
C'est une structure qui correspond à une projection en mémoire vive des différents composants du chemin sur lequel on travaille. Ici, il s'agit du fichier /bin/ping. Nous avons donc trois composants dentry : / et bin qui sont des répertoires et ping qui est un fichier exécutable. L’intérêt de cette structure est d'avoir un cache en mémoire pour toutes les opérations telles que l'évaluation d'un chemin qui sont coûteuses en opérations d'entrées-sorties sur le disque. Le second argument donne le type de métadonnées. La troisième valeur représente les capabilities en mode brut. Cet appel système utilise la fonction vfs_setxattr :
vfs_setxattr(struct dentry *dentry, const char *name, const void *value, size_t size, int flags)
Qui appelle la fonction security_inode_setxattr (security/security.c) :
security_inode_setxattr(struct dentry *dentry, const char *name, const void *value, size_t size, int flags)
Nous sommes arrivés au hook LSM qui va juste tester si l'opération d'ajout de la capbility est permise. Si oui, la fonction vfs_setxattr continue son exécution et entre dans la fonction __vfs_setxattr_noperm. Cette fonction résout l'inode par rapport à la dentry pour ajouter les capabilities au fichier. Les capabilities sont donc liées à l'inode.
Lorsque le système va exécuter un fichier via un appel à execve, c'est la fonction do_common_execve qui est appelée (fs/exec.c) :
do_execve_common(const char *filename, struct user_arg_ptr argv, struct user_arg_ptr envp)
Cette fonction appelle prepare_binprm qui traduit les métadonnées associées à l'inode en structure linux_binprm (linux/binfmts.h). Cette structure contient la structure cred qui elle-même contient les capabilities.
5. Programmation
Nous allons mettre en application toutes les notions vues sur les capabilities en utilisant la librairie libcap-ng et ses bindings python pour réaliser un script father qui va exécuter un script child. L'idée est que father tourne avec l'identité root et se contente de lancer child avec le minimum de privilèges sur le système. Ici, child va juste ouvrir un raw socket, éventuellement pour envoyer une requête ICMP afin de vérifier la disponibilité d'un hôte.
5.1 Hello world
Commençons par un programme simple. Il se contente de retourner l'identité sous laquelle il s’exécute, puis les capabilities dont dispose le processus. Pour la suite des exemples, nous prendrons comme convention que « all » dans les affichages renvoie au jeu complet de capabilities, c'est-à-dire chown, dac_override, dac_read_search, fowner, fsetid, kill, setgid, setuid, setpcap, linux_immutable, net_bind_service, net_broadcast, net_admin, net_raw, ipc_lock, ipc_owner, sys_module, sys_rawio, sys_chroot, sys_ptrace, sys_psacct, sys_admin, sys_boot, sys_nice, sys_resource, sys_time, sys_tty_config, mknod, lease, audit_write, audit_control, setfcap, mac_override, mac_admin, syslog, wake_alarm.
root@capng:/testcap# python hello.py
UID : 0 EUID 0
== Effective ==
all
== Permitted ==
all
== Inheritable ==
none
== Bounding set ==
all
On constate que le programme s’exécute sous l'identité root, qu'il dispose de toutes les capabilities (permitted = all), qu'il les utilise (effective = all) et qu'après un execve, le processus résultant n'héritera de rien (Inheritable = none) dans son set « Permitted ». Par contre, il pourrait ajouter toutes les capabilities au set Inheritable (bounding = all).
Un ET logique est réalisé en le set « Bounding » du processus appelant l'execve et le set « Permitted » du fichier exécutable. Le résultat est ajouté au set « Permitted » du processus résultant. Cela ajoute une contrainte sur les capabilities situées dans le set « Permitted » de l’exécutable. Par extension, c'est une limite sur les capabilities utilisables par un exécutable après son invocation via execve.
Voyons le code de cet exemple :
#!/usr/bin/python
import os
import capng
def printcap ():
print "== Effective =="
capng.capng_print_caps_text(capng.CAPNG_PRINT_STDOUT, capng.CAPNG_EFFECTIVE)
print "\n"
print "== Permitted =="
capng.capng_print_caps_text(capng.CAPNG_PRINT_STDOUT, capng.CAPNG_PERMITTED)
print "\n"
print "== Inheritable =="
capng.capng_print_caps_text(capng.CAPNG_PRINT_STDOUT, capng.CAPNG_INHERITABLE)
print "\n"
print "== Bounding set =="
capng.capng_print_caps_text(capng.CAPNG_PRINT_STDOUT, capng.CAPNG_BOUNDING_SET)
def main():
print "UID : " + str(os.getuid()) + " EUID " + str(os.geteuid())
print "\n"
proc_caps = capng.capng_get_caps_process()
printcap()
print "\n"
if __name__ == "__main__" :
main()
Les primitives pour manipuler les capabilities du processus sont situées dans un module capng. Une fois ce module chargé, il faut utiliser la fonction capng_get_caps_process() pour récupérer les quatre sets de capabilities (effective, permitted, inheritable et bounding). Enfin, la fonction printcap() produit un affichage pour chacun des sets en s'appuyant sur la fonction capng_print_caps_text(). Relançons-le en utilisateur non privilégié :
toto@capng:/testcap$ python hello.py
UID : 1000 EUID 1000
== Effective ==
none
== Permitted ==
none
== Inheritable ==
none
== Bounding set ==
all
Maintenant, à part dans le set bounding, il n'y a plus aucune capabilities sur le processus. Dans la suite, nous ne réécrirons pas le code de la fonction printcap, nous ne donnerons que les portions de code pertinentes.
5.2 Le programme « child »
Le programme child affiche l'identité sous laquelle il fonctionne, ses quatre sets de capabilities et tente d'ouvrir une socket en mode raw. Voyons le code source :
#!/usr/bin/python
import os
import capng
import socket
import sys
def openrawsock ():
try:
s = socket.socket(socket.AF_PACKET, socket.SOCK_RAW)
except socket.error as msg:
s = None
print msg
if s is not None:
print "Socket OK"
s.close()
else:
print "Socket Error"
sys.exit(1)
def main():
print "UID : " + str(os.getuid()) + " EUID " + str(os.geteuid())
print "\n"
proc_caps = capng.capng_get_caps_process()
printcap()
print "\n"
openrawsock()
sys.exit(0)
if __name__ == "__main__" :
main()
Finalement, c'est le même programme que précédemment, on lui ajoute juste une fonction openrawsock qui ouvre une socket en mode raw. Exécutons-le en root :
root@capng:/testcap# python child.py
UID : 0 EUID 0
== Effective ==
all
== Permitted ==
all
== Inheritable ==
none
== Bounding set ==
all
Socket OK
La socket s'est bien ouverte. Lançons-le maintenant en utilisateur lambda :
toto@capng:/testcap$ python child.py
UID : 1000 EUID 1000
== Effective ==
none
== Permitted ==
none
== Inheritable ==
none
== Bounding set ==
all
[Errno 1] Operation not permitted
Socket Error
Il n'y a aucune capabilities de positionnée et le programme ne fonctionne pas. En effet, ici le processus python n'a pas la capability net_raw nécessaire.
5.3 Le programme « father » version 1.0
Le premier programme master va abandonner ses capabilities non nécessaires, changer d'identité et faire un execve du programme child. Ce programme pourrait simuler un wrapper lançant un programme, normalement root, sous une identité banalisée tout en conservant la capability dont il a besoin. Pour voir comment abandonner des capabilities, nous allons travailler sur une version modifiée du programme « hello » :
def main():
unpriv_user="toto"
print "UID : " + str(os.getuid()) + " EUID " + str(os.geteuid())
proc_caps = capng.capng_get_caps_process()
printcap()
print "\n"
print "|== Father drop & setuid ==|"
print "\n"
capng.capng_clear(capng.CAPNG_SELECT_BOTH)
capng.capng_update(capng.CAPNG_ADD, capng.CAPNG_INHERITABLE, capng.CAP_NET_RAW)
if capng.capng_change_id(pwd.getpwnam(unpriv_user).pw_uid, pwd.getpwnam(unpriv_user).pw_gid, capng.CAPNG_DROP_SUPP_GRP | capng.CAPNG_CLEAR_BOUNDING) < 0:
print "loupe"
capng.capng_apply(capng.CAPNG_SELECT_BOTH)
print "\n"
printcap()
os.execve('/testcap/child.py',['/testcap/child.py'], os.environ)
Voyons le résultat :
root@capng:/testcap# python father.py
UID : 0 EUID 0
== Effective ==
all
== Permitted ==
all
== Inheritable ==
none
== Bounding set ==
all
|== Father drop & setuid ==|
== Effective ==
none
== Permitted ==
none
== Inheritable ==
net_raw
== Bounding set ==
|== Child execution == |
UID : 1000 EUID 1000
== Effective ==
none
== Permitted ==
none
== Inheritable ==
net_raw
== Bounding set ==
net_raw[Errno 1] Operation not permitted
Socket Error
Le programme commence par vider ses sets de capabilities avec la fonction capng.clear(). Ensuite, il positionne la capacité net_raw dans son set « Inheritable » avec la fonction capng_update(). À ce moment-là, les capabilities ne sont pas encore actives pour le processus. Il faut utiliser la fonction capng_apply() pour les appliquer au processus en cours d’exécution. On notera que cette fonction nécessite d'avoir la capability setpcap dans le set « effective ». Le programme change ensuite d'identité. Pour réaliser cette action, il ne faut pas utiliser un setuid classique qui va vider les sets et supprimer toutes les capabilities actives (et donc nous empêcher de réaliser le capng_apply()). Il faut utiliser la fonction capng_change_id() qui réalise le changement d'identité sans nettoyer les capabilities du processus. Cependant, le programme child échoue. On constate que la capability net_raw n'est pas dans les sets « effective » et « permitted ». Il faut donc placer ces capabilities sur l’exécutable :
root@capng:/testcap# setcap cap_net_raw=ie /usr/bin/python2.7
Recommençons :
root@capng:/testcap# python father.py
[...]
|== Child execution ==|
UID : 1000 EUID 1000
== Effective ==
net_raw
== Permitted ==
net_raw
== Inheritable ==
net_raw
== Bounding set ==
none
Socket OK
On notera que le setcap a été fait sur l’exécutable python et non pas sur le script. Dans les langages de scripts, c'est l’interpréteur qui est l'exécutable, et non pas le script.
5.4 Le programme « father » version 2.0
Dans cette version, nous allons simuler un processus qui lance des programmes en série. L'idée va être d’implémenter un petit programme qui va créer un processus fils exécutant child, attendre la fin de ce processus fils et poursuivre son exécution (figure 3).
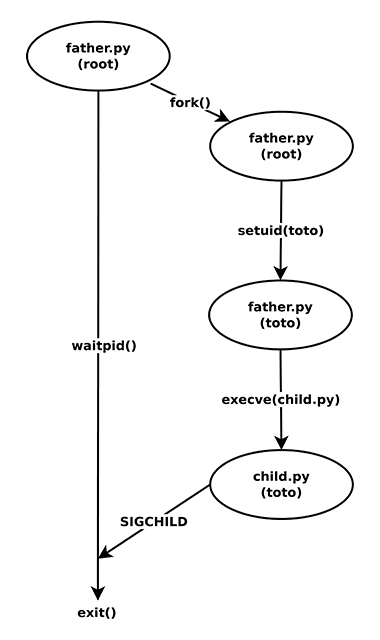
Évidemment, il ne faut pas toucher au programme child. En fait, cela va se résumer à un enchaînement fork() -> setuid() -> execve(). L’enchaînement setuid() -> execve() a déjà été traité précédemment. Voyons le code source :
def main():
pid = os.fork()
if pid:
os.waitpid(pid,0)
print "Father : keep on working ..."
else:
proc_caps = capng.capng_get_caps_process()
print "Child : Display initial capabilities"
printcap()
print "\n"
unpriv_user="toto"
print "Child : Dropping capabilities"
capng.capng_clear(capng.CAPNG_SELECT_BOTH)
capng.capng_update(capng.CAPNG_ADD, capng.CAPNG_INHERITABLE, capng.CAP_NET_RAW)
print "Child : SetUID -> toto"
if capng.capng_change_id(pwd.getpwnam(unpriv_user).pw_uid, pwd.getpwnam(unpriv_user).pw_gid, capng.CAPNG_DROP_SUPP_GRP | capng.CAPNG_CLEAR_BOUNDING) < 0:
print "SetUID failed"
print "Child : Applying capabilities sets"
capng.capng_apply(capng.CAPNG_SELECT_CAPS)
print "|-- Child printcap() before execve --|"
printcap()
print "\n"
os.execve('/testcap/child.py',['/testcap/child.py'], os.environ)
sys.exit(0)
Le programme appelle la fonction fork() qui crée un processus fils. Ce processus fils hérite des capabilities du père (ici, de toutes les capacités). Dans le branchement conditionnel du fils, on retrouve un code quasi similaire à celui du 5.3 : il s'agit d'un enchaînement setuid() -> execve(). Exécutons-le :
root@capng:/testcap# python father.py
Child : Display initial capabilities
== Effective ==
all
== Permitted ==
all
== Inheritable ==
none
== Bounding set ==
all
Child : Dropping capabilities
Child : SetUID -> toto
Child : Applying capabilities sets
|-- Child printcap() before execve --|
== Effective ==
none
== Permitted ==
none
== Inheritable ==
net_raw
== Bounding set ==
none
|== Child execution ==|
UID : 1000 EUID 1000
== Effective ==
net_raw
== Permitted ==
net_raw
== Inheritable ==
net_raw
== Bounding set ==
none
Socket OK
Father : keep on working ...
La différence est que le père attend le retour du fils pour continuer son exécution. Le fils s'exécute avec le minimum de privilèges. L'intérêt est que l'on pourrait enchaîner un second test au niveau du père en créant un autre processus qui abandonnerait son identité root pour nobody pour réaliser une connexion TCP sur le port 25 d'une machine afin de tester la disponibilité d'un service SMTP.
6. Conclusion
Les capabilities sont très intéressantes en matière de confinement d’exécution. Ce mécanisme basé sur la responsabilité de l'application d'abandonner tel ou tel droit doit cependant être manipulé avec précaution. Le premier problème est que les capabilities sur un fichier sont liées à l'inode. S'il y a un remplacement du fichier, elles sont perdues. Le second est que la charge au niveau de l'administration système est alourdie. Il faut définir des politiques au niveau des capabilities pour tous les cas d'utilisation des différents services. En effet, un même service au sens processus peut avoir des capabilities différentes en fonction de son utilisation. De la même manière que pour les politiques SELinux, le passage à l'échelle est compliqué. Il n'en reste pas moins que combinée à une implémentation réalisée avec le souci de la séparation de privilèges (donc avec un ensemble de capabilities facile à délimiter), leur utilisation rehausse grandement le niveau de sécurité du système. Merci à Gwendal pour les soucis de la vie courante en Python ;-)
Références
[LSM] Biondi, P., Raynal, F. (2008) Linux Security Modules (Linux Magazine HS 17).
[SELinux] Smalley, S., Vance, C., & Salamon, W. (2001). Implementing SELinux as a Linux security module (Vol. 1, p. 43). NAI Labs Report.
[FLASK] Lepreau, J., Spencer, R., Smalley, S., Loscocco, P., Hibler, M., & Andersen, D. (2006). The Flask Security Architecture: System Support for Diverse Security Policies.
[TE] Badger, L., Sterne, D. F., Sherman, D. L., Walker, K. M., & Haghighat, S. A. (1995, May). Practical domain and type enforcement for UNIX. In Security and Privacy, 1995. Proceedings., 1995 IEEE Symposium on (pp. 66-77). IEEE.
[Biba] Biba, K. J. (1977). Integrity considerations for secure computer systems (No. MTR-3153-REV-1). MITRE CORP BEDFORD MA.
[BL] Bell, D. E., & LaPadula, L. J. (1973). Secure computer systems: Mathematical foundations (No. MTR-2547-VOL-1). MITRE CORP BEDFORD MA.
[nmap] http://www.tolaris.com/2013/01/24/running-nmap-as-an-unprivileged-user/
http://www.tolaris.com/2013/01/24/running-nmap-as-an-unprivileged-user/
