

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Comment le Machine Learning peut-il apporter une réponse concrète à la falsification de l’information ? Cet article propose une initiation à la problématique, ainsi qu’une introduction à des méthodes et outils propres au traitement du langage naturel.
L’apparition d’Internet, couplée à la multiplication des terminaux de communication et notamment les téléphones portables ont modelé notre société de l’information. Dans notre poche, nous avons tous accès à une somme incommensurable de savoirs. De plus, l’actualité nous est fournie presque au moment même où elle se déroule, depuis une multitude de canaux. Nous consommons en permanence de l’information, ce qui transforme nos comportements : rares sont ceux qui prennent le temps désormais de lire un journal imprimé. En revanche, on voit fleurir de nouveaux formats, tels que des capsules d’« info-divertissement », sorte de vidéos courtes qui abordent des sujets souvent légers et qui inondent nos fils d’actualité sur les réseaux sociaux. On y retrouve également pléthore d’articles, partagés par des personnes que nous connaissons ou en qui nous avons confiance, ce qui leur confère une crédibilité supplémentaire quand bien même ils ne sont pas issus de canaux traditionnels des professionnels de l’information. Désormais, on ne dit plus « c’est vrai, je l’ai vu à la télé », mais « c’est vrai, je l’ai lu sur Internet ».
D’ailleurs, le travail de vérification de chacune des informations que l’on consomme, qui tiennent parfois de brèves de comptoir, est irréalisable : d’une part, il y en a beaucoup trop, et d’autre part il est coûteux pour chacune de trouver suffisamment de sources de vérité pour croiser l’information. C’est dans ce contexte qu’apparaissent les « fake news ». D’après le New York Times, les fake news sont des « histoires inventées avec l’intention d’induire en erreur, pour son propre intérêt » (citation exacte : « made up stories with an intention to deceive »). Même si le sujet défraie aujourd’hui la chronique, il est intéressant de noter que le concept avait été anticipé de longue date, et ce même avant la démocratisation d’Internet. En 1996, un magazine publiait un échange entre Terry Pratchett, génial écrivain britannique de fantasy humoristique, et Bill Gates. L’auteur notait que dans l’espace d’Internet, quiconque pouvait se forger une légitimité et publier du contenu volontairement faux. Bill Gates acquiesçait, mais précisait qu’à l’avenir, des « autorités du Net » se chargeraient de s'assurer de la véracité du contenu. Force est de constater que le milliardaire visionnaire s’est trompé. En effet, il a été estimé que les fake news seules ont généré des dégâts estimés à 13,4 millions d’euros pour la seule année 2021 [1]. Pourtant, cette information est complètement fausse, et inventée uniquement pour démontrer la facilité avec laquelle un discours peut se montrer faussement argumenté. Si ici l’enjeu n’est pas critique, on comprend aisément que lorsqu’il s’agit de politique, les conséquences peuvent être désastreuses.
Ainsi, à défaut d’« autorités du Net », les autorités françaises ont promulgué une loi en 2018 relative à la lutte contre la manipulation de l’information. Elle stipule notamment que les peines encourues pour le partage de fausses informations à trois mois d’une élection sont importantes. On peut s’interroger alors de l’efficacité d’une telle loi pour lutter contre la propagation des fake news : si les sanctions peuvent être dissuasives, elles ne sont que réaction à un problème qui a le temps de faire des ravages. Est-il donc possible de s’outiller pour essayer de détecter les fake news alors même que le contenu est édité ? Nous nous proposons dans le cadre de cet article d’explorer les leviers permis par la manipulation de données et l’apprentissage statistique.
1. État de l’art
Même si chacun se figure une interprétation de ce qu’est une fake news, le terme recèle de nombreuses subtilités qu’il conviendra d’aborder, avant de s’intéresser aux travaux déjà existants sur le sujet. D’ailleurs, on lui préférera le terme français d’infox, selon les recommandations de l’Académie française.
1.1 Un sujet d’actualité et d’importance
Les exemples réels de l’impact des infox sont nombreux : en 2008, après la publication d’un rapport fallacieux sur la liquidation de United Airlines, le cours de la compagnie aérienne a chuté de 76 % en quelques minutes, avec une clôture ce jour-là 11 % en dessous du jour précédent [2]. Lors des élections américaines de 2016, il est possible qu’un ensemble de twitts au contenu au mieux très partisan, au pire volontairement faux en faveur de Trump ou de Clinton, aient influencé le résultat des élections [3]. Si les infox s’immiscent dans le monde financier et dans le monde politique, il est indispensable de comprendre que les impacts les plus importants tiennent à l’intention de l’auteur. C’est pourquoi, pour une information fausse ou imprécise, mais sans mauvaise intention, on parlera plutôt de mésinformation. En revanche, si l’auteur cherche intentionnellement à tirer profit de l’infox, on parlera alors de désinformation. Dans ce spectre, on peut ajouter aussi la notion de rumeur : une information qui n’est pas encore confirmée ni infirmée, et dont le partage cherche simplement à créer la polémique, par exemple. Enfin, que dire de la satire : les informations sont volontairement fausses dans le but de faire rire par l’absurde. Les problèmes surgissent lorsque les lecteurs ne comprennent pas ou ne souhaitent pas comprendre pour alimenter leur agenda politique, et relaient ces informations pour agent comptant, comme cela s’est souvent vu pour le journal numérique le Gorafi [4]. Ces exemples sont emblématiques de la problématique des infox : il s’agit d’informations volontairement fausses destinées à faire rire ses lecteurs, qui sont ensuite utilisées sérieusement le plus souvent dans une démarche politique. Où se situe la fake news ? Dans le contenu original ? Dans son partage irréfléchi ?
Enfin, la véracité d’une information est un caractère changeant dans le temps ; nous l’observons presque quotidiennement avec l’évolution du contexte sanitaire et le partage d’informations à outrance. C’est pourquoi à la faveur d’une situation instable, une infox devient une info et inversement, rendant la tâche de détection encore plus ardue.

1.2 Les travaux de recherche
Si l’on cherche à mettre au point un mécanisme de détection des infox, dans le cadre de la satire, il s’agit simplement de détecter l’origine de l’information. On peut facilement supposer que les sites satiriques qui parodient l’actualité ne partagent que ce type de contenus, et ainsi les estimer à leur juste valeur.
Il existe également une autre façon de caractériser le caractère douteux d’une information, qui plus est dans le cadre de la désinformation. Dans ce cas, l’intention de l’auteur nourrit un but précis, et c’est pourquoi le parcours de cette information est crucial pour maximiser l’impact qu’elle pourrait avoir. C’est dans le but de comprendre les mécanismes de propagation des infox, afin de mieux pouvoir les caractériser, que le Conseil Supérieur de l’Audiovisuel a commandé une étude sur la propagation des fake news sur les réseaux sociaux, et notamment sur la plateforme Twitter, malheureusement connue pour être un des relais les plus importants. L’étude publie différents résultats :
- Les comptes responsables d’infox disposent de peu d’abonnés, mais ils sont très engagés, ce qui fait que le moindre contenu est beaucoup partagé. À l’inverse, les comptes officiels de vérification de l’information disposent de beaucoup d’abonnés qui interagissent moins avec ces contenus.
- L’apparition d’une vérification d’information ne suffit pas à supprimer l’infox, à cause de la dynamique de réactions autour de ces contenus [5]. D’ailleurs, il est de notoriété publique que les plateformes de partage privilégient les contenus qui génèrent de l’activité sur la plateforme. Ainsi, les infox cherchent à générer des réactions, quitte à ce qu’elles soient négatives, pour faciliter leur propagation sur les différents fils d’actualité. Ces résultats empiriques se retrouvent d’ailleurs dans de nombreux travaux académiques de modélisation [6].
Il est à noter que la grande majorité de ces travaux porte sur des contenus en anglais. En effet, la recherche sur le sujet a vu un regain d’intérêt à la suite des élections présidentielles américaines de 2016. Par ailleurs, quand bien même le problème des infox n’est pas propre à la presse anglophone, cette dernière représente une part majoritaire des contenus partagés en ligne. Il est donc compréhensible que la plupart des jeux de données soient en anglais. Enfin, comme énoncé plus haut, il n’est pas évident de trouver des données permettant l’étude des fake news, sauf à forger son propre dataset ou disposer de professionnels de la vérification d’information. Il est donc à noter le travail remarquable d’une équipe du Nara Institute of Science and Technology du Japon, dont une étude regroupe 118 datasets existants, ainsi qu’une revue des différents défis qui vont se proposer dans le domaine, comme les biais présents dans les jeux de données [7]. C’est d’ailleurs de cette étude que le jeu de données utilisé dans la suite de l’article a été tiré.
1.3 Jeu de données
Nous avons précisé précédemment que définir une information comme fausse n’est pas trivial, principalement à cause de la temporalité de l’information. En effet, prenons pour exemple le contexte sanitaire actuel, lié à la pandémie de COVID-19. Les premières informations en mai 2020 stipulant que le virus proviendrait de laboratoires chinois dans la zone de Wuhan ont rapidement été taxées de fake news, voire de complotisme. En revanche, un an plus tard, l’infox devenait « théorie » plausible [8], poussant des journaux à changer a posteriori le titre de leurs articles.
C’est pourquoi les jeux de données d’infox sont précieux, si toutefois on admet leur qualité. Ainsi, le jeu de données que nous allons manipuler est composé de 7794 articles, et le lecteur curieux pourra le trouver facilement en ligne [9]. Il est également équilibré, puisqu’il se répartit en 3164 infox, notées « FAKE », et par conséquent, 3171 informations légitimes, notées « REAL ». Enfin, les données elles-mêmes se déclinent en deux propriétés : le titre, noté « title », de l’information, d’une longueur maximale de 289 caractères, et le corps, noté « text », qui contient environ entre 2 et 20000 mots. Une illustration du jeu de données et disponible en figure 2.
Malheureusement, la langue utilisée est l’anglais. Pour autant, cela ne va pas être un frein pour la manipulation et la valorisation de ces données, notamment par l’entraînement d’un algorithme supervisé.
2. Modélisation
Les modèles d’apprentissage automatique sont parfois considérés comme étant intelligents, mais il n’y a pas de magie : ils ne peuvent « s’entraîner » que sur des données numériques. Or, les données à l’étude sont exclusivement composées de lettres, à savoir des phrases en langue anglaise. Pour leur permettre de réaliser leur tâche, en l’occurrence la détection d’infox, nous allons devoir tout d’abord trouver un moyen de traduire ces données en nombres.
2.1 Mise en forme et manipulation
De manière intuitive, on comprend que dans une phrase, tous les mots n’ont pas le même poids. Par exemple, la conjonction de coordination « et », au demeurant très utile pour construire un discours, n’est pas porteuse de sens en elle-même. En revanche, certains mots sont sémantiquement déterminants pour un contexte. Une phrase comportant le terme « ordinateur » risque vraisemblablement de parler d’informatique. Si l’on ajoute le terme « prix », on devine que le sujet porte autour de la valeur économique du matériel informatique. Il peut être judicieux, par exemple, de noter pour chaque mot s’il apparaît dans chacun des articles. On peut même compter le nombre de fois que ce même mot apparaît dans une information. On a vu précédemment que les informations n’étaient pas de même longueur, et il est logique que plus de mots apparaissent plus souvent dans une information longue. Aussi, pour comparer les informations entre elles par rapport au compte d’un seul mot, il nous faut appliquer comme un coefficient de moyenne qui prend en compte la longueur de l’information. Par exemple, si je divise le nombre de fois qu’un mot apparaît dans le texte par le nombre de mots qui composent le texte, je n’ai pas seulement le compte du mot, mais sa fréquence. On appellera cette grandeur term frequency (TF), et elle mesure la fréquence d’apparition d’un mot dans un texte. Sa valeur est nécessairement comprise entre 0 et 1 ; plus elle est proche de 0 et moins le mot apparaît dans le texte (0 étant l’absence totale du mot), et plus elle est proche de 1, plus le mot apparaît dans le texte.
Souvenez-vous, nous voulons déterminer des grandeurs numériques qui vont permettre de caractériser chacune des informations pour faciliter le travail du modèle statistique. À cet égard, il nous faut déterminer si le mot est rare dans l’entièreté du corpus composé par tous les articles, et pas seulement dans une seule information. En effet, un mot très fréquent dans une seule information est probablement déterminant pour le sens de cette information. Pour chaque mot, on peut compter le nombre d’articles dans lesquels il se trouve. Comme pour la fréquence, nous allons diviser ce terme par un coefficient de moyenne, ici le nombre total d’informations dans le corpus. On constate que cette grandeur est également comprise entre 0 et 1, donc son inverse, c’est-à-dire le nombre total d’informations, divisé par le nombre d’informations où le mot apparaît, est supérieure à 1. Cette dernière grandeur, c’est la fréquence inverse de document, en anglais inverse document frequency, (IDF) à ceci près qu’on prendra souvent la valeur logarithmique de cette grandeur. L’intuition de l’utilisation du logarithme repose sur la volonté de lisser les variations du ratio : il faudra une variation significative du ratio pour une variation modeste de la fréquence inverse de document.
Si l’on combine TF et IDF, par exemple par un produit, on obtient pour chaque mot une grandeur qui caractérise la fréquence d’un mot dans une information en prenant en compte la fréquence de ce mot dans l’entièreté du corpus des informations. Autrement dit, si ce produit est proche de 0, alors le mot est soit inexistant dans toutes les informations, ou alors présent dans toutes les informations et donc vraisemblablement pas intéressant pour discriminer les informations entre elles, soit ce produit est très grand, ce qui veut dire que le mot est présent dans un nombre restreint d’informations, et potentiellement de nombreuses fois. On va donc calculer le produit TF x IDF pour chacun des mots, et utiliser ces grandeurs numériques pour l’apprentissage de notre modèle de détection d’infox. Ces explications sont condensées dans la formule de la figure 3, où : i est l’indice du mot étudié, j est l’indice de l’article (on parle aussi de document), k est le nombre de mots qu’il y a dans le document j, |D| est le nombre total de documents, et |dj : ti dans dj| le nombre de documents dans lesquels apparaît le mot i. On illustre également ces grandeurs dans la figure 4.

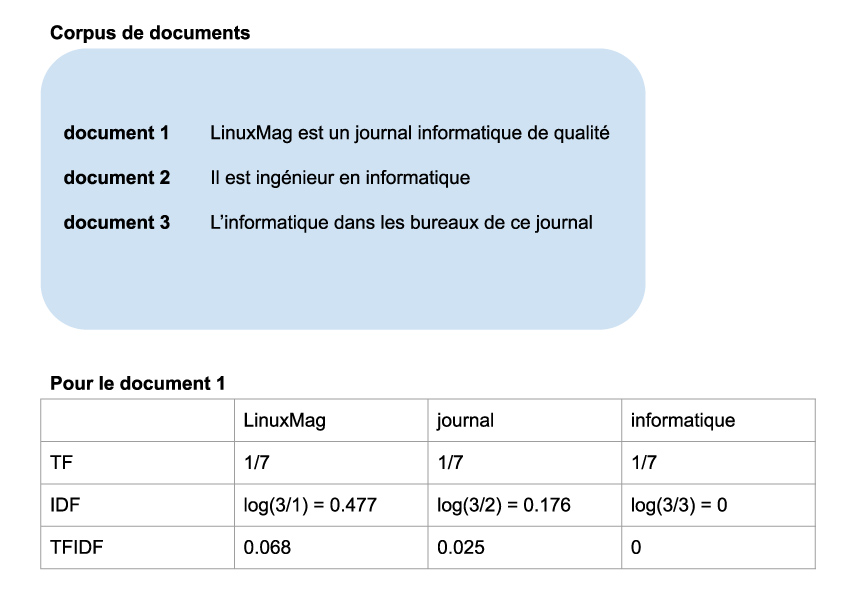
Une dernière question demeure : quels sont les mots pour lesquels on souhaite calculer le TF-IDF ? Comme dit précédemment, il n’est peut-être pas pertinent de calculer le TF-IDF pour des mots comme des conjonctions de coordination, ou plus généralement des mots de liaison. On appelle parfois ces mots des stop words et il existe, par langues, un lexique complet de ces mots qui ne semblent pas pertinents dans un contexte sémantique. Si l’on dispose de ce dictionnaire, il devient facile d’exclure ces mots des calculs. Une autre méthode consiste à réaliser le TF-IDF pour tous les mots, et de retirer ensuite les mots pour lesquels le TF-IDF est par exemple inférieur à un seuil, ou encore les 20 % les plus faibles.
2.2 Choix du modèle et entraînement
Pour rappel, nous disposons pour notre jeu de données d’entraînement d’une matrice de dimension N x M ou N est le nombre total de documents (ici, des informations) et M est le nombre total de mots considérés pour le calcul du TF-IDF. Même si ces valeurs ne semblent pas interprétables, nous allons voir qu’il est très facile de les valoriser, avec de plus un modèle très simple. En l’occurrence, nous allons nous intéresser à un modèle passif-agressif. Il ne s’agit pas du sens commun de l’expression, mais bien d’une mécanique dans l’apprentissage du modèle : durant l’entraînement, lorsque le modèle ne fait pas d’erreur d’estimation pour une prédiction, il ne se passe rien (passif). En revanche, s’il fait une erreur, il va chercher à la corriger immédiatement (agressif). Notre problème est une détection de fake news, donc notre modèle va faire une classification binaire (« FAKE », « REAL »). Par convention, nous allons encoder le caractère « FAKE » en 1 et le caractère « REAL » en -1. La description de l’entraînement du modèle est dans le pseudo-code en figure 5.

Le modèle est donc relativement simple : il s’agit d’un vecteur de poids de même longueur que le nombre de mots considérés pour le calcul du TF-IDF. La prédiction, quant à elle, est directement le signe du produit scalaire entre ces poids et les valeurs du TF-IDF pour le document considéré. Comment se fait-il qu’ainsi défini, le modèle puisse fonctionner ? L’explication réside dans l’expression de la fonction coût calculée pour chaque exemple.
Par définition, la variable à prédire a un signe, par exemple positif. Si le produit scalaire est de même signe que la variable à prédire, le modèle fait une bonne prédiction. La fonction coût nous montre que l’on va soustraire la valeur du produit scalaire à 1. Si cette soustraction est négative, cela veut dire qu’en valeur absolue, le produit scalaire est supérieur à 1, et la fonction coût vaudra 0 : on retrouve le comportement passif du modèle. En revanche, si cette soustraction est positive, alors la fonction coût n’est pas nulle, et l’on va ensuite mettre à jour le modèle : on retrouve le comportement « agressif », ou à tout le moins actif du modèle. On pourrait, dans l’absolu, ne pas comparer le produit scalaire à 1, mais seulement regarder le signe du produit scalaire. Le fait de se comparer à 1 permet de renforcer le modèle dans ses bonnes prédictions, mais qui ne sont pas « franches », c’est à dire où le produit scalaire a le bon signe, mais une valeur faible. Notons qu’il existe plusieurs façons de calculer le taux d’accroissement, mais le principe général reste le même [10]. Enfin, le modèle va réitérer ce processus pour chaque document présent dans le jeu de données d’entraînement. On comprend que le modèle risque d’apprendre correctement les derniers exemples à sa disposition, au risque « d’oublier » ce qu’il a appris des premiers : c’est pourquoi il est possible de passer plusieurs fois sur les données d’apprentissage, avec parfois, un ordre de traitement différent (on parle alors de plusieurs epochs).
Que le lecteur se rassure, il n’est pas question d’implémenter à partir de rien le code de cet algorithme. Dans le langage utilisé, en l’occurrence le Python, il existe de nombreux algorithmes déjà codés, et nous aurons seulement besoin de fournir les données d’apprentissage et d’évaluation pour entraîner le modèle. Dans le cas des algorithmes de Machine Learning, la bibliothèque indispensable à connaître est scikit-learn. De plus, nous allons voir que si les explications sont verbeuses, le code, lui est succinct :
On reconnaît le formalisme de la librairie scikit-learn : chaque modèle, ici le TfidfVectorizer et le PassiveAgressiveClassifier sont d’abord instanciés avec des paramètres en tant qu’objets Python, puis déterminés sur des données d’entraînement via une méthode d’apprentissage (fit), et enfin appliqués à d’autres données en prédiction (predict) ou en transformation (transform). Le calcul du TF-IDF se fait en enlevant un ensemble de mots stop words tiré d’une liste anglaise, et l’on ignore les mots qui apparaissent dans plus de 70 % des documents. Le modèle passif-agressif quant à lui dispose d’un paramètre max_iter qui est en fait le nombre d’epochs que nous allons imposer au modèle. Enfin, ce code s’exécute entièrement en un peu plus de 3 secondes, et il est entièrement disponible en ligne [8]. Il est donc très simple d’entraîner ce type de modèle en Python, mais sommes-nous sûrs qu’il s’agisse d’un bon modèle ?
2.3 Performances du modèle
La dernière instruction du code ci-dessus porte sur le calcul de l’accuracy-score, que l’on traduirait en score de précision. Son calcul est simple : on applique le modèle entraîné sur un ensemble de données de validation que le modèle n’a pas vu en entraînement, et l’on compte la fréquence d’erreur du modèle. Notons que le jeu de données d’évaluation constitue 20 % du jeu de données total, et qu’il est choisi aléatoirement, afin d’assurer une bonne généralisation du modèle. La précision du modèle ainsi calculé est 92,6 %. Une autre façon de mesurer la performance d’un modèle en classification binaire repose sur le calcul de l’aire sous la courbe ROC. Plus cette valeur est proche de 1 et plus le modèle tend vers le modèle parfait. Cette courbe est disponible en figure 6.
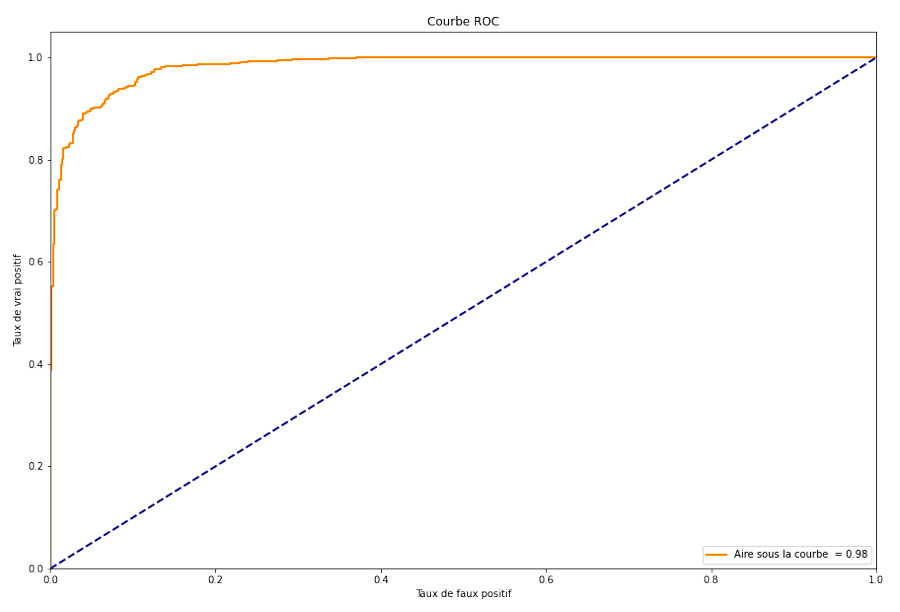
Le modèle semble bon. Il peut être toutefois intéressant de le tester sur de vraies données, et tenter d’interpréter ses éventuelles erreurs. Nous allons utiliser l’API de Google News, afin de récupérer des articles récents et qui ne sont pas issus du jeu de données initial. Pour ce faire, il faut préalablement créer un compte sur https://newsapi.org/ ainsi qu’un jeton d’API, installer la bibliothèque Python newsapi-python permettant d’interagir avec cette API et le tour est quasiment joué :
Nous nous limitons aux 5 premières pages de résultats, ce qui correspond au maximum autorisé pour un compte gratuit. C’est également pour cette raison que nous n’aurons accès qu’à une description succincte de l’article, plutôt que l’intégralité de son contenu. Comme le jeu de données d’entraînement semble comporter beaucoup d’articles traitant de politique, nous allons tout d’abord nous intéresser aux articles traitant de Joe Biden, actuel président des États-Unis d’Amérique.
On applique le TF-IDF puis le modèle sur l’ensemble des descriptions des articles, et l’on obtient une précision de 55 % seulement, en supposant que toutes les nouvelles ainsi collectées sont vraies ! Un tel écart en performances ne peut s’expliquer que de deux façons : soit le modèle ne généralise pas sur des articles récents et il n’est pas utile sur les actualités, soit utiliser la description de l’article comme indicateur de contenu n’est pas correct. Le plus simple pour trancher est de récupérer l’entièreté des articles en question, et d’appliquer le modèle sur l’ensemble de leur contenu. Cependant, nous ne pouvons pas accéder au contenu avec un compte gratuit pour l’API News. Nous allons donc récupérer le contenu à partir de l’URL de l’article, directement : on parle alors de scrapping. Il nous faut signaler que le scrapping est une activité répréhensible et que l’auteur se permet de le faire ici à des fins de recherche, sur un ensemble de données restreint.
Nous allons utiliser la bibliothèque Python newspaper3k, qui va nous permettre de récupérer et d’analyser le contenu brut, afin d’en extraire le corps de l’article. Ainsi, supposons que l’URL d’un des articles soit stockée dans une variable link, la récupération du contenu d’une information grâce à newspaper3k, la transformation par TF-IDF, puis la prédiction par notre modèle se fait comme suit :
Si l’on réalise cette manipulation pour l’ensemble des articles évoqués précédemment, on constate que la performance du modèle sur le jeu de données grimpe à 72 %! Notre modèle est donc très sensible à l’exhaustivité du contenu.
Par curiosité, la même démarche a été appliquée aux articles traitant du Bitcoin, sur la même période, et le comportement est étrange : d’une précision de 17,5 % sur les descriptions des articles, le modèle passe à une précision de 17 % sur l’ensemble du contenu. Il se peut que notre modèle, entraîné sur des données plutôt d’ordre politique, ne généralise pas bien sur le sujet du Bitcoin. Il se peut également, au vu de l’actualité sur la cryptomonnaie, que nombre d’informations soient inexactes. On constate tout de même que ce modèle a ses limites, et nous allons explorer une méthode originale afin de trouver des pistes d’amélioration.
3. Approche non supervisée
Il n’aura pas échappé au lecteur attentif que nous n’avons pas exploité une partie du jeu de données précédent. Le modèle passif-agressif se repose exclusivement sur le contenu des articles, mais rien n’a été fait concernant leur titre. Aussi, nous allons chercher à déterminer si, selon le vieil adage, « qui se ressemble s’assemble ». Autrement dit, nous allons tâcher de trouver si les titres des infox ont tendance à se ressembler et à se dissocier des informations légitimes.
3.1 Vectorisation
Pour rappel, nous avons utilisé le TF-IDF pour encoder un document, en l’occurrence un article de presse, en un vecteur de valeurs numériques. Cette étape était nécessaire pour permettre au modèle que nous avons choisi de « s’entraîner ». En réalité, il existe une multitude de techniques pour traduire une donnée non numérique, surtout un texte, en une donnée numérique.
Par exemple, nous allons utiliser le universal sentence encoder, un modèle à base de réseaux de neurones qui traduit toute phrase en un vecteur de dimensions 512 [11]. Comment s’assurer alors que cette représentation est pertinente ? Comment construire ce modèle de telle sorte que la correspondance ait un sens ? C’est toute l’astuce sous-jacente : le modèle est précisément entraîné à construire cette vectorisation afin de remplir des tâches précises. Parmi ces tâches, on peut citer la prédiction de la phrase précédente et de la phrase suivante dans un texte, ou encore la prédiction de la réponse adéquate dans une conversation avec un chatbot. Les phrases manipulées sont transformées en leur vecteur, et le modèle global est entraîné à fournir une vectorisation qui permette de remplir ces tâches. Ainsi, nous pouvons faire correspondre à chaque titre d’article un vecteur de 512 coordonnées. Or, il nous est relativement complexe de nous représenter 512 dimensions. Aussi, nous allons tâcher de réduire la dimension de notre jeu de données, avec deux outils : l’analyse en composantes principales (ACP ou PCA en anglais) et t-sne. L’analyse en composantes principales est une méthode algébrique connue pour projeter un ensemble de points d’un espace de départ dans un espace d’arrivée à dimensions réduites. On peut le voir comme une simplification de l’information, pour laquelle nous n’allons garder que les principaux traits.
Quant à t-sne, il s’agit d’une méthode de compression de l’information qui renforce les écarts géométriques entre les points de l’espace de départ dans l’espace d’arrivée. La grande différence avec l’ACP, c’est qu’il ne s’agit pas d’une projection algébrique, mais d’une projection analytique. Prenons l’analogie suivante : supposons que les points que nous étudions soient tous reliés par des ressorts, et que la raideur de ces ressorts dépend de la similarité entre les points (des points similaires sont reliés par un ressort dur). Supposons également que ces points sont dans un espace à trois dimensions, sans gravité. Alors si l’on applique brusquement un champ de gravité, les points tomberont sur une surface plane (par exemple, une table) et se rapprocheront en fonction de leur similarité, selon les lois de la physique d’un ressort. Ce comportement physique décrit intuitivement le comportement de l’algorithme t-sne, disponible dans la littérature [12]. Puisque cet algorithme permet la projection de dimensions, le lecteur serait en droit de se demander pourquoi l’ACP serait nécessaire. Il se trouve qu’empiriquement, l’algorithme t-sne fonctionne mieux dans des espaces à dimensions raisonnables, soit une cinquantaine. Nous allons donc :
- Transformer les titres des articles en un vecteur de dimensions 512 grâce à l’universal sentence encoder.
- Réduire ces données par ACP à une dimension inférieure à 50 une première fois.
- Puis réduire ces données par t-sne afin de voir si les titres d’articles se distribuent d’une certaine façon selon qu’il s’agisse d’une infox ou non.
3.2 Implémentation et visualisation
Comme vu précédemment, les explications sont plus verbeuses que le code d’implémentation :
Le temps d’exécution du code ci-dessus est légèrement plus important que pour le modèle passif-agressif, soit une vingtaine de secondes. Nous n’avons pas fait cas des paramètres fournis à l’instanciation du modèle t-sne : leur explication est subtile, et le lecteur curieux saura les appréhender à l’adresse suivante : https://distill.pub/2016/misread-tsne/. Enfin, il est à noter qu’il est plus judicieux de télécharger le modèle de l’universal sentence encoder au préalable, et de le charger ensuite depuis sa machine locale.
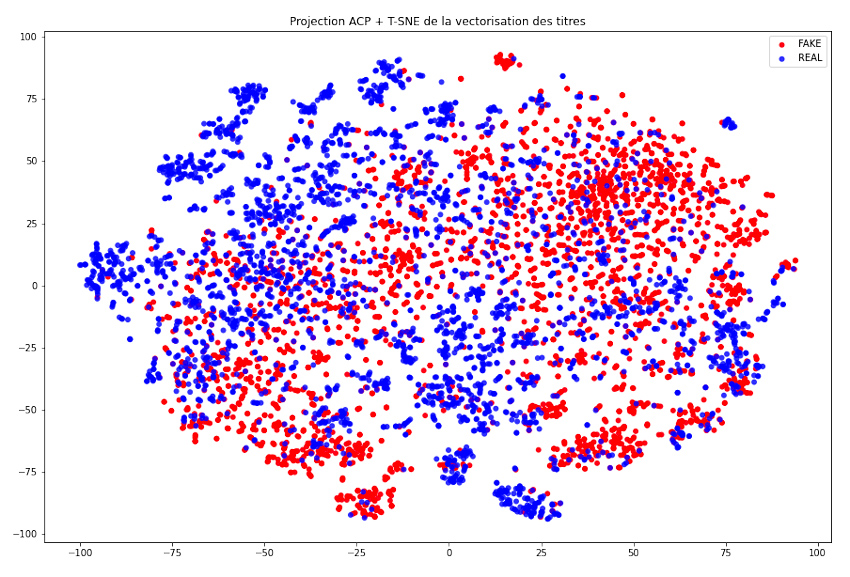
Une visualisation du résultat est disponible en figure 7. On constate tout d’abord qu’il n’existe pas de séparation franche entre les infox et les informations. Pour autant, il semblerait qu’il existe comme des grappes entre les deux classes. Ainsi, il semblerait que les titres dans le jeu de données semblent se répartir, au moins localement, en fonction de leur condition. En revanche, il est à noter que t-sne ne permet pas d’appliquer le modèle à de nouvelles données : nous ne pouvons pas utiliser cette modélisation pour généraliser nos résultats. On retiendra donc que si l’on veut compléter notre précédent modèle, une méthode de clustering peut être pertinente, parmi laquelle une modélisation par K plus proches voisins par exemple.
Conclusion
Les fake news ou infox sont désormais une composante importante de notre consommation d’informations. Si les conséquences sont réelles, il est difficile de s’outiller pour limiter leur impact. En effet, il n’est pas trivial de définir précisément ce qui tient de la désinformation ou de la satire, et tant que ces concepts ne seront pas complètement cernés, les marges de progression sont significatives. De plus, le caractère vrai ou faux d’une information n’est pas immuable, et est susceptible de changer à la faveur de nouvelles découvertes, voire de changement de climat politique. En revanche, il existe d’ores et déjà dans la littérature un ensemble de jeu de données qui permettent de s’essayer à des méthodes de détection s’appuyant sur du Machine Learning. Avec l’un d’eux, nous avons pu essayer différentes approches en nous concentrant exclusivement sur le contenu des articles à l’étude. Il existe de nombreux leviers d’amélioration à nos approches : incorporer le titre dans la modélisation supervisée, essayer d’autres modèles que la modélisation passive-agressive, etc. Nous avons vu que les modèles sur lesquels nous avons travaillé ont des performances intéressantes, mais certainement pas suffisantes pour être suivis aveuglément. C’est d’ailleurs préférable : serions-nous réellement prêts à faire confiance à un algorithme pour déterminer pour nous ce qui tient de la vérité, d’autant plus que le modèle ne semble pas être infaillible ?
Nous pouvons imaginer une utilisation combinée de plusieurs modèles : ces algorithmes ne sauraient être utilisés de façon autonome et sans discernement individuellement, mais plutôt fourniraient un ensemble d’indicateurs à un analyste humain, qui lui prendrait la décision de classer une information comme infox ou non. Cette tâche aujourd’hui est ardue, puisque ces analystes doivent traiter un grand nombre d’informations, et ce très rapidement. Ainsi, ce type de modèles peut leur faire gagner un temps conséquent, et démultiplier les capacités de traitement, permettant ainsi de se concentrer sur des cas qui nécessitent plus d’attention.
Par ailleurs, il est à noter qu’une partie conséquente de la recherche à l’heure actuelle s’attache davantage à détecter les infox à partir de leurs mécanismes de propagation. Mais là encore, les modélisations se heurtent à des biais importants sur les comportements humains : c’est par manque de mesure et de sang froid que bon nombre d’infox sont partagées, amplifiant ainsi leurs effets néfastes. Il est également à craindre aussi des effets de bulles : si des vecteurs de partage d’informations, comme des comptes Twitter, sont régulièrement associés à des contenus fallacieux, ces modèles auront également tendance à classer comme une infox une information qui pourrait être vraie, par délit de provenance. Aussi, la technologie n’est pas à prendre comme une solution miracle. Il nous faudra invariablement questionner, raisonner, croiser les sources pour continuer de développer le meilleur détecteur d’infox dont nous disposons : notre sens critique. À mon sens, si avec l’ensemble important de données et les modélisations complexes dont nous disposons, il n’est pas évident de déterminer un algorithme performant, c’est bien qu’il s’agit d’une tâche ardue et subtile, et donc éminemment humaine. C’est précisément pour cela qu’elle mérite toute notre attention et nos efforts.
Références
[1] https://www.theguardian.net/fake-news-what-cost-in-2021.html
[2] Carlos Carvalho, Nicholas Klagge, and Emanuel Moench. 2011. « The persistent effects of a false news shock. » Journal of Empirical Finance 18, 4. (2011), 597–615.
[3] Alexandre Bovet and Hernán A Makse. 2019. « Influence of fake news in Twitter during the 2016 US presidential election. » Nature communications 10, 1 (2019), 1–14.
[5] La propagation des fausses informations sur les réseaux sociaux, novembre 2020, Les collections CSA.
[6] Monti, Federico, et al. « Fake news detection on social media using geometric deep learning. » arXiv preprint arXiv:1902.06673 (2019).
[7] Murayama, Taichi. « Dataset of Fake News Detection and Fact Verification: A Survey. » arXiv preprint arXiv:2111.03299 (2021).
[8] https://www.bbc.com/news/world-asia-china-57268111
[9] https://data-flair.training/blogs/advanced-python-project-detecting-fake-news/
[10] Crammer, Koby, et al. « Online passive aggressive algorithms. » (2006).
[11] Cer, Daniel, et al. « Universal sentence encoder. » arXiv preprint arXiv:1803.11175 (2018).
[12] Van der Maaten, Laurens, and Geoffrey Hinton. « Visualizing data using t-SNE. » Journal of machine learning research 9.11 (2008).


