
De nos jours, choisir d’automatiser la gestion de son système d’information en adoptant une démarche qui s’inscrit dans l’utilisation de l’Infrastructure en tant que Code est une manière de gagner en agilité et en efficacité.
Cependant, la mise en place de nouveaux serveurs ou services pour nos usagers ne se déroule pas toujours comme la documentation l’indique. Dans ce contexte, nous devons non seulement nous assurer que ces changements n’induiront pas d’effets de bord sur l’écosystème déjà en place, que l’interopérabilité avec les autres briques techniques soit au rendez-vous, mais aussi parfois faire face à des erreurs inattendues.
Vous l’aurez compris, impossible de laisser faire le hasard : l’introduction d’une « nouveauté » au sein de son système d’information, quelle que soit sa forme, doit être préparée. Cette démarche s’accompagne d’une phase en amont extrêmement importante avant la mise en production. Cette étape vise ainsi à préparer l’infrastructure et les applications de manière à les rendre à terme robustes, flexibles et résilientes.
L’objectif affiché ici est donc très clairement d’engager une réflexion et un maquettage avant la mise en production et à l’échelle le cas échéant. Dans cette perspective, les personnes en charge des aspects système dans leurs structures auront recours, en outre, à un outil dédié pour le déploiement de leur infrastructure et, en accompagnement, d’un outil d’aide au déploiement des applications et à la gestion des configurations.
Il n’est pas rare de procéder, dans ce cas, de manière cyclique en répétant « tâtonnements » et « échecs » jusqu’à l’obtention du résultat escompté. Cela ne vous rappelle rien ? Peut-être avez-vous déjà entendu parler du Développement Dirigé par les Tests (Test Driven Development) ?
Cette technique est de plus en plus utilisée par les développeurs dans nos équipes. Mais après tout, pourquoi ne pas adopter plus globalement le Test Driven Development (TDD) afin de déployer notre infrastructure et nos services… puisque nous nous inscrivons naturellement dans une démarche qui y ressemble fortement ? Voyons, en pratique, l’approche que nous pourrions adopter dans ce cas !
1. Présentation de la philosophie du TDD
Avant d’entrer dans le vif du sujet, je vous propose d’en apprendre un peu plus sur le développement dirigé par les tests. Sa paternité est attribuée à un ingénieur logiciel, Kent Beck. Il est l’auteur d’un livre [1] publié il y a plus de vingt ans dans lequel il résume cette philosophie.
Il pose le constat suivant : auparavant, les développeurs écrivaient les tests d’une portion d’un programme afin de vérifier la validité de ce qui a été implémenté. En clair, ils ajoutaient du code puis le complétaient par un test qui contrôlait que le code produit se réalise correctement. Cette approche, traditionnelle, présente malheureusement quelques inconvénients.
Ainsi, en écrivant les tests après le code, cela peut mener à des lacunes en matière de couverture des tests et à des erreurs non détectées. Le remaniement du code (ou refactoring) devient plus aussi risqué : il est souvent évité par crainte de casser des fonctionnalités existantes en raison de l’absence de tests complets. Enfin, si vous utilisez une chaîne d’intégration continue dans votre processus de développement, cela peut nécessiter des ajustements complémentaires pour s’intégrer efficacement en raison de tests manquants ou inadéquats.
Le TDD propose d’inverser la logique de conception pour pallier à tout cela. Il peut être défini comme étant une méthode de développement logiciel qui vise à concevoir une application en combinant des cycles courts de livraisons et des itérations successives. Chacune de ces itérations consiste à définir un sous-problème, sous forme de tests, avant d'écrire le code source correspondant. Ce code est ensuite continuellement retravaillé dans le but de le simplifier et de l’améliorer (renommage de méthodes, suppression des lignes inutiles, etc.).
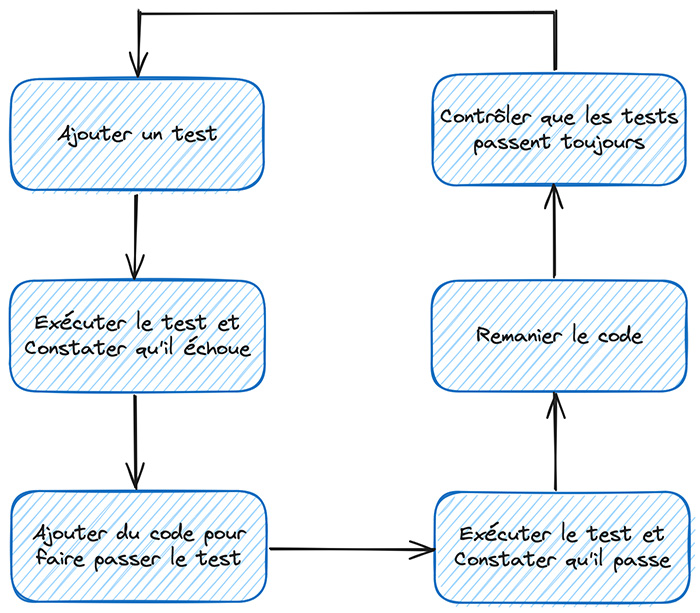
Vous remarquerez probablement que les tests unitaires sont systématiquement relancés après la dernière étape de contrôle : ceci nous permet de nous assurer que la phase de refactoring n’a pas engendré de répercussion sur des fonctionnalités qui auraient pu être ajoutées.
Cette technique, très souvent utilisée par les équipes agiles, est donc itérative et incrémentale. Elle incite, de fait, les équipes de développement à corriger les effets de bords au fur et à mesure de la programmation en s’appuyant notamment sur l’écriture de tests. Dans le cadre d’une approche TDD, les tests deviennent alors l’outil du développeur : ils ne sont pas l’objectif, mais dictent néanmoins la marche à suivre.
Pour illustrer cela, nous pouvons essayer de faire un parallèle avec la science. En effet, les expériences ne sont pas menées au hasard ! Nous nous basons toujours sur une hypothèse de départ, un point que nous cherchons à prouver ou réfuter… puis nous réfléchissons à la conception d’une expérience qui permet de valider ou non le postulat.
Avec TDD, le cycle de développement se doit d’être le plus court et le plus simple possible. C’est ce que nous appelons Mantra ou encore RGR. La signification de l’acronyme RGR est la suivante :
- R pour la couleur rouge (Red) : il s’agit d’écrire un code de test et de le faire échouer ;
- G pour la couleur verte (Green) : il faut ici écrire le code métier qui valide le test précédent ;
- R pour le refactoring (Refactor) : le code est revu pour améliorer sa qualité globale.
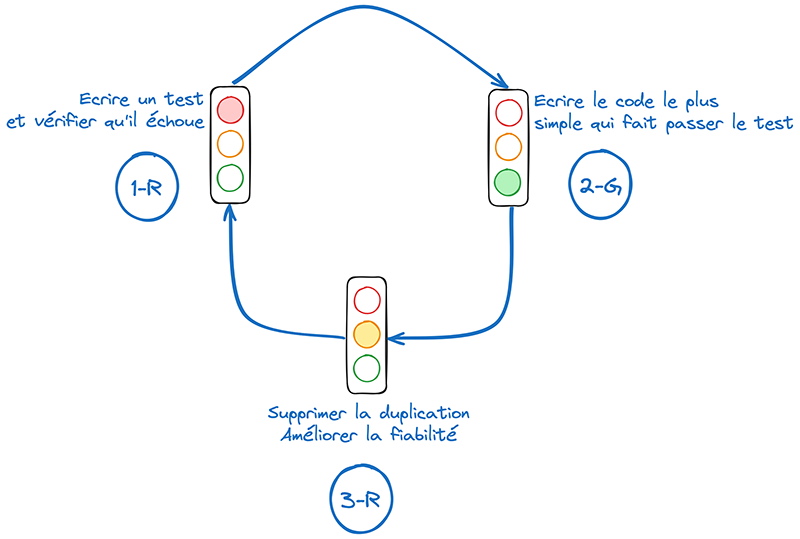
Si nous appliquons ce principe à notre démarche, lorsque nous écrivons un test avant d’écrire l’infrastructure en tant que code, nous émettons une hypothèse sur la manière dont notre manifeste se comportera, sur les entrées à lui transmettre et sur les sorties attendues (informations, flux de données, etc.). Cette méthode peut donc s’avérer extrêmement pratique dans notre cas.
La phase de débogage devient plus rapide, car les tests automatisés permettent d’identifier rapidement le problème. En se concentrant sur l’écriture des tests avant son manifeste, l’administrateur est encouragé à concevoir des interfaces et des API plus claires et plus modulaires. Enfin, en écrivant les tests avant le code, vous vous assurez que chaque fonctionnalité est testée dès le départ : cela conduit à un déploiement plus « robuste » et moins sujet aux erreurs.
Il est donc tout à fait possible d’adopter cette démarche pour faire évoluer le système d’information de sa structure avec ceinture et bretelles ! Je vous propose, dans les lignes à venir, de découvrir comment nous pourrions procéder...
2. Appliquer une démarche TDD quand on est Ops
Pour provisionner de nouvelles machines et déployer nos services dans ce contexte, cela passera par trois étapes majeures.
La première d’entre elles consiste, évidemment, à écrire les tests avant nos manifestes. Si vous souhaitez vous inscrire dans une démarche TDD, il est donc nécessaire de les spécifier avant de créer votre infrastructure. De manière concrète, ils doivent vous permettre de vérifier certains aspects.
Dans un second temps, nous pourrons passer à la phase de développement. C’est à partir de ce moment qu’entrent en scène les outils d’Infrastructure en tant que Code (IaC) tels que Terraform [2] (ou son fork libre OpenTofu), Ansible [3], etc. Les manifestes que vous aurez rédigés sont ainsi écrits pour satisfaire les tests exprimés à l’étape précédente.
La dernière étape consiste enfin à exécuter puis valider nos tests. Après avoir développé votre infrastructure, il ne vous reste plus qu’à lancer vos scénarios de tests afin de contrôler que ce que vous souhaitez déployer répond bien aux exigences exprimées précédemment.
De manière concrète, cela passe par une utilisation non seulement d’outils de tests automatisés (tels que Terratest ou encore Testinfra [4]), mais aussi de scripts complémentaires de vérification qui testeront, en marge, des configurations spécifiques ou des fonctionnalités.
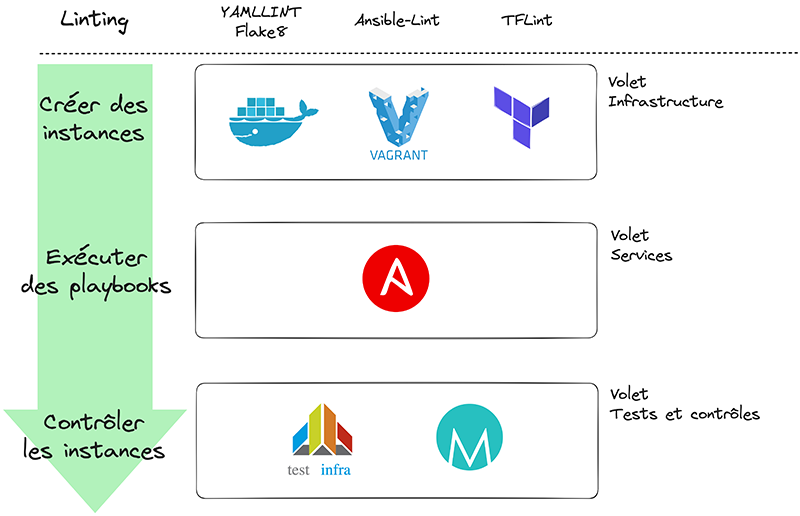
Avec ces trois étapes, nous posons ainsi la base d’un cycle d’amélioration continue qui repose sur la démarche TDD : écrire des tests, développer, tester. Nous retrouvons ici la Mantra du TDD.
Pour que cela fonctionne, il est nécessaire de répéter continuellement ce cycle à chaque changement opéré sur l’infrastructure. De cette manière, cela garantit que toute nouvelle modification est validée par une batterie de tests automatisés. Ces derniers réduisent ainsi les risques d’erreurs et augmentent de façon significative la fiabilité de votre infrastructure et des services déployés.
Appliquer cette démarche vous apporte un certain nombre d’avantages. Cela contribue à améliorer la qualité et la fiabilité, car en testant continuellement, vous garantissez que l'infrastructure est toujours dans un état conforme aux spécifications.
De la même façon, les corrections sont plus faciles à apporter, car elles sont détectées plus tôt dans votre processus de développement. Les erreurs humaines sont également réduites, car TDD encourage l’automatisation des tests et augmente ainsi l’efficacité.
Enfin… et c’est un atout non négligeable : vous pouvez obtenir une vraie documentation vivante ! C’est un point crucial, souvent oublié des administrateurs « pressés ». Les tests deviennent alors le support de documentation qui décrit la manière dont l’infrastructure doit se comporter et fonctionner. La maintenance, dans le temps, se voit facilitée.
Laissons de côté la théorie désormais pour voir, en pratique, comment combiner l’outillage DevOps mis à notre disposition pour s’inscrire dans cette démarche de Test Driven Development.
3. Pratiquer le TDD pour poser les bases de son infrastructure
Comme nous l’avons vu dans les lignes précédentes, le recours à TDD conduit à un développement plus discipliné, à un code de meilleure qualité, et à une réduction des coûts à long terme grâce à une détection précoce des erreurs et à une meilleure maintenabilité du code. Mais dans les faits, comment procéder ?
3.1 Avec le couple Terraform (ou OpenTofu) et Terratest
Pour rappel, Terraform est un outil open-core développé par HashiCorp. OpenTofu est, quant à elle, l’alternative libre portée par la communauté open source en réponse au changement de mode de licence intervenu pour Terraform en milieu d’année 2023.
Ces deux outils permettent de définir une infrastructure à l’aide d’un langage de haut niveau, le HCL, puis de la déployer sur de nombreux fournisseurs de solutions cloud voire même on-premise grâce à ses très nombreux providers.
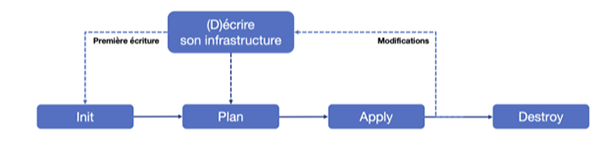
Lorsque nous souhaitons déployer une nouvelle machine virtuelle ou un conteneur, nous pouvons avoir recours à cette solution. Elle repose sur le workflow présenté en Figure 4.
Pour valider que l’infrastructure générée soit en phase avec nos attentes, il n’est pas rare de constater que l’administrateur se connecte à l’aide une console web ou d’une interface en ligne de commandes pour effectuer certains contrôles, vérifier la présence de certains fichiers, etc.
Le mode de fonctionnement de Terraform / OpenTofu autorise la destruction simple et une nouvelle itération le cas échéant… dès lors, comment éviter ces contrôles manuels pour corriger nos erreurs et comment automatiser ce processus ? La réponse passe par l’utilisation de Terratest.
Cet outil est une librairie Go open source, développée par la société américaine Gruntwork (un partenaire de HashiCorp), qui facilite l’écriture et l’automatisation de tests. Elle se destine donc à être combinée avec Terraform / OpenTofu.
La solution est disponible au téléchargement sur GitHub à l’adresse URL suivante : https://github.com/gruntwork-io/terratest.
L’intérêt de cette bibliothèque est qu’elle va nous permettre d’écrire des tests de bout en bout, de documenter notre infrastructure et de disposer de retours rapides sur nos tests. Le site de l’éditeur de cette solution logicielle regorge d’ailleurs d’exemples qui permettent de démarrer rapidement avec l’outil.
Nous avons découvert, dans les lignes précédentes, la Mantra au cœur de TDD. Comment pouvons-nous mettre en œuvre celle-ci dans le processus d’écriture de notre manifeste Terraform ?
3.2 La démarche, en pratique, avec Terratest
Pour notre premier exemple, nous souhaitons déployer un conteneur Docker à l’aide de Terraform sur notre machine locale. Ce conteneur est une image du serveur web nginx qui répondra aux requêtes émises par les clients sur le port 9000 en tcp. Nous procéderons par étapes successives pour coller à la méthode TDD.
Il vous faudra donc, en premier lieu, récupérer tous les binaires nécessaires à cette opération. La documentation en ligne de Go précise comment l’installer sur votre hôte : https://go.dev/doc/install.
Nous procéderons de la même manière pour Terraform, que vous pourrez télécharger à l’adresse URL ici après : https://www.terraform.io/downloads.
Enfin, pour Docker, vous pourrez le déployer sur votre hôte en suivant les instructions de la documentation en ligne, disponible à cet emplacement : https://docs.docker.com/get-docker/.
Dans le cadre de la rédaction de cet article, notre pile technique repose sur plusieurs composants open source (ou open-core). Dans le détail, j’ai utilisé la version 1.8.5 de Terraform, la version 1.22.4 de Go et la bibliothèque Terratest en version 0.46.15, puis enfin la version 26.1.4 de Docker pour l’exemple.
En termes de prérequis, il vous faudra d’abord installer Go, puis la bibliothèque Terratest… et terminer par le(s) module(s) que vous utiliserez. Commençons par créer un nouveau module Go dans le répertoire test de notre projet à l’aide d’une invite de commandes :
Installons maintenant Terratest et la bibliothèque d’outils testify qui comprend, en outre, des instructions utiles à l’écriture de tests unitaires : nous utiliserons essentiellement le mécanisme d’assertion (assert). Ces étapes sont aussi à réaliser en ligne de commandes :
Une fois ces actions exécutées, la seconde étape consiste à écrire un fichier de test en Go avec un suffixe en _test.go. Nous veillerons à utiliser des assertions (vraies, fausses, égalités, etc.) afin de vérifier que les tests ne passent pas.
Pour l’exemple, nous créerons le fichier docker_lp_test.go que nous placerons dans le répertoire test de notre projet. Son contenu est le suivant :
Si nous exécutons les tests que nous venons d’écrire, celui-ci devrait échouer. Impossible donc d’évaluer correctement l’assertion présente en ligne 49, par exemple.
C’est tout à fait « normal » puisque, pour le moment, nous n’avons pas réfléchi au code Terraform qui vise à satisfaire les tests écrits. Vous devriez donc obtenir une trace d’échec similaire à celle-ci :
L’obtention d’un FAIL dans notre cas, en retour sur la ligne de commandes, est tout à fait normale puisque le code qui correspond à l’infrastructure n’a pas encore été écrit.
Dans un second temps, nous passerons donc à l’écriture de notre manifeste Terraform / OpenTofu. Celui-ci décrira notre infrastructure (qui peut être ou non complexe). Nous essaierons de garder une structure modulaire pour respecter cette notion de simplicité au cœur de la philosophie du TDD.
Pour l’exemple, nous provisionnerons un conteneur Docker simple qui exécutera l’image officielle du serveur web nginx. Nos manifestes pour Terraform seront stockés dans un répertoire nommé docker-nginx. Ils ressembleront donc à cela :
Nous rédigeons ce fichier main.tf qui décrit la manière dont provisionner le conteneur Docker. Un réseau dédié est créé pour l’occasion.
Le fichier compagnon variables.tf décrit l’ensemble des variables qu’il faut provisionner afin que le projet Terraform s’exécute convenablement.
Enfin, la ligne 01 du fichier ./docker-nginx/outputs.tf permet de référencer une variable utilisée à la ligne 28 de notre manifeste de test docker_lp_test.go. Elle fait référence au port tcp utilisé par défaut par l’application déployée.
De manière générale, le fichier ./docker-nginx/outputs.tf est utilisé pour indiquer des valeurs, issues de l’exécution du manifeste main.tf qui peuvent être exploitées après la passe apply réalisée via Terraform.
Pour l’heure, vous devriez donc avoir une arborescence de projet qui ressemble à cela :
À l’issue de cette phase, nous exécuterons à nouveau Terratest à l’aide de la commande go test. Ce nouvel appel aura pour effet de mettre effectivement en place l’infrastructure et d’exécuter les différents tests que nous avons écrits (contacter des routes HTTP, télécharger des fichiers à un emplacement donné, exécuter des commandes sur le système, lire les outputs de Terraform, etc.).
Après quelques secondes, nous pouvons constater que le résultat est tout à fait différent du premier : nous obtenons un PASS sur la sortie standard, ce qui signifie que les tests unitaires ont été réalisés avec succès !
L’étape finale de Test Driven Development est d’essayer de simplifier, tant que possible, notre code … et de relancer notre chaîne de tests pour vérifier que tout est OK : c’est un processus d’amélioration continue !
Ainsi, nous pourrions imaginer modifier le contenu du fichier docker_lp_test.go de manière à supprimer l’assertion en ligne 49, supprimer l’utilisation de la variable en lignes 37 et 46 puis modifier la fonction de retour en ligne 47 comme suit :
Une nouvelle exécution de la commande go test docker_lp_test.go aura pour effet de provisionner à nouveau l’infrastructure… et de valider à nouveau les tests modifiés !
Nous avons atteint notre objectif en écrivant un manifeste Terraform assez basique qui permet finalement de satisfaire un code de test que nous avons écrit dans les lignes précédentes.
Notez que ce processus se termine, dans notre cas, par la destruction de l’infrastructure provisionnée avec notre outil d’IaC et l’affichage du résultat de ces tests dans la console. Alors, pratique, non ? Mais cela ne s’arrête pas là, bien au contraire !
4. Pratiquer le TDD pour déployer des services sur son infrastructure
Peut-être que, comme moi, vous décrivez déjà le déploiement de vos services et de vos applications à l’aide d’un outil comme Ansible ? Personnellement, j’adore cet outil : sa courbe d’apprentissage n’est pas abrupte… et une fois « maîtrisé », vous parvenez à écrire des manifestes (les playbooks) Ansible presque aussi rapidement que des commandes bash… et parfois même plus vite grâce à la couche d’abstraction qu’il apporte.
Cela vous permet de tout automatiser sur le plan de la configuration de vos services, et ceci dès le début de votre projet. L’outil présente aussi l’avantage d’autoriser le stockage de ses playbooks dans un dépôt git, ce qui facilite la collaboration. Enfin, il est assez agnostique de son contexte d’appel initial : il peut être utilisé depuis un environnement Microsoft Windows, GNU/Linux ou macOS sans difficulté majeure.
Le sujet du développement dirigé par les tests ne serait pas complet si je ne vous parlais pas de Molecule [5], le compagnon idéal pour Ansible lorsqu’il s’agit de valider vos manifestes ! Cet outil libre, distribué sous les termes de la licence MIT et écrit en Python, est le compagnon, au quotidien, d’Ansible quand vous vous inscrivez dans une démarche de type TDD pour déployer vos services.
Il faut voir celui-ci comme un framework qui permet d’aider au développement et aux tests de collections, playbooks ou rôles.
La documentation de cet outil précise d’ailleurs que le fruit de votre travail, avec Molecule, vous permet d’obtenir des manifestes bien écrits, facilement compréhensibles et surtout maintenables !
4.1 Présentation générale de Molecule
Molecule permet donc de s’inscrire dans une démarche de type TDD grâce à son mode de fonctionnement naturel. Il repose sur trois notions fondamentales :
- instance : élément de l’infrastructure dans lequel est exécuté votre contenu Ansible (VM, conteneur, etc.) ;
- driver : composant qui permet de créer ou de détruire un type d’instance (via Vagrant, Podman, n’importe quelle plateforme grâce au driver délégué [6], etc.) ;
- scenario : ensemble de suite de tests à exécuter sur une ou plusieurs instances.
Le processus global de mise en œuvre de la démarche de tests s’appuie donc sur l’écriture d’un scenario.
Lorsque vous faites le choix d’utiliser Molecule, vous devriez toujours avoir un scenario nommé default qui permet de tester votre rôle avec Molecule sur plusieurs distributions, avec des paramètres de configuration différents.
La structure d’un scenario minimaliste ressemble donc à cela :
L’outil s’appuie sur une série de fichiers au format YAML. Chaque fichier assure une fonction spécifique.
Le fichier de configuration principal se nomme molecule.yaml. Il comporte, en son sein, la configuration de chacun des composants mobilisés par Molecule. L’exemple ci-dessous montre comment se servir de Docker avec Molecule pour tester son rôle :
La ligne 01 permet d’indiquer quel gestionnaire de dépendances utiliser. Dans notre cas, nous nous servirons d’Ansible Galaxy pour fournir les rôles et/ou collections nécessaires.
À la ligne 04, l’instruction driver permet de spécifier la nature de l’instance sur laquelle sera exécuté notre manifeste de test.
La ligne 06 fait écho à la ligne 04. Elle permet de spécifier explicitement le type d’instance à utiliser. Dans la mesure où nous avons fait le choix d’utiliser Docker pour cet exemple, la ligne 08 permet de préciser quelle image sera mise en œuvre pour notre scénario de test.
Enfin, les lignes 10 et 12 nous permettent d’indiquer quelle application gérera le cycle de vie du test et les états associés. En l’occurrence, il s’agit d’Ansible dans notre cas. Nous combinerons donc différents outils pour arriver au résultat exprimé pour notre IaC.
Molecule supporte plusieurs commandes pour interagir avec lui. La commande create va déclencher le provisionnement de votre infrastructure de test (via Vagrant, Docker, etc.) telle que vous l’avez définie dans votre fichier molecule.yml. La commande destroy réalise, quant à elle, l’opération inverse.
Une fois votre support d’accueil instancié, vous pouvez faire appel à la commande converge afin de démarrer la phase d’évaluation de vos playbooks. Elle invoque et demande l’évaluation des contenus présents dans les fichiers prepare.yml et converge.yml.
Pour démarrer l’évaluation de votre scénario, il vous faudra invoquer la commande test. Son appel induit l’exécution de ce qui est décrit dans le fichier converge.yml, l’évaluation de ce qui est présent dans le fichier verify.yml et la destruction de l’instance une fois les tests effectués. Ces vérifications reposent d’ailleurs sur les assertions que vous aurez indiquées dans vos manifestes.
Dans cette phase, vous pourrez d’ailleurs utiliser un outil dont nous avons parlé récemment : il s’agit de Testinfra, ce framework de tests unitaires qui repose sur les fondements de pytest.
Enfin, vous pouvez utiliser la commande login pour ouvrir un shell interactif au sein de l’instance provisionnée. Cela peut être particulièrement utile à des fins de dépannage.
Bien entendu, la combinaison de ces outils autorise la mise en œuvre d’un cycle d’amélioration continue, démarche au cœur de la méthode de Test Driven Development. Comment est-il possible de mettre en œuvre ces outils pour concourir au déploiement d’un service ? C’est ce que nous allons voir dans les prochaines lignes !
4.2 Déployer un service façon TDD en s’appuyant sur Molecule
Vous pourrez télécharger Molecule à l’adresse URL ci-après : https://github.com/ansible/molecule. Je me suis appuyé sur la version 24.6.0 de l’outil.
Dans notre contexte, je ne rentrerai pas en détail sur la manière dont installer Docker, Testinfra, Molecule ou encore Ansible sur votre poste de travail. Je vous renvoie pour cela, aux excellents articles parus précédemment dans les colonnes de Linux Pratique (les références figurent à la fin de cet article) ainsi qu’aux documentations en ligne des différentes solutions.
Je pars donc de l’hypothèse que vous disposez d’un ordinateur exécutant GNU/Linux Ubuntu 24.04 et que les outils évoqués sont déjà installés et que votre compte utilisateur vous permet d’exécuter Docker et le reste de la pile technique.
Pour rappel, la première étape de la méthode Test Driven Development consiste à écrire des tests qui vont échouer. Dans un second temps, nous écrirons le code métier qui permet de déployer notre service. Nous reprendrons l’exemple précédent, qui est relativement simple : disposer d’un serveur web Apache dans un environnement serveur de type Debian.
Imaginons que nous venons de développer un playbook Ansible qui permet de déployer un serveur web Apache sur un de nos serveurs. La première chose à faire est de créer un nouveau scénario Ansible : le contrôle de sa conformité sera ainsi confié à Molecule.
L’arborescence cible de notre projet ressemblera à cela :
Nous devons donc écrire les tests au cœur du projet, puis trouver un moyen technique de les satisfaire à l’aide d’Ansible. Je vous propose, par commodité, de réutiliser le fichier molecule.yml dont le détail vous avait été donné quelques lignes auparavant.
Si, comme moi, vous souhaitez évaluer la qualité de vos manifestes Ansible, je vous recommande l’utilisation des images Docker conçues par Jeff Geerling (voir https://hub.docker.com/r/geerlingguy/docker-debian12-ansible pour les détails sur l’utilisation). Elles sont modifiées pour se comporter comme les machines virtuelles que vous pourriez déployer traditionnellement. Dans notre cas, il s’agit d’une image Debian Bullseye (v12), comme le montre l’information à la ligne 08 du fichier de référence.
Passons maintenant à l’écriture du playbook nommé prepare.yml. Son contenu est le suivant :
Ce playbook définit l’ensemble des tâches préalables à l’exécution du playbook principal converge.yml. Dans notre cas, nous l’utilisons pour nous assurer que le cache des paquets apt est bien à jour.
Ensuite, nous définissons le contenu Ansible qui sera évalué dans le cadre du test avec Molecule dans le fichier converge.yml. Cela peut-être un rôle, une collection ou un simple playbook. Ci-après le contenu de ce fichier :
Enfin, le dernier manifeste, nommé verify.yml, est exécuté à l’issue de l’étape précédente (après l’appel de converge.yml). Ce playbook contient l’ensemble des tâches de vérification : cela permet de s’assurer que les opérations demandées par le biais d’Ansible, cette fois, ont bien été appliquées correctement, grâce notamment aux assertions !
Nous pouvons invoquer la phase de tests dans un terminal, à l’aide de la commande ci-après : molecule test. Après quelques secondes, vous remarquerez que celle-ci échouera, car le fichier playbook.yml n’est pas présent...
Ce comportement est tout à fait normal et même attendu ! Souvenez-vous : si nous respectons la logique TDD, il nous faut d’abord écrire nos différents tests puis le code décrivant le déploiement… en veillant à ce que celui-ci réponde aux tests exprimés précédemment.
Pour l’exemple, je vous propose de créer le fichier playbook.yml dont le contenu est le suivant :
Je vous propose maintenant d’exécuter à nouveau la commande molecule test afin de provoquer le déroulement du scénario de test. Vous devriez, quelques secondes plus tard, obtenir la trace suivante sur la sortie standard :
(300 retries left).
Félicitations ! Vous venez juste de valider votre playbook en vous inscrivant dans l’utilisation de Test Driven Development avec Molecule. Au regard du contenu présent dans le fichier playbook.yml, nous ferons l’impasse sur la partie refactoring… mais n’oubliez pas qu’il s’agit d’un processus d’amélioration continue… et qu’un nouveau cycle s’imposerait pour optimiser le déroulement de vos opérations !
Maintenant, vous disposez des bases pour maquetter et déployer de manière fiable, en production, des infrastructures et des services plus robustes ! À vous de jouer !
Conclusion
Nous venons de voir qu’adopter une démarche de développement dirigé par les tests pour l'infrastructure permet donc de bénéficier des mêmes avantages que pour le développement logiciel : une meilleure qualité, une plus grande fiabilité et une détection précoce des erreurs.
Même si cela impose une forme de rigueur, tant sur le pilotage que sur le contenu d’un projet, vous pouvez grandement y gagner sur le long terme, croyez-en mon expérience ! Cela facilite également la maintenance sur le long terme, mais aussi la collaboration entre les administrateurs d’une même équipe. Ce sont des atouts auxquels il convient de réfléchir dans une démarche d’industrialisation de sa production.
Attention toutefois, il ne faut pas assimiler TDD à l’assurance qualité dans un projet... même si d’une certaine manière, il y contribue. C’est plutôt un état d’esprit dans lequel l’administrateur s’inscrit. Celui-ci doit absolument s’attacher à déterminer et préciser les comportements donnés dans le cadre d’un processus global de déploiement de son infrastructure et des services associés… mais le jeu en vaut vraiment la chandelle !
Références
[1] K. Beck, « Test Driven Development : By Example », Addison-Wesley Professional, 2002
[2] J. Morot, « Utilisez Terraform pour vos projets Docker », GNU/Linux Magazine n°240, septembre 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-240/utilisez-terraform-pour-vos-projets-docker
[3] R. Pelisse, « Introduction à l’automatisation avec Ansible », Linux Pratique HS n°57, avril 2023 : https://connect.ed-diamond.com/linux-pratique/lphs-057/introduction-a-l-automatisation-avec-ansible
[4] M. Masquelin, « Écrire des tests unitaires orientés systèmes et services avec Testinfra », Linux Pratique n°144, juillet-août 2024 : https://connect.ed-diamond.com/linux-pratique/lp-144/ecrire-des-tests-unitaires-orientes-systemes-et-services-avec-testinfra
[5] J. Delamarche, « Comment tester un rôle Ansible avec Molecule », Linux Pratique n°128, novembre-décembre 2021 : https://connect.ed-diamond.com/linux-pratique/lp-128/comment-tester-un-role-ansible-avec-molecule
[6] R. Pelisse, « Conception d’un pilote délégué pour Molecule », Linux Pratique n°133, septembre 2022 : https://connect.ed-diamond.com/linux-pratique/lp-133/conception-d-un-pilote-delegue-pour-molecule