

Smartphones, IoT, IVI... : découvrez comment les futures générations de processeurs ARM permettront de durcir vos programmes contre les corruptions mémoires.
Buffer overflows, use-after-free, ROP-chain, voici des mots qui résonnent dans le monde de la sécurité informatique depuis des décennies. Malgré toutes les techniques de défense existantes, nous continuons de nous y intéresser en 2020, car il y a toujours de la place pour la nouveauté. Dans cet article, je vous propose de vous intéresser à de nouveaux mécanismes de protection contre les corruptions mémoire introduits dans les dernières spécifications des processeurs ARM : « Pointer Authentication (PA ou PAC) », « Branch Target Identification (BTI) » et « Memory Tagging Extension (MTE) ».
1. Inventaire rapide des mécanismes de protection actuels
Les bugs de gestion mémoire sont inhérents aux programmes développés en C/C++. Bien que les logiciels de preuve de code essaient d’apporter une solution à ce problème, les contraintes liées à leur apprentissage et leur utilisation rendent cette adoption trop coûteuse pour qu’ils soient largement utilisés. Les langages modernes comme Go, Swift ou Rust apportent des garanties sur la gestion mémoire pour éliminer des classes entières de bugs, mais leur adoption reste timide et ne remplacera pas aujourd’hui ni demain les millions de lignes de code C/C++ existantes. Et ce n’est pas demain que le C sera remplacé tant l'écosystème autour de celui-ci est implanté dans l’industrie. Il nous faut donc vivre avec ce constat et limiter au maximum la probabilité de compromission de nos programmes.
Pour détecter les bugs avant la mise en production d’un programme, deux types d’analyses peuvent être lancées :
- L’analyse du code source par les compilateurs et autres outils tels que cppcheck, qui permettent d’éliminer une première couche de défauts. Toutefois, ces outils atteignent très vite leurs limites sur les bugs de gestion mémoire.
- L’analyse dynamique via l’instrumentation du code par des outils comme valgrind ou ASAN qui permettent de détecter tout bug mémoire apparaissant lors d’une exécution du programme. Plus la couverture des tests est large, plus la probabilité de tomber sur un bug est forte. L’utilisation d’outils de fuzzing permet d’augmenter cette couverture et donc cette probabilité de détection. Le surcoût mémoire et l'impact sur la performance ne permettent pas l’utilisation de ces outils en production (ou sur des populations ciblées).
Pour protéger les programmes une fois dans les mains de leurs utilisateurs, différentes défenses peuvent être mises en place. Citons par exemple les stack canaries, la randomisation de l'espace mémoire (ASLR), ou encore la vérification de l'intégrité du flot d'exécution (CFI), défenses apportées par un support du compilateur ainsi que du système d’exploitation sous-jacent.
En soutien à ces mesures logicielles, les processeurs apportent eux aussi des mécanismes de protection. Sur les processeurs ARM, nous pouvons citer les flags UXN, PXN ou PAN qui permettent de limiter les capacités d'exploitation de vulnérabilités en mode utilisateur (pour UXN) ou en mode noyau (pour PXN et PAN). Un autre exemple est le registre SCTLR_ELx permettant de rendre non-exécutable toute mémoire ayant des droits d'écriture (le fameux W^X), typiquement la pile et le tas.
Dans la suite de cet article, nous allons découvrir deux mécanismes de protection contre les attaques en production : PAC et BTI, et un mécanisme de détection de bugs : MTE.
2. Pointer Authentication - ASLR next-gen ?
2.1 Principe
Introduit en 2016 avec l'architecture ARMv8.3, le mécanisme de Pointer Authentication - plus communément appelé PA ou PAC pour Pointer Authentication Code, a pour objectif d'ajouter un contrôle supplémentaire lors de l'utilisation des pointeurs mémoire. À l'instar de l'ASLR, cette mesure complique l’exploitation des corruptions mémoire, typiquement utilisées pour détourner le flot de contrôle du programme ciblé via des attaques de type ROP.
La différence fondamentale entre PAC et ASLR est la résistance à la fuite mémoire. Dans le cas de l'ASLR, toute la protection tombe lors de la fuite d'un ou de plusieurs pointeurs (dépendant de la granularité de l’ASLR mise en place sur le système). Comme vous allez le découvrir par la suite, ce ne sera pas le cas avec PAC.
Uniquement disponible sur architecture AArch64, le PAC utilise une partie inutilisée des 64 bits des adresses de mémoire virtuelle. En pratique, seule une partie de ces 64 bits est réellement nécessaire, le reste est ainsi rendu disponible pour sauvegarder des métadonnées sur ce pointeur.
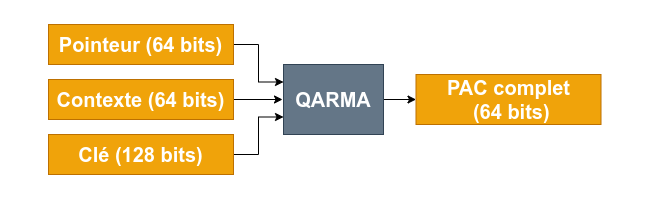
Le principe est relativement simple : les pointeurs sont signés cryptographiquement, la signature (le PAC) est ajoutée comme métadonnée dans le pointeur lui-même, et revérifiée avant utilisation. La génération du PAC se fait à partir de 3 entrées :
- l'adresse mémoire à authentifier (64 bits) ;
- une clé symétrique enregistrée dans un registre dédié (128 bits) ;
- une entrée supplémentaire appelée contexte (64 bits).
L'algorithme tel que spécifié dans la documentation ARM est QARMA, un chiffrement par bloc léger (bonnes performances et faible empreinte mémoire), personnalisable (utilisation d'une clé et d'une entrée supplémentaire) et fonctionnant avec des clés de 128 à 256 bits.
Notez que le choix d'utilisation de cet algorithme cryptographique reste toutefois à la discrétion du concepteur du processeur (Apple a par exemple choisi un algorithme propriétaire pour ses iPhones d'après l'étude menée par Google Project Zero).
Sans accès à la clé, il est impossible à un attaquant de corrompre un pointeur sans invalider la signature, typiquement dans le cas d'un stack buffer overflow.
2.2 Fonctionnement
Pour générer et valider le PAC, un jeu d'instructions dédié a été introduit. Il peut être résumé en 3 catégories :
- PAC* : calcule et ajoute le PAC à une adresse mémoire.
- AUT* : vérifie et supprime le PAC d'une adresse mémoire. Si le PAC est invalide, deux bits sont gardés à 1, rendant le pointeur invalide et tout accès à celui-ci générera une Translation Fault, car invalide dans l'espace d’adressage virtuel.
- XPAC* : supprime le PAC sans aucune vérification.
D'autres instructions, combinaisons d'une instruction classique et d'une opération PAC sont également introduites :
- BLRA* : combinaison AUT+BLR. Vérifie/supprime le PAC du pointeur dans le registre cible et effectue un saut vers cette adresse.
- LDRA* : combinaison PAC+LDR. Vérifie/supprime le PAC du pointeur et charge la donnée en mémoire vers le registre cible.
- RETA* : combinaison AUT+RET. Vérifie/supprime le PAC du pointeur contenu dans le registre LR et effectue un saut vers cette adresse.
Le support du compilateur est donc nécessaire pour introduire ces instructions aux bons endroits.
La spécification ARM permet l'utilisation de cinq clés de 128 bits différentes pour la génération du PAC :
- APIAKey et APIBKey pour les pointeurs d'instruction ;
- APDAKey et APDBKey pour les pointeurs de données ;
- APGAKey pour la signature de larges blocs de données via l'instruction PACGA.
Ces clés sont enregistrées dans des registres du processeur et uniquement accessibles par les contextes d'exécution privilégiés (EL1, EL2 et EL3). Un processus s'exécutant en EL0 (mode utilisateur) ne pourra pas accéder à ces clés. Le rôle du système d'exploitation étant de gérer des ensembles de clés différents pour chaque tâche ou groupe de tâches du système.
Le choix de la clé et du contexte dépend de l'instruction. Voici quelques exemples :
- PACIA X1, X2 : génération d'un PAC sur le registre X1 (pointeur d'instruction) avec la clé APIAKey et X2 comme contexte ;
- PACIZA X1 : génération d'un PAC sur le registre X1 avec la clé APIAKey et la valeur zéro comme contexte ;
- PACDB X1, X2 : génération d'un PAC sur le registre X1 (pointeur de donnée) avec la clé APDBKey et X2 comme contexte ;
- PACDZB X1 : génération d'un PAC sur le registre X1 avec la clé APDBKey et la valeur zéro comme contexte ;
- PACIASP : génération d'un PAC sur le registre LR avec la clé APIAKey et le registre SP comme contexte ;
- AUTIASP : validation d'un PAC avec les mêmes paramètres que PACIASP.
Ainsi, un ajout de PACIASP en prologue de fonctions et de AUTIASP en épilogue permet de protéger les adresses de retour sur la pile contre les stack buffer overflows.

Le paramètre additionnel (le contexte) permet de durcir la protection du PAC. Une des limites de ce mécanisme est la réutilisation de pointeurs. Une fois que l’attaquant a réussi à extraire des pointeurs via une fuite mémoire, il peut tout à fait remplacer un pointeur par un autre, tous deux avec un PAC valide, et ainsi détourner le flot d'exécution à son avantage. L’utilisation du SP comme contexte dans l’exemple ci-dessus permet de lier le PAC à la position actuelle du programme dans la pile. Il n’est donc plus possible de remplacer un pointeur si les valeurs du SP ne coïncident pas.
Bien que le PAC généré par QARMA soit d'une taille de 64 bits, seule une partie est réellement gardée. En effet, la quantité de bits disponible dans l'adresse virtuelle dédiée à la sauvegarde du PAC dépend de la configuration de l'espace mémoire ainsi que de l'activation d'autres fonctionnalités telles que le MTE (présenté en deuxième partie de cet article). La taille du PAC peut ainsi varier de 11 à 31 bits avec un MTE désactivé, et de 3 à 23 bits dans le cas contraire. Pour comparaison, l'implémentation de l'ASLR sur Linux 64 bits utilise en majorité 28 bits d'entropie, et un peu plus sur un système durci.

ASRL et PAC sont des mécanismes complémentaires et se partagent les bits disponibles dans les pointeurs. Plus l’espace d’adressage est grand, plus l’entropie de l’ASLR est grande, mais plus petit sera le nombre de bits disponible pour enregistrer le PAC. Et inversement.
2.3 Exemple de PAC sur les SoC d'Apple
Au moment de l'écriture de cet article, seul Apple a franchi le pas d'introduire PAC dans le compilateur Clang et sur ses terminaux, depuis le SoC A12 de l'iPhone XS. Ce dernier a par ailleurs fait l’objet d’une analyse minutieuse par l'équipe Project Zero de Google. À travers la publication de leurs travaux, il a été mis en évidence certaines modifications de l'implémentation du PAC dans un objectif de durcissement.
D'une part, l'algorithme de génération de PAC utilisé n'est pas QARMA, et d'autre part, l'algorithme de génération de PAC diffère entre les différentes instructions. Pour une même clé secrète, l'utilisation de PACDZB et PACIZB donne des résultats différents. C'est une intéressante propriété de durcissement dans le cas d'un algorithme cryptographique secret.
Armés de primitives d'écriture et de lecture mémoire en espace noyau, l'exécution de code noyau fut un véritable challenge et le seul défaut trouvé permettant d'arriver à une véritable compromission fut un gadget effectuant une conversion du PAC d'un pointeur (utilisation de AUTIA pour valider le PAC, suivie d'un PACIZA pour regénérer un nouveau PAC). Il s'est avéré que ce gadget pouvait en réalité être utilisé comme oracle de génération de PAC (IZA) pour n'importe quel pointeur donné.
2.4 Limites du PAC
Une des limites du PAC est la réutilisation de pointeurs signés. L’utilisation d’un contexte permet de réduire la probabilité que ce problème ne survienne. Il permet aussi de limiter la possibilité d’utilisation d’oracle de signature en les liant à un contexte particulier.
Une deuxième limite est le périmètre d’application du PAC par les compilateurs. Protéger l’adresse de retour reste relativement simple. Protéger les pointeurs de fonctions suivant les différents cas d’utilisation (tableaux de pointeurs, callback, v-tables) peut se révéler plus complexe à mettre en place. Il se peut que certains cas ne soient pas encore supportés par les chaînes de compilation actuelles et laissent la voie libre aux attaques JOP.
Enfin, une troisième limite est la protection des pointeurs de données. Protéger ces pointeurs à chaque modification et les vérifier à toute utilisation risque d’engendrer une forte dégradation des performances. Pour ce type de pointeurs, une application plus ciblée est nécessaire afin d’appliquer les protections uniquement aux endroits ciblés. Cela peut se faire de manière manuelle via des primitives apportées par le compilateur (e.g. ptrauth_auth_function() dans le SDK Apple).
Il convient donc d’appliquer PAC en combinaison avec l’ASLR pour bénéficier des protections offertes par ces deux mécanismes.
3. Branch Target Identification : une piste d’atterrissage contre les JOP
BTI, pour Branch Target Identification, est un mécanisme de Control-Flow Integrity, matériel introduit avec ARMv8.5 contre des attaques logicielles et en particulier contre les attaques de type JOP (Jump Oriented Programming), utiles quand les conditions d’exploitation ne permettent pas la mise en place de ROP. Une fois ce mécanisme activé, le processeur effectue une vérification supplémentaire avant tout saut indirect vers une adresse contenue dans un registre (instruction de type BR Xn ou BLR Xn). Il va s’assurer que l’instruction destination correspond à une « piste d’atterrissage » valide et donc une destination de saut autorisée.
Une piste d’atterrissage valide correspond à une instruction BTI (nouvelle instruction introduite avec ce mécanisme) ou une instruction de type PACIxSP ou PACIxZ pour le support de PAC (bien vu !).

Dans l’exemple illustré en figure 4, si le registre x8 venait à être contrôlé par un attaquant, celui-ci serait contraint aux entrées de fonctions et ne pourrait plus mener au milieu d’un morceau de code, astuce permettant d’enchaîner efficacement des « JOP gadgets ».
Pour qu’un programme fonctionne, il est donc nécessaire de le recompiler avec les options appropriées de manière à insérer les pistes d’atterrissage à tout début de fonction et autres endroits appropriés.
Il reste toutefois possible de remplacer cette adresse destination par une autre adresse valide (p. ex. remplacer un appel à puts() par appel à system()) et ainsi détourner le flot d’exécution à son avantage. Pour un contrôle plus fin des adresses destinations acceptables, la protection ARM BTI peut être complétée par d’autres solutions telles que le forward-edge CFI supporté par Clang basé sur la signature des fonctions : type de retour et type des paramètres (le lecteur avisé notera que même avec cette deuxième protection, le remplacement de puts fonctionnera toujours étant donné qu’elles partagent la même signature !).
Note : la granularité du BTI permet de différencier les appels de fonctions (BLR) et les sauts liés à des « switch-case » (BR) via des instructions différentes (BTI C/J/JC).
4. Compilation de code avec PAC et BTI
Le support de PAC et BTI est arrivé dans les versions récentes de GCC et Clang à travers l’option -mbranch-protection. Celle-ci supporte différentes valeurs :
- pac-ret : ajoute les instructions PAC pour protéger les adresses de retour sur la pile ;
- bti : ajoute des instructions BTI en début de fonction ;
- standard : active pac-ret et bti.
Étant donné le morceau de code ci-dessous, observons les résultats de la compilation avec sur différentes versions de processeurs.
Avec -march=armv8.5-a, nous observons :
- l’ajout des fonctions PACIASP et RETAA à la fonction main() permettant de protéger l’adresse de retour sur la pile ;
- aucune instruction PAC dans la fonction foo(). Celle-ci étant une fonction terminale (sans sous-appel de fonction), le registre LR (x30) n’est pas sauvegardé sur la pile et n’a donc pas besoin d’être protégé ;
- une instruction BTI au début de foo() pour autoriser tout appel indirect vers celle-ci (même si ce n’est pas le cas ici) ;
- aucune instruction BTI au début de main(), PACIASP fait office de piste d’atterrissage valide.
Avec -march=armv8.3-a, un changement dans la sortie de Clang peut être observé : l’instruction BTI C devient HINT #34. C’est en fait la même instruction, mais différemment affichée. En effet, sans le support du BTI avec ARM-8.5, cette instruction devient une instruction de type HINT ou NOP sur les processeurs de version antérieure et n’a donc aucun effet sur le déroulement du programme.
Avec -march=armv8.2-a :
- l’instruction PACIASP devient HINT #25 pour la même raison qu’énoncée ci-dessus ; le support de PA arrivant avec ARMv8.3 ;
- l’instruction RETAA est transformée en deux instructions HINT #29 puis RET. L’instruction HINT #29 correspond à une instruction AUTIASP. Cette transformation permet la rétrocompatibilité du programme sur des processeurs sans support de PA, mais profitant de cette protection sur les processeurs plus récents (les instructions HINT #25 et HINT #29 devant respectivement PACIASP et AUTIASP.
5. MTE pour une détection efficace des bugs mémoire
5.1 Détection de bugs avec ASan
ASan (Address Sanitizer) est un mécanisme de détection de bugs mémoire dynamique (lors de l'exécution). Ce mécanisme modifie le programme à analyser de manière à détecter différentes classes de bugs tels que les dépassements de tampons ou les utilisations de mémoire désallouée. Pour cela, ASan se base sur une instrumentation du code par le compilateur.
Le fonctionnement est simple : une zone mémoire appelée shadow memory est allouée en début d'exécution et représente l'espace mémoire du processus. Chaque morceau de 8 octets de l'espace virtuel est représenté par 1 octet. Avec ces 8 bits de métadonnées, il est possible de préciser l'état de chacun de ces morceaux de mémoire. Typiquement, les plages de mémoire valide appartenant au tas ou à la pile ainsi que des morceaux invalides tels que des zones mémoires désallouées.
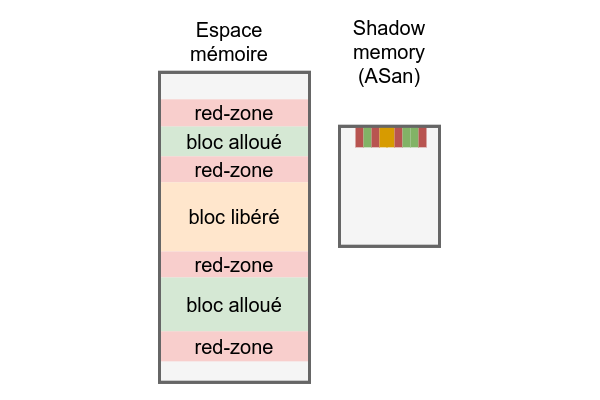
Avec l'activation de l'option -fsanitize=address : le compilateur (tel que Clang ou GCC) ajoute un appel de routine de validation ASan avant tout accès mémoire. Cette routine permet de vérifier si l'accès à cette zone mémoire est valide en observant la métadonnée associée dans la shadow memory. Les fonctions de gestion mémoire malloc, free, realloc sont quant à elles remplacées par des fonctions similaires, mais avec mise à jour de la shadow memory à chaque opération.
Grâce à ces modifications, les use-after-free sont directement détectés, ou presque... Pour assurer une meilleure détection, un mécanisme de quarantaine est ajouté, gardant ces zones non allouées pendant un certain temps. Cela permet de s'assurer qu'elles ne sont pas réallouées trop rapidement et qu'un use-after-free passe inaperçu.
Pour la détection des dépassements de tampon, ASan ajoute des zones mémoires interdites — ou red-zone — entre chaque zone mémoire allouée dans le tas et même autour des buffers sur la pile. Ainsi, tout débordement de tampons est détecté, ou presque... D'une part, les zones interdites sont alignées sur 8 octets, si le dépassement n'atteint pas cet alignement, il ne sera pas détecté. D'autre part, si le dépassement traverse la zone interdite et atterrit sur le bloc suivant, il ne sera probablement pas détecté non plus.
Enfin, voilà notre programme bien surchargé ! Entre les routines de gestion de la shadow memory, les routines de vérification à chaque accès mémoire, l'ajout de zones interdites dans la pile et dans le tas, et enfin la gestion de la quarantaine des pointeurs désalloués, ASan induit un surcoût de consommation mémoire et de perte de performance CPU clairement non négligeable.
Mais malgré ces limites, ASan se révèle un atout essentiel lors d'une campagne de tests ou de fuzzing, permettant de détecter au plus tôt des bugs mémoire avant qu'ils n'arrivent sur le terrain. Certains développeurs utilisent même ce type de mécanisme de manière parsemée dans une flotte de machines pour ne pas ralentir substantiellement le service global, mais pour tout de même permettre de détecter des problèmes en environnement prod, ce qui est très intéressant et pas forcément reproductible en environnement de test.
5.2 HWAsan : le Memory Tagging pré-MTE sur AArch64
HWAsan (pour HardWare ASan) est une variante de ASan plus performante et fonctionnant uniquement sur les architectures ARM AArch64.
Pour fonctionner, il utilise le TBI (Top Byte Ignore), une fonctionnalité permettant d'indiquer au processeur qu'une partie de l'adresse virtuelle d'un pointeur doit être ignorée lors de la traduction en adresse physique. Cela permet de profiter de ces bits non utilisés pour y sauvegarder des métadonnées. Le TBI est disponible sur tous les processeurs Armv8 AArch64 et peut donc être utilisé aisément.
L'approche utilisée par HWAsan est différente de celle d'ASan. Fini les red-zones et la mise en quarantaine, la détection déterministe d'ASan devient une détection probabiliste avec l'approche de labellisation mémoire — ou memory tagging.
Le fonctionnement d'HWAsan sur AArch64 est le suivant :
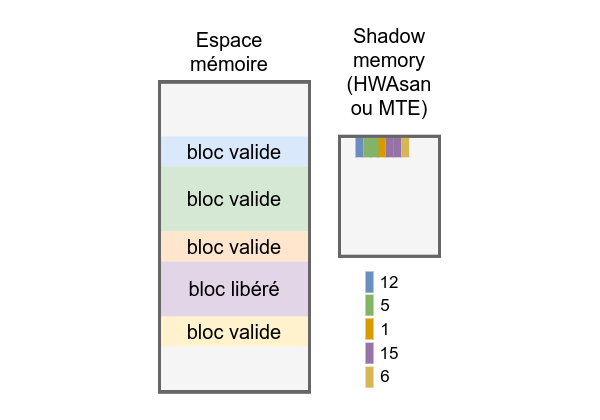
- La shadow memory est toujours présente, mais au lieu de contenir des valeurs prédéfinies pour représenter les morceaux de mémoire valides, désalloués ou appartenant à des red-zones, un label — ou « tag » — aléatoire est utilisé.
- Pour chaque plage de mémoire, un tag est généré — typiquement un tag différent pour chaque morceau alloué sur le tas, ou sur différents morceaux de données de la pile.
- Ce tag est copié sur la partie non utilisée du pointeur. Cette opération est réalisée automatiquement par le compilateur pour les données sur la pile et par les fonctions de gestion mémoire pour le tas.
- Lorsqu’un bloc de mémoire n’est plus utilisé (bloc désalloué ou ancien morceau de stack), son tag est changé (pour créer une incohérence avec les pointeurs ciblant encore cette zone).
- De la même manière qu’ASan, une routine de vérification est ajoutée avant tout accès mémoire dans le code du programme. Cette routine vérifie que le tag contenu dans le pointeur correspond bien au tag de la zone mémoire à laquelle il essaie d'accéder.
La taille des morceaux de mémoire représentée sur chaque case de la shadow memory est appelée « granule ». Dans le cas d’ASan, nous avons vu que la granule est de 8 octets. Dans le cas de HWAsan, le choix d'une granule de 16 octets semble avoir été le résultat d'une série de tests empiriques afin de trouver le juste milieu entre l’augmentation de la taille de la shadow memory, et le surcoût engendré par un alignement plus large des blocs mémoire.
La taille du TAG choisi pour HWAsan est de 8 bits. Cela donne 256 valeurs possibles, soit une probabilité de collision de tag de 1 chance sur 256. Cette probabilité est suffisamment faible pour ne jamais arriver. En cas de paranoïa, il suffira de lancer une deuxième fois le programme pour que de nouveaux tags aléatoires soient choisis.
La suppression des red-zones et la mise en quarantaine rendent cette approche plus performante et moins gourmande en mémoire qu’ASan. Toutefois l'ajout des routines de validation à chaque accès mémoire reste un véritable poids pour le programme. Le mieux ne serait-il pas d'avoir un support matériel pour s'en occuper directement ?
5.3 ARM MTE : passage au Memory Tagging matériel
MTE est une fonctionnalité introduite avec la spécification ARMv8.5 qui apporte le support matériel pour le memory tagging tel qu'utilisé par HWASan.
Les futurs SoC avec support du MTE arriveront avec une zone de mémoire dédiée pour la shadow memory, indépendante de la mémoire traditionnellement utilisée par les programmes et le système d'exploitation. Nous parlons ici d'une mémoire entièrement gérée par le CPU dont l'implémentation reste à la discrétion du concepteur de SoC.

Le TAG est toujours enregistré dans l’adresse à position fixe [56:59]. Avec MTE, seuls 4 bits de TAG sont disponibles. De plus, les valeurs b0000 et b1111 sont réservées, ce qui laisse 14 valeurs possibles. La limite de collision de tags sur des blocs mémoire successifs passe donc à 1 chance sur 14 soit ~7%. Pour réduire cette probabilité, l’allocation des tags peut être faite de manière plus intelligente qu’un simple aléa à chaque tirage.
La mise à jour des tags est réalisée via des instructions dédiées :
- IRG pour la génération d'un tag aléatoire et son ajout au pointeur ;
- STG pour l'ajout du tag à un pointeur ;
- LDG pour la lecture du tag d'un pointeur.
La validation du tag est désormais automatique et ne nécessite plus de routine logicielle et d'instrumentation du compilateur, c'est le CPU qui s'en occupe à chaque accès. En cas d'incohérence, une exception d'accès mémoire est renvoyée et alors gérée par le programme ou le système d'exploitation.
Conclusion
Il nous faudra être encore un peu patients avant l’arrivée de ces mécanismes sur une plus large gamme de terminaux. Apple a commencé le mouvement avec le support de PAC sur son kernel ainsi que pour les programmes tiers. Les équipes d’Android préparent le support de MTE à travers leur nouvelle variante d’ASan nommée GWP-Asan. Certains de ces mécanismes peuvent être testés dès aujourd’hui sur Qemu. Il est temps de se préparer, d’apprendre à maîtriser ces outils et de réfléchir à leur intégration dans les futures versions de nos développements logiciels.
Références
- Pointer Authentication on ARMv8.3 - Qualcomm Whitepaper. Jan 2017
- Azad, « Examining Pointer Authentication on the iPhone XS », Google Project Zero, 2019
- ARM Memory Tagging Extension and How It Improves C/C++ Memory Safety - Kosta Serebryany, 2019
- Providing protection for complex software – ARM Whitepaper. Jan 2020