

Afin de séparer les cœurs supportant les activités temps réel et temps partagé d'applications sur une architecture SMP sous Linux, le sous-système cpuset des cgroups est désormais mis en avant, au détriment de l’ancienne méthode basée sur le paramètre isolcpus.
Linux, système versatile devant l’Éternel, permet de répartir une application sur différentes unités de calcul afin de répondre à divers besoins en termes de temps de réponse. Il est notamment possible de dédier un cœur à des activités aux contraintes temps réel, tandis que les autres cœurs sont consacrés aux activités temps partagé. Par le passé, l’isolation CPU la plus courante s'appuyait sur l’utilisation du paramètre isolcpus de la ligne de commande du noyau Linux. Avec l’avènement des cgroups [1], une nouvelle solution se présente avec le sous-système cpuset. Elle est même censée remplacer la première qui, bien que toujours disponible, est déclarée obsolète dans les récentes moutures de Linux.
Cet article propose de comparer ces deux solutions en évaluant le temps de réponse à travers la mesure de la latence.
Les codes utilisés dans cet article sont disponibles sur http://www.rkoucha.fr/tech_corner/isol_cpu/isol_cpu.tgz.
1. La latence
Donnée indispensable dans un contexte informatique temps réel, la latence est la durée de l’intervalle de temps entre l’apparition d’un événement et sa prise en compte par un thread comme décrit en figure 1.
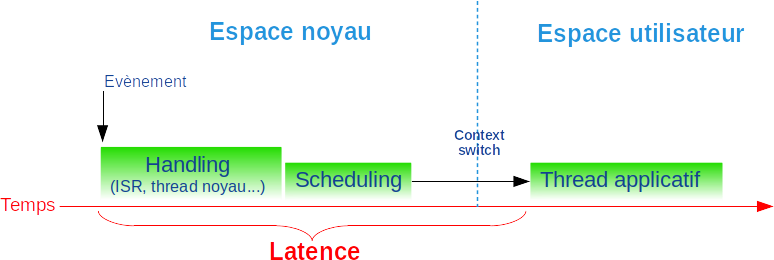
Par exemple, la latence est l’intervalle de temps entre l’apparition de l’interruption (pour l’échéance d’une temporisation, l’arrivée d’un message sur le réseau...) et son traitement par un thread applicatif.
Pour satisfaire des contraintes temps réel, il convient de connaître la latence et notamment sa valeur maximale pour appréhender l’impact sur le temps de réponse d’une application. En général, on cherche à réduire sa valeur maximale autant que possible, de sorte à augmenter le déterminisme du système [2].
La diminution de la latence est un travail de longue haleine, surtout dans le cadre d’un système temps partagé comme Linux qui n’était pas prévu à l’origine pour faire du temps réel. Mais il a bénéficié de nombreuses modifications [3] depuis ses débuts dans le noyau en général (pour le rendre préemptible) et dans l’ordonnanceur des tâches en particulier avec l’introduction du « Completely Fair Scheduler » [4].
2. La préemption
2.1 Histoire
Linux est un système préemptif par essence, dans la mesure où une tâche peut être interrompue pour céder la main à une autre tâche plus prioritaire ou parce qu'elle a consommé son quantum de temps CPU. Basique à ses débuts, la préemption ne concernait que les traitements en espace utilisateur, car une fois dans le noyau (pour exécuter un appel système), la tâche prenait le fameux « kernel lock » global qui empêchait toute autre tâche de prendre la main pendant la durée de son traitement. Au fil du temps, Linux a subi de nombreuses évolutions pour supprimer ce fameux goulot d’étranglement que représentait le verrou central afin de permettre la préemption à plus grande échelle [5].
2.2 Les niveaux de préemption
Afin de proposer un système allant du temps partagé au temps réel dur, Linux propose trois niveaux croissants de préemption avec les paramètres suivants de configuration du noyau du fichier kernel/Kconfig.preempt :
- CONFIG_PREEMPT_NONE : préemption non forcée ;
- CONFIG_PREEMPT_VOLUNTARY : préemption volontaire [6] ;
- CONFIG_PREEMPT : noyau préemptible.
Il existe même un niveau supplémentaire (CONFIG_PREEMPT_RT [7]) pour avoir un noyau complètement préemptible, mais cela nécessite un patch, car il n'est pas dans la main line du noyau.
Les commentaires accompagnant ces drapeaux indiquent que plus le niveau de préemption est élevé, plus la latence est réduite, mais cela se fait souvent au détriment de la capacité de traitement (throughput). C’est en partie dû au nombre plus élevé de changements de contextes pour passer la main plus rapidement aux différentes tâches nécessitant le CPU et un code généré plus lent [8]. Concilier capacité de traitement et latence minimale est un dilemme cornélien auquel doivent faire face de nombreuses applications industrielles.
2.3 Cohabitation temps réel/partagé
La cohabitation des traitements temps réel et temps partagé sur une même carte n’est pas aisée, voire contradictoire, étant donné que le système d’exploitation est commun. D’où les méthodes d’isolation consistant à allouer un ou plusieurs cœurs du CPU aux traitements temps partagé et les autres aux traitements temps réel. Ce sont des solutions que l’on trouve régulièrement dans les systèmes de télécommunication, par exemple : des tâches d’administration et de supervision doivent cohabiter avec des tâches de traitement des flux de données sur le réseau.
3. Les méthodes d’isolation CPU
Ce qui est entendu par l’isolation d’un CPU est le fait de le libérer :
- des threads utilisateur autres que ceux auxquels il est dédié ;
- des threads noyau qui ne lui sont pas liés (c.-à-d. unbounded threads) ;
- autant que faire se peut des interruptions ;
- de l’équilibrage de charge du scheduler.
Mais les CPU isolés restent tout de même sous le contrôle du système d’exploitation.
3.1 Méthode isolcpus
Cette méthode consiste à positionner le paramètre isolcpus sur la ligne de commande du noyau [9] avec les numéros de cœurs à supprimer de la liste participant à l’équilibrage de la charge CPU. Le format est une liste de numéros de CPU séparés par des virgules ou un ensemble de numéros consécutifs de CPU décrit par un intervalle (numéros minimum et maximum séparés par un tiret). Par exemple, un noyau Linux isolant les cœurs 2 et 3 aura une ligne de commande comme suit :
Bien que toujours sous le contrôle de Linux, les cœurs ainsi isolés sont déchargés de nombreuses activités système pour n’être dédiés qu’aux threads explicitement migrés avec le masque d’affinité CPU requis via l’appel système sched_setaffinity().
Cette méthode d’isolation est la plus ancienne, mais les développeurs de Linux incitent à l’abandonner au profit du sous-système cpuset des cgroups. Dans [9], le paramètre est même déclaré obsolète :
3.2 Méthode cpuset
Cette méthode consiste à utiliser le sous-système cpuset des cgroups [10]. Par défaut, dans l’arborescence des cgroups, le sous-système cpuset comprend tous les CPU. Par exemple, pour un système avec un CPU équipé de 8 cœurs :
Ainsi, tous les threads tournant sur le système peuvent s’exécuter sur tous les CPU en fonction de leur masque d‘affinité et des décisions de l’ordonnanceur. Pour isoler un ou plusieurs CPU, il est possible de créer deux cgroups fils dans l’arborescence du sous-système cpuset pour diviser les cœurs en deux ensembles. Le cgroup père (racine) sera délesté de tous ses threads pour les répartir dans les deux cgroups fils ainsi créés. Dans le premier, on mettra uniquement les threads aux contraintes temps réel. Ils seront ainsi isolés des autres qui tourneront dans le second groupe.
Pour atteindre un niveau d’isolation qui se rapproche au plus près de la méthode isolcpus, il est aussi nécessaire de modifier certains paramètres système pour entre autres délester les CPU aux contraintes temps réel des threads noyau, interruptions « inutiles » et l'équilibrage de charge. La documentation du noyau [11] ainsi que le guide Linux temps réel [12] mis à disposition par la société Enea décrivent les réglages. C’est un travail fastidieux qui dépend des besoins de chacun. Dans le cadre de l’étude décrite dans cet article, nous nous contenterons d’utiliser un script Shell nommé partrt (c.-à-d. partitionnement temps réel) fourni dans le package rt-tools de la société Enea disponible sur GitHub [13].
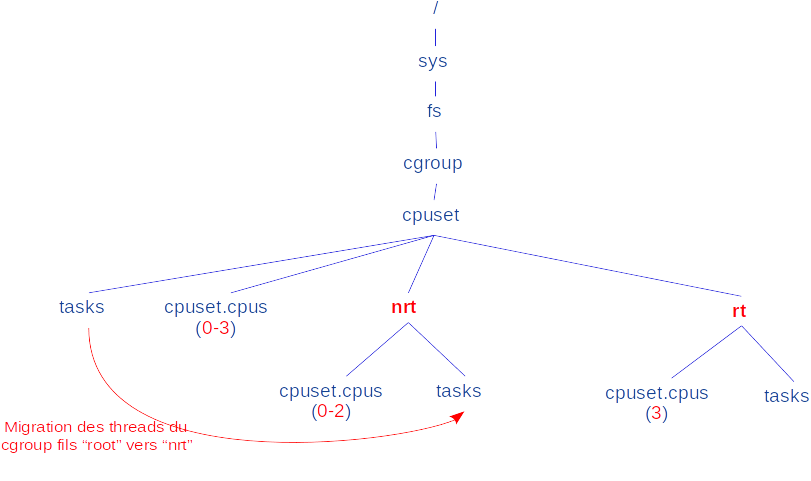
Dans son utilisation la plus simple, partrt reçoit en paramètre le masque en hexadécimal des CPU à isoler pour créer deux cgroups fils (appelés « partitions ») dans le sous-système cpuset : le premier est nommé rt (real-time) pour les threads à isoler et le second est nommé nrt (non real-time) pour tous les autres threads. Le script se charge aussi de la migration de tous les threads du système dans le groupe nrt ainsi que du réglage de certains paramètres du noyau pour faire du groupe rt une partition apte à recevoir des threads aux contraintes temps réel. La figure 2 illustre le cas d’un système avec quatre cœurs (0 à 3 au niveau cgroups racine) où les trois premiers (numéros 0 à 2) sont dans la partition nrt et le quatrième (numéro 3) dans la partition rt suite à l’exécution de partrt comme suit :
4. L’environnement de test
4.1 L’environnement matériel
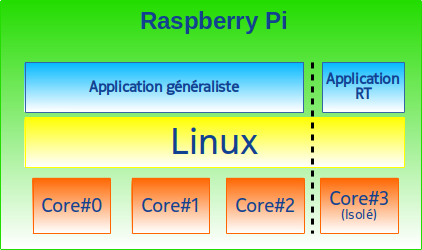
La cible multicœur est une carte Raspberry Pi version 3 (modèle B+) [14] illustrée en figure 3.

Les caractéristiques de cette carte sont entre autres :
- circuit Broadcom BCM2837B0, Cortex-A53 (ARMv8) ;
- 4 cœurs 64 bits cadencés à 1,4 GHz ;
- 1 thread hardware par cœur ;
- 1 GB de mémoire LPDDR2 SDRAM.
La carte est mise en réseau avec un PC GNU/Linux tournant sous Ubuntu pour la compilation croisée, prélever les mesures et présenter les résultats. Les trois premiers cœurs de la carte seront dédiés aux activités temps partagé tandis que le quatrième cœur sera réservé aux activités temps réel (figure 4).
4.2 L’environnement logiciel
Afin de générer les outils nécessaires à nos mesures, nous installons sur un PC hôte un environnement de compilation croisée et le noyau Linux comme indiqué sur le site dédié aux cartes Raspberry Pi [15]. Le compilateur GCC affiche la version suivante :
Sur la carte cible, la version de Linux est :
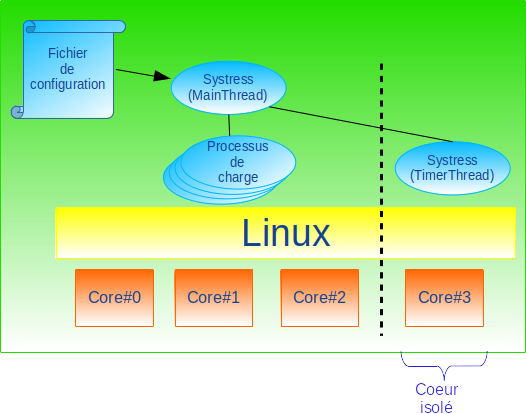
Le cœur numéro 3 de la carte Raspberry Pi isolé par l’une des méthodes isolcpus ou cpuset fait tourner un thread qui mesure la latence de traitement d’une temporisation cyclique. En parallèle, les autres cœurs sont chargés par des processus consommateurs de CPU, de mémoire et I/O. Tout cela est schématisé en figure 5.

Pour mesurer la latence, il y a l’outil cyclictest déjà présenté dans ces colonnes [16] et utilisé quotidiennement par le consortium OSADL [17] sur différentes plateformes matérielles. Il existe bien d’autres outils comme stress-ng [18] ou rteval [19]. Mais nous avons préféré développer un outil en langage C, nommé systress pour « SYstem STRESS », qui se charge non seulement de la mesure de la latence sur le CPU isolé, mais aussi de la charge sur les CPU non isolés. Il est mis à disposition en open source sous licence GPL sur sourceforge [20].
4.3 L’outil systress
4.3.1 Présentation
Le thread principal (MainThread) de systress fonctionne comme un chef d’orchestre qui, à partir d’un fichier de configuration, crée, supervise et termine des processus et threads répartis sur les différents CPU de la carte cible. Les processus servent à simuler de la charge sur les CPU non isolés pendant que les threads secondaires (TimerThreads) mesurent la latence de temporisations cycliques sur les CPU isolés (cf. figure 6).
Le principe de mesure de la latence décrit en figure 7 est calqué sur l’algorithme de l’outil cyclictest.
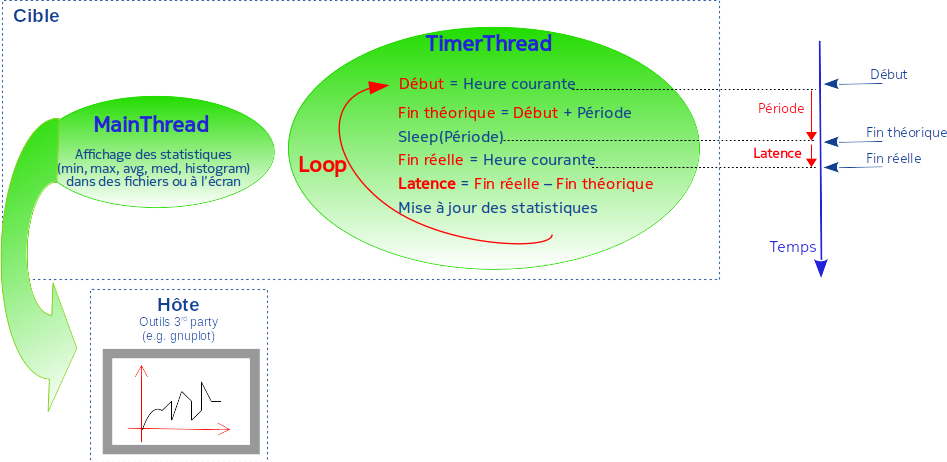
Dans sa boucle principale, le TimerThread relève l’heure courante, estime l’heure de réveil théorique comme la somme de l’heure courante plus la durée de la période de sommeil, s’endort pendant la période de temps donnée à l’aide d’un appel système, puis au réveil, relève de nouveau l’heure courante (c.-à-d. heure de réveil effective) qui est supérieure ou égale à l’heure de réveil théorique. La différence entre les deux constitue la latence.
4.3.2 Les statistiques
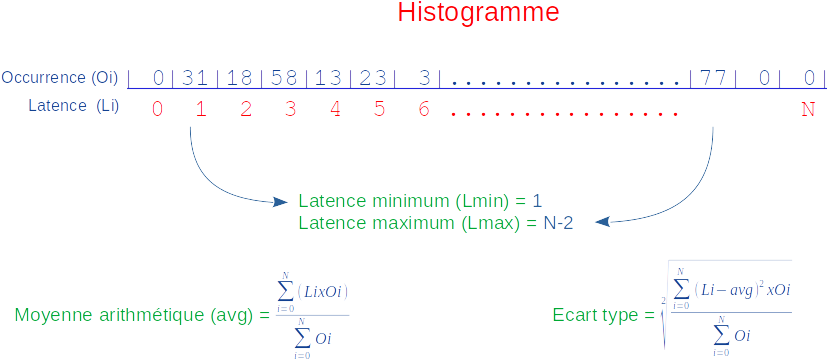
Les résultats des mesures de la latence effectuées par les TimerThreads sont produits en sortie au format texte ou CSV [21] par le MainThread sous la forme d’histogrammes : tables stockant les occurrences des différentes valeurs de latence et indexées par ces dernières. Les valeurs minimales, maximales, moyennes et médianes ainsi que l’écart-type sont aussi relevés (cf. figure 8).
Si la production de fichiers est demandée dans la configuration, ces derniers peuvent être exploités par des outils comme gnuplot [22] pour afficher les mesures sous forme graphique.
Afin d’éviter de se noyer dans une profusion de chiffres, C. Williams et J. Kacur de la société RedHat écrivent « We don't need no stinking statistics » [23] en référence au refrain « We don't need no education » du titre « Another brick in the wall » du légendaire groupe de musique Pink Floyd. Selon eux, deux statistiques comptent vraiment :
- la valeur maximale de la latence pour connaître le temps de réponse du système dans le pire des cas ;
- l’écart-type pour connaître la consistance des temps de réponse pendant la mesure.
4.3.3 Installation sur hôte
Au moment de l’écriture de cet article, la dernière version de systress disponible est la 0.5.0. Afin de réaliser une compilation croisée pour la carte cible Raspberry Pi à partir du système hôte, il est conseillé de télécharger l’archive du code source systress_src-0.5.0.tgz dans un répertoire. L'outil est fourni avec les deux systèmes de génération : autotools et cmake.
Dans le premier cas, la génération puis l'installation sont réalisées comme suit :
Dans le second cas, à l’aide du script systress_install.sh fourni et situé à la racine des sources, la génération et l'installation sont réalisées comme suit (un fichier README explique les étapes à suivre) :
Pour une description plus complète, le manuel de l’outil se trouve dans la section 8 :
Le manuel du fichier de configuration passé avec l’option --cfg se trouve dans la section 5 :
La configuration consiste en un stanza par thread ou programme à exécuter dans lequel sont consignés des propriétés comme le chemin du programme à exécuter, la priorité, l’affinité CPU, la période de la temporisation cyclique servant à la mesure de la latence...
4.3.4 Prise en main
Réalisons un premier test de l’outil sur hôte. Notre PC hôte à 8 cœurs :
Le fichier host.cfg est un premier exemple. Dans le stanza main, nous configurons le comportement du MainThread sur les cœurs numéros 0 à 6 avec un type de scheduling temps partagé (c.-à-d. OTHER) et une période de rafraîchissement des statistiques à l'écran de 1,5 seconde. Dans le stanza timer_thread[0], nous configurons le comportement d’un TimerThread sur le cœur numéro 7, avec une priorité de 99, un type de scheduling temps réel FIFO, une durée de mesure de la latence de 1 minute et 20 entrées dans l'histogramme, car on estime que la latence maximale est de 20 microsecondes. Le fichier de configuration est le suivant :
Le lancement de l’outil nécessite les droits du super utilisateur afin de lui permettre de lancer le thread temps réel :
On constate bien le rafraîchissement de l’affichage des statistiques à l’écran après chaque 1,5 seconde, comme demandé dans la configuration. Au bout d’une minute, la mesure s’arrête conformément au paramètre stats.period du stanza main. On constate déjà que la latence maximale mesurée est de 100 microsecondes. Cela dépasse la valeur maximale (20 microsecondes) que nous avions configurée pour l'histogramme. Certaines des mesures de la latence n'apparaîtront donc pas dans le fichier de sortie. Dans la pratique, on adapte la configuration pour relancer le test.
L’outil indique que les résultats sont disponibles dans le fichier timer_thread00.txt :
Le fichier de sortie commence avec la représentation de l’histogramme sur deux colonnes :
- la première indique les valeurs possibles de la latence de 0 à 20 microsecondes comme demandé dans la configuration (ce sont les index des entrées du tableau qui représente l'histogramme comme schématisé en figure 8) ;
- la seconde indique le nombre d’occurrences d’apparition des latences (ce sont les contenus des entrées du tableau qui représente l'histogramme comme schématisé en figure 8).
Le fichier se termine par les statistiques (les lignes sont commentées avec un caractère # pour ne pas être interprétées par certains outils comme les tableurs ou gnuplot) :
- l’index du thread (Index = 0) ;
- l’identifiant du thread (TID = 13029) ;
- le nombre total d’échantillons (Samples = 60000), c’est-à-dire le nombre de prélèvements de la latence pendant la période de une minute demandée ;
- la valeur minimale prélevée pour la latence (L_min = 2 microsecondes). En d’autres termes, l’indice de la première entrée renseignée dans l’histogramme ;
- la valeur maximale prélevée pour la latence (L_max = 100 microsecondes). Cela devrait correspondre à l’indice de la dernière entrée renseignée dans l’histogramme, mais comme on a configuré une valeur de latence maximale égale à 20 microsecondes, cette valeur maximale est hors histogramme ;
- la moyenne arithmétique des valeurs des latences prélevées sur le nombre total d’échantillons pendant la période de mesure (L_avg = 17 microsecondes) ;
- le nombre d’échantillons dont les valeurs de la latence sont dans l’histogramme (Samples_H = 55431), c’est-à-dire le cumul des contenus des entrées de l’histogramme ;
- la moyenne arithmétique des valeurs des latences prélevées et stockées dans l’histogramme pendant la période de mesure (L_avg_H = 16 microsecondes) ;
- la valeur médiane des valeurs des latences prélevées et stockées dans l’histogramme pendant la période de mesure (L_med_H = 17 microsecondes) ;
- l’écart-type (standard deviation en anglais) des valeurs des latences prélevées et stockées dans l’histogramme pendant la période de mesure (L_std_H = 3 microsecondes) ;
- les modes des valeurs des latences prélevées et stockées dans l’histogramme pendant la période de mesure. Ce sont les entrées avec le plus grand nombre d’occurrences dans l’histogramme (L_mode_H = 17 microsecondes).
Il est possible de charger le système pour voir l’impact sur la latence. On peut par exemple ajouter des stanzas program[] pour exécuter des processus consommateurs de CPU et d’I/O sur les cœurs 0 à 6, comme dans notre fichier host2.cfg. Nous pouvons aussi activer l'affichage de la charge CPU avec le paramètre stats.cpu_load :
À l'exécution, la charge CPU s'affiche en plus des statistiques de la latence :
4.3.5 Compilation croisée
Avec le compilateur installé selon les directives de [15], la compilation croisée via les autotools est réalisée comme suit :
Avec cmake, il faut spécifier un fichier toolchain, dont un exemple est donné à la racine des sources (rpi_toolchain.cmake), renseigné conformément à l’environnement proposé par [15]. Il suffit de mettre à jour la variable interne CT_INSTALL avec le chemin d’installation de l’environnement de cross-compilation. Par exemple, si l’installation a eu lieu dans ${HOME}/DEVS/RASPBERRY_PI/OS/tools, on modifie le fichier comme suit :
Ensuite, la compilation croisée de l’outil se fait comme suit :
Il ne reste plus qu’à transférer l’outil sur la cible pour lancer les tests avec les fichiers de configuration décrits plus bas.
4.4 L’outil partrt
4.4.1 Téléchargement
Faisant partie du package rt-tools, on le télécharge comme suit du site GitHub :
Le package utilise l'environnement de compilation cmake :
4.4.2 Compilation croisée
L'outil partrt est certes un script Shell, mais il s’appuie sur l’exécutable bitcalc pour la manipulation des bits dans le masque de CPU. Par conséquent, il faut compiler ce dernier et l’envoyer sur la cible avec le script. Pour la compilation croisée, on copie le fichier toolchain de systress dans le répertoire de rt-tools :
Il est aussi nécessaire de modifier le fichier CMakeLists.txt pour ne pas générer les tests de bitcalc qui nécessitent des librairies qu'il est fastidieux d'installer dans l'environnement de compilation croisée. Il suffit de commenter la ligne d'ajout du répertoire des tests pour désactiver leur génération :
La compilation est réalisée comme suit :
Une fois généré, nous vérifions que le format de l’exécutable bitcalc est bien pour le processeur ARM :
Ensuite, nous transférons le script partrt/partrt et l'exécutable bitcalc/src/bitcalc sur la cible dans un répertoire pris en compte par la variable PATH de l'utilisateur sur la carte (p. ex. /usr/local/bin).
5. Les mesures
5.1 Configuration du noyau
Comme indiqué plus haut, le noyau est téléchargé et compilé comme indiqué sur le site de Raspberry Pi [15]. Le menu de configuration de Linux se lance comme suit à partir du répertoire racine d'installation des sources de Linux [24] :
Cela fait apparaître le menu de configuration de la figure 9.
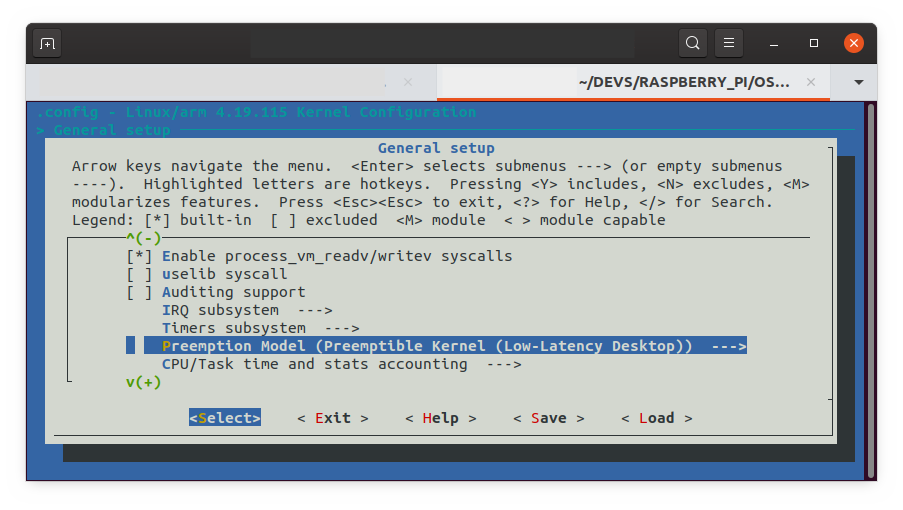
La configuration du mode de préemption est dans le menu General setup > Preemption model comme indiqué en figure 10 :
On en profite aussi pour activer la création du fichier /proc/config.gz afin de faciliter l'accès à la configuration du noyau sur la cible avec le choix * dans General setup > Kernel .config support.
Une fois sauvée, il est conseillé de copier la configuration (c.-à-d. le fichier .config) dans un autre fichier pour l'avoir sous la main en cas de réutilisation afin d'éviter de relancer le menu. Par exemple, pour la configuration en mode PREEMPT_VOLUNTARY :
Plus tard, s'il y a besoin de refaire un noyau avec cette configuration, on la recopie dans le fichier .config.
La compilation du noyau ainsi que les modules et le device tree associés est réalisée comme suit (l'utilisation de l'option -j, configurée en fonction du nombre de cœurs du système, parallélise les traitements) :
Si la carte SD de la cible est montée sur hôte (p. ex. ici dans ../mnt/fat32 et ../mnt/ext4 par rapport au répertoire des sources), nous procédons de cette manière pour y copier l'image du noyau, les modules et le device tree :
Une fois la cible redémarrée avec la carte SD à jour, on peut vérifier que la configuration a correctement été effectuée (p. ex. ici avec le paramètre PREEMPT_VOLUNTARY) :
5.2 Isolation avec isolcpus
5.2.1 Configuration de la cible
Sur la cible, nous vérifions que le noyau supporte l’isolation de CPU. Puis, le fichier /boot/cmdline.txt est modifié comme suit pour isoler le cœur numéro 3 :
Après un redémarrage de la cible, on vérifie l’isolation du cœur numéro 3 :
Nous confirmons aussi qu’à part quelques threads cpu-bounded, aucune tâche ne tourne sur le cœur numéro 3 :
On fera tourner le TimerThread de systress sur ce cœur.
5.2.2 Configuration de systress
Le fichier de configuration rpi_isolcpus.cfg permet de mesurer la latence hors charge. Il spécifie un thread principal à exécuter sur les cœurs 0-2 tandis que le thread secondaire s’exécute sur le core 3 pour prélever la latence. La durée de mesure est de 10 minutes :
Le fichier de configuration rpi_isolcpus_load.cfg permet de mesurer la latence en charge. Il spécifie un thread principal et des programmes (find, tar, gzip, ping...) consommateurs de ressources CPU, mémoire et I/O à exécuter en boucle sur les cœurs 0-2 tandis que le thread secondaire s’exécute sur le cœur 3 pour prélever la latence. Le contenu est identique au précédent, mais avec l’ajout des stanzas program[] :
5.3 Isolation avec cpuset
5.3.1 Configuration de la cible
Le fichier cmdline.txt pour la ligne de commande du noyau ne doit pas contenir le paramètre isolcpus :
Le sous-système cpuset contient par défaut tous les cœurs :
Utilisons le script partrt pour créer un cgroup nrt (c.-à-d. non real-time) avec les cœurs 0 à 2 et un cgroup rt (c.-à-d. real-time) avec le cœur 3 :
Nous vérifions que deux sous-arbres respectivement nommés nrt et rt ont été créés dans le répertoire cpuset :
Le répertoire racine comprend toujours tous les cœurs du système :
Le répertoire nrt contient le sous-ensemble des cœurs 0 à 2 :
Ce dernier contient toutes les tâches du système :
Le répertoire rt contient le sous-ensemble avec le cœur 3 :
Ce dernier ne contient aucune tâche applicative :
On fera tourner le TimerThread de systress dans ce cgroup.
5.3.2 Configuration de systress
Les fichiers de configuration rpi_cpuset.cfg et rpi_cpuset_load.cfg permettent respectivement de mesurer la latence hors charge et en charge. Mis à part le positionnement du thread principal dans le cgroup nrt et le thread secondaire dans le cgroup rt ainsi que le nommage du fichier de sortie des résultats, ils sont respectivement identiques aux fichiers rpi_isolcpus.cfg et rpi_isolcpus_load.cfg précédents.
5.4 Lancement des tests
Nous redémarrons la cible entre les mesures pour repartir d'un environnement sensiblement identique pour chaque test.
Pour les mesures hors charge, nous utilisons les fichiers rpi_isolcpus.cfg et rpi_cpuset.cfg. Voici par exemple le lancement de l’outil avec une isolation de type cpuset :
Pour les mesures en charge, nous utilisons les fichiers rpi_isolcpus_load.cfg et rpi_cpuset_load.cfg. On notera que la cible peut monter en température allant jusqu'à provoquer l'affichage de l'icône « thermomètre » [25]. Il convient donc de bien ventiler la carte ou de supprimer des programmes de charge dans le fichier de configuration et de laisser un temps de refroidissement entre les mesures, sinon le firmware de la carte abaisse la fréquence de fonctionnement des cœurs. Sur notre carte de test, ces fichiers de configuration engendrent une charge globale CPU d'un peu plus de 50%. Voici par exemple le lancement de l’outil avec une isolation de type cpuset :
Puis, on rapatrie les fichiers de résultats sur hôte pour analyse.
5.5 Résultats
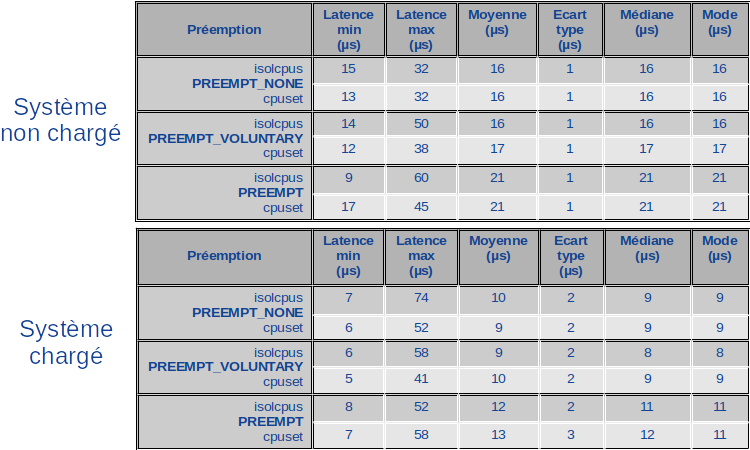
Les résultats synthétiques stockés à la fin des fichiers de sortie de systress sont consignés dans les tables de la figure 11.
Le fichier de commandes plot.show affiche toutes les courbes sous gnuplot. Il peut être chargé avec la commande load :
Il en résulte l'affichage de la figure 12. Les courbes du graphique peuvent être masquées ou affichées en cliquant sur les légendes associées (ce sont des boutons bascules).
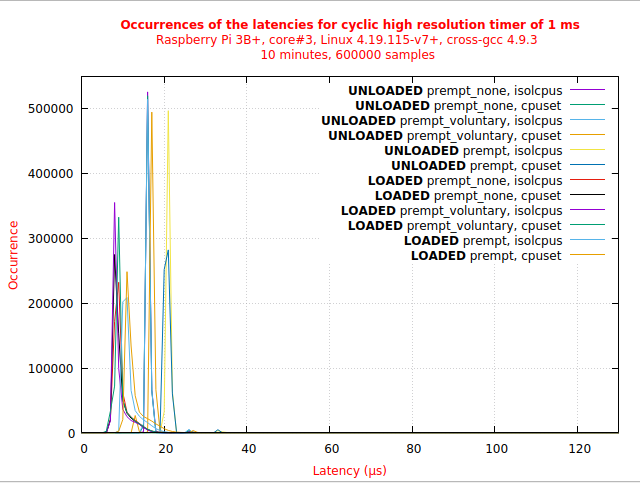
Pour chaque type de préemption, système chargé ou non, les valeurs de la latence sont équivalentes pour les deux types d'isolation. Quand on les regarde par deux, les courbes arrivent même parfois à se confondre sur le graphe.
Conclusion
Cette étude montre que l'isolation de CPU par le sous-système cpuset des cgroups présente des temps de latence similaires à l'isolation par le paramètre isolcpus de la ligne de commande du noyau. Nous comprenons pourquoi ce dernier est déclaré obsolète dans les sources du noyau de Linux, car il fait maintenant double emploi avec le premier.
Références
[1] Cgroups : https://en.wikipedia.org/wiki/Cgroups
[2] Système déterministe : https://fr.wikipedia.org/wiki/Syst%C3%A8me_d%C3%A9terministe
[3] The realtime preemption endgame : https://lwn.net/Articles/345076/
[4] Completely Fair Scheduler : https://fr.wikipedia.org/wiki/Completely_Fair_Scheduler
[5] The evolution of Real-Time Linux : https://www3.nd.edu/~cpoellab/teaching/cse40463/amatta2.pdf
[6] Voluntary Kernel Preemption : https://lwn.net/Articles/137259/
[7] A realtime preemption overview : https://lwn.net/Articles/146861/
[8] Optimizing preemption : https://lwn.net/Articles/563185/
[9] Les paramètres de la ligne de commande du noyau : https://www.kernel.org/doc/Documentation/admin-guide/kernel-parameters.txt
[10] Documentation sur les cpusets : https://www.kernel.org/doc/Documentation/cgroup-v1/cpusets.txt
[11] Reducing OS jitter due to per-cpu kthreads : https://www.kernel.org/doc/Documentation/kernel-per-CPU-kthreads.txt
[12] Enea Linux Real-Time Guide : https://linux.enea.com/4.0/documentation/html/book-enea-linux-realtime-guide/
[13] The CPU partitionning tool : https://github.com/OpenEneaLinux/rt-tools
[14] Raspberry Pi 3 Modèle B+ : https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2837b0/README.md
[15] Raspberry Pi Kernel building : https://www.raspberrypi.org/documentation/linux/kernel/building.md
[16] « Raspberry Pi Avancé », GNU/Linux Magazine Hors Série numéro 75, novembre 2014.
[17] Open Source Automation Development Lab (OSADL) : https://www.osadl.org/
[18] L’outil stress-ng : https://wiki.ubuntu.com/Kernel/Reference/stress-ng
[19] L'outil rteval : https://wiki.linuxfoundation.org/realtime/documentation/howto/tools/rteval
[20] L'outil Systress : https://sourceforge.net/projects/systress/
[21] Le format CSV : https://fr.wikipedia.org/wiki/Comma-separated_values
[22] gnuplot homepage : http://www.gnuplot.info/
[23] Measuring real time Linux performance on arbitrary hardware : https://blog.linuxplumbersconf.org/2010/ocw/system/presentations/645/original/measuring.odp
[24] Configuration de Linux pour Raspberry Pi : https://www.raspberrypi.org/documentation/linux/kernel/configuring.md
[25] Firmware warning icons on Raspberry Pi : https://www.raspberrypi.org/documentation/configuration/warning-icons.md
