

Si vos serveurs ne tiennent plus la charge, qui allez-vous appeler ? Pas Ghostbusters, mais Load Balancers ! Nous allons discuter de plusieurs méthodes de répartition de charge ainsi que leur intégration dans votre environnement traditionnel ou Cloud.
Dans cet article, nous allons d’abord définir la répartition de charge (ou Load Balancing) avec quelques considérations à avoir en fonction des services pour lesquels vous souhaitez répartir l’activité. Dans la première grande partie, nous allons ensuite exposer quelques méthodes pour équilibrer la charge sur des services déployés dans des environnements traditionnels. Dans la seconde partie de l’article, nous allons aborder l’équilibrage de charge dans les environnements Cloud basés sur l’orchestrateur Kubernetes. Dans toute la suite de l’article, nous allons référencer les systèmes d’équilibrage de charge par leur équivalent sémantique anglo-saxon : les load balancers. Les load balancers sont des éléments centraux des plans de « disaster recovery », car ils contrôlent aussi la disponibilité des services équilibrés avant d’envoyer des requêtes dessus.
1. Introduction au Load Balancing
Les systèmes de répartition de charge (ou load balancers) s’occupent de distribuer vos requêtes sur plusieurs instances d’extrémités configurées de façon homogène. Le mot extrémité est volontairement vague, car il peut s’agir d’une machine (plus précisément de son IP), d’un service réseau (plus précisément le port UDP ou TCP sur lequel il est lié) ou d’une extrémité applicative. Pour ce dernier, l’exemple le plus répandu est l’URL. Le load balancer s’intercale entre les X instances de l’extrémité et le client. Le client n’a donc aucune idée que sa requête est load balancée par un tiers avant de toucher l’extrémité ciblée.
Chacun des trois types d’extrémités correspond à un niveau du modèle OSI. Les load balancers L3 (Layer 3, couche réseau) basent leur décision d’orientation uniquement sur les informations de l’en-tête IP (adresse source et destination). En conséquence, les paquets émis par une machine seront envoyés à une machine puis à une autre indépendamment du service réseau ciblé. On notera que cette répartition de charge est très souvent opérée par les équipements de routage. La machine en question est donc souvent un routeur. Les routeurs sont tous plus ou moins capables de définir des chemins alternatifs dans leurs tables (multipath) pour les différents algorithmes de routage supportés (OSPF, ISIS, BGP etc.). Ils vont utiliser un protocole orienté répartition de charge (type ECMP) qui va s’appuyer sur cette capacité à créer des chemins alternatifs pour équilibrer la charge. Cette partie est hors sujet pour cet article.
Les load balancers L4 (Layer 4, couche transport) s’appuient à la fois sur les niveaux 3 et 4 du modèle OSI. La décision de savoir vers quelle instance du service orienter le client est basée sur une composition de tuples IP source, IP destination, port source et port destination. Le principal intérêt par rapport aux load balancers L3 est que les services peuvent être distribués sur des groupes (ou pools) différents.
Les load balancers L7 (Layer 7, couche application) inspectent le protocole utilisé par le client et le service réseau pour orienter les requêtes. Par exemple, on peut orienter une URL demandée par un client sur telle ou telle instance du serveur web derrière le load balancer. Cette répartition est plus fine qu’en L4 où on raisonne par ports. On notera que parfois on parle aussi de load balancer L5 si on se base sur le modèle TCP/IP simplifié plutôt que sur le modèle OSI. On notera également que plus on monte dans les couches, plus la répartition de charge est coûteuse au niveau des ressources sur le load balancer.
Cet article va se diviser en deux grandes parties. Dans la première, nous verrons les load balancers s’intégrant dans des architectures classiques. Nous proposerons plusieurs solutions pour mettre en place une répartition de charge entre vos serveurs physiques et/ou machines virtuelles. La seconde partie se focalisera sur la répartition de charge dans les environnements Cloud, notamment Kubernetes. L’intérêt de cette répartition de charge est qu’elle peut solliciter l’adjonction de ressources supplémentaires si le service est trop chargé. C’est la propriété d’élasticité.
2. Les load balancers « classiques »
Nous allons présenter plusieurs méthodes de load balancing avec leurs implications au niveau architecture réseau. Nous illustrerons chacune de ces méthodes avec l’outil Relayd issu du projet OpenBSD [1]. Nous aurons donc un client et des services à équilibrer sous Debian Buster par un load balancer sous OpenBSD. Nous allons étudier cinq méthodes : sans load balancers, redirections (L3), relai (L4), relai avec prise en compte de la couche applicative (L7) et accélération TLS/SSL. Tous nos tests se font dans le domaine lab.local.
2.1 Équilibrage sans load balancer
Une première option pour équilibrer la charge sans load balancer est de s’appuyer sur le protocole DNS (Domain Name System). Ce protocole est en charge de retrouver une IP à partir d’un nom pleinement qualifié d’hôte. Cette résolution est une requête de type A. Elle peut être générée, par exemple, par votre navigateur lors de la consultation d’un site. Il suffit donc de multiplier les adresses des différents serveurs hébergeant les services à équilibrer pour un nom pleinement qualifié. Nous avons un fichier de zone de test /etc/bind/zones/lab :
Voici le contenu de la zone, le but de l’article n’étant pas de discuter sur DNS nous affichons juste les enregistrements essentiels :
Dans ce fichier, on voit que le nom www.lab.local correspond à deux adresses IP : 192.168.45.11 et 192.168.45.12. Lors de la résolution du nom www.lab.local, les deux adresses sont distribuées tour à tour. Chacune des deux machines derrière www.lab.local embarque un serveur web qui ne fait qu’afficher le nom de la machine lorsqu’on accède à sa racine. Nous allons simuler l’accès au site hébergé sur chacune des deux machines avec la commande curl :
Cette commande génère 1000 demandes de résolution du nom www.lab.local au serveur DNS et enregistre les réponses dans le fichier hits. Voyons le contenu de hits :
Cette commande va trier par ordre alphabétique de contenu de hits (sort). Le résultat part dans le filtre uniq qui va afficher qu’une occurrence de chaque ligne dans le cas où des lignes identiques se suivent. Avec l’argument -c (count), on ajoute le nombre de lignes agrégées lors de l’opération. Ainsi, nous avons accédé 492 fois au serveur web de web1 et 508 fois au serveur web web2. Cette méthode qui consiste à servir des ressources tour à tour s’appelle le Round Robin. Ici, il s’agit de Round Robin DNS (ou RR DNS). On notera que nous ne sommes pas à 50/50, car les systèmes d’exploitation possèdent des caches DNS, ce qui biaise légèrement la distribution.
2.2 Les redirections
La première méthode de load balancing s’appuie sur le combo Relayd et PF (Packet Filter) [2] pour rediriger le paquet vers telle ou telle machine. Relayd est un service implémenté par OpenBSD qui relaie dynamiquement les requêtes entrantes sur ses interfaces vers d’autres machines. Relayd s’occupe de vérifier la disponibilité des machines vers lesquelles on redirige le trafic à l’aide de différents plugins (TCP, ICMP, HTTP en TLS ou non). Une fois la disponibilité vérifiée, Relayd fait ce qu’il faut pour acheminer le trafic vers les services équilibrés. Cet acheminement peut prendre la forme d’une redirection ou d’un relai (relay). Commençons par la redirection.
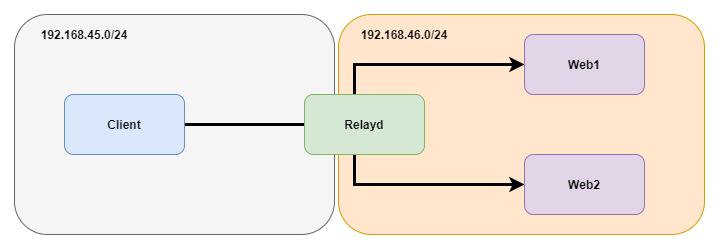
La redirection s’appuie sur les règles rdr-to [3] du pare-feu OpenBSD PF qui définissent des redirections de port. Cette redirection consiste à réécrire l’adresse et le ou les ports destination afin de livrer les paquets réseau à la bonne cible. Ces règles sont générées par Relayd et appliquées dans PF via une anchor qui est, en gros, un point d’ancrage pour ajouter des règles dynamiquement au pare-feu. Dans ce mode de fonctionnement, la réponse des services derrière le load balancer doit obligatoirement repasser par PF pour être livrée au client. Ainsi, au niveau réseau, le plus simple est de faire un petit réseau dédié pour y mettre les services sur lesquels équilibrer la charge ainsi que la patte du load balancer qui leur servira de passerelle. Dans notre laboratoire de test, notre réseau contenant le client et la patte externe du load balancer est en 192.168.45.0/24. Il contient le client en 192.168.45.2 et le load balancer OpenBSD hébergeant Relayd en 192.168.45.3 (interface em0, celle de gauche du load balancer sur la figure 1). Le réseau dédié aux services sur lesquels équilibrer la charge est en 192.168.46.0/24. On y trouve deux serveurs web web1 et web2 respectivement en 192.168.46.11 et 192.168.46.12 avec une patte du load balancer en 192.168.46.1 (interface em1, celle de droite du load balancer sur la figure 1 et également passerelle par défaut de web1 et web2). Nous allons donc équilibrer la charge de 2 serveurs web via une redirection de Relayd.
La première chose à faire est de créer un alias IP (en 192.168.45.4) sur la patte du load balancer accessible par le client. Nous y placerons la socket réseau chargée de récupérer les requêtes du client. Nous aurions pu utiliser l’adresse « réelle » du load balancer, mais il est - à notre avis - plus propre de dédier une IP par paradigme d’équilibrage. Donc, allons sur le load balancer OpenBSD pour ajouter un alias en 192.168.45.4 sur l’interface em0 ayant comme adresse IP principale 192.168.45.3. Cela se passe dans le fichier /etc/hostname.em0 :
Et aussi em1 :
Il faut également activer l’IP forwarding pour que les paquets transférés puissent passer d’une interface à l’autre :
Ensuite, nous nous attaquons à Relayd. Il faut commencer par le configurer. La configuration se trouve dans /etc/relayd.conf :
Le fichier démarre avec 3 variables : web1, web2 et ext_addr_l3 qui sont respectivement l’adresse des deux serveurs web et celle sur laquelle Relayd écoute les requêtes à leur transférer. Cette dernière adresse est enregistrée dans le DNS comme www.lab.local. C’est-à-dire que le trafic à destination de cette adresse est orienté sur l’un ou l’autre des deux serveurs web. L’attribut interval donne la fréquence en secondes des contrôles de disponibilité des services derrière le load balancer. La table nommée webhosts regroupe les deux serveurs web. C’est cet objet qui sera pris en compte dans les règles de load balancing.
Enfin, vient la règle de redirection. On la déclare avec le mot-clé redirect suivi du nom de la redirection (l3-www dans notre exemple). La première chose à faire est de lui déclarer sur quelle adresse il doit écouter avec la directive listen on suivie de la variable que nous avons définie en tête de fichier. On spécifie également le port avec la directive port et derrière on lui met soit le numéro, soit la chaîne de caractères mappée par le fichier /etc/services. La ligne se termine par la définition de l’interface réseau (ici em0). La seconde ligne concerne l’adjonction d’un tag pftag (ici RELAYD). Ce tag laisse la possibilité à l’utilisateur d’ajouter des règles dans PF relatives à ce tag (exemple : pass in tagged RELAYD…). La dernière ligne indique une redirection du trafic vers les machines appartenant à la table contenant les deux serveurs web forward to <webhosts>. On vérifie également que les serveurs sont opérationnels en récupérant un code 200 après une requête http (check http) à la racine /. Pour injecter ces règles dans PF, Relayd s’appuie sur une anchor définie dans le fichier /etc/pf.conf. Voyons la configuration côté PF :
On retrouve bien la ligne anchor permettant à Relayd d’ajouter ses règles (2ème ligne). La dernière ligne définit un NAT pour toutes les machines du réseau interne au load balancer. Il est important de la définir après l’anchor, car Relayd va lui-même faire traverser des paquets par le load balancer pour répondre aux clients. Voyons d’ailleurs ce qu’il y a dans l’anchor :
On voit bien que la règle générée par Relayd est une redirection de port (rdr-to) vers une table (au sens PF) nommée l3-www (le même nom que notre règle redirect) en mode Round Robin. Activons et démarrons le service Relayd :
Voyons la répartition :
Les requêtes sont bien réparties à 50/50. Cependant, il peut arriver que nous souhaitions associer un client avec toujours le même serveur (par exemple si le serveur stocke localement des données de session). Dans ce cas, il faut activer l’option sticky-address dans Relayd :
Si on affiche à nouveau l’anchor, on voit bien que la règle aura été modifiée pour ajouter sticky-address après round-robin. Et cette fois-ci :
Le load balancer nous sert bien 1000 fois la même machine (web1).
2.3 Les relais
Les relais diffèrent des redirections dans la mesure où le load balancer accepte la connexion du client et établit lui-même une nouvelle connexion avec le service ciblé agissant comme un proxy. Ce proxy peut ne manipuler des données qu’au niveau transport ou inférieur du modèle OSI (L4) ou décoder les données applicatives (L7) s’il possède le processeur de protocole adapté. Un relai se crée en utilisant une règle de type « relay ».
2.3.1 Le relai L4
Nous allons mettre en place un load balancer devant deux serveurs embarquant un serveur SSH. Cette fois-ci, les services ne sont pas nécessairement « derrière » le load balancer vu qu’il agit comme un proxy. Dans notre cas test, tout le monde est sur le même réseau 192.168.45.0/24 comme indiqué dans la figure 2. On notera que contrairement aux redirections, ici il n y a pas de modification à effectuer sur PF. On peut très bien mettre le pf.conf à blanc. Avant tout, il faut penser à créer un nouvel alias sur em0 du load balancer en 192.168.45.5 et lui créer une entrée ssh.lab.local dans le DNS pour accueillir le trafic SSH. Voyons ensuite la configuration dans le fichier relayd.conf :
Le début est identique à l’exemple précédent. Une nouveauté est la règle tcp protocol. Cette règle permet de gérer la couche TCP des paquets que le relai va gérer. Ici, on active le nodelay, car SSH est un protocole foncièrement interactif et on met la taille du buffer de la socket au maximum, soit 65536 (les machines sont très proches, les risques d’erreurs sont faibles donc on peut espacer les ACK au maximum).
Enfin, on peut créer le relai que nous nommerons l4-ssh : relay l4-ssh. Sur la première ligne, rien de neuf, on écoute sur le port 6822. La seconde ligne applique le protocole créé dans la section précédente pour adapter le comportement de la session TCP entre le load balancer et le service cible. Enfin, la dernière ligne transfère le trafic SSH vers les deux serveurs embarquant le service forward to <sshhosts> port 22. Elle vérifie également que les deux serveurs sont accessibles via un contrôle de la socket TCP du serveur SSH check tcp. Pour vérifier le résultat, nous avons configuré les deux serveurs avec accès par clé SSH et nous passons la commande hostname en paramètre de ma connexion SSH :
Les connexions SSH sont donc bien réparties à 50/50 sur les deux serveurs.
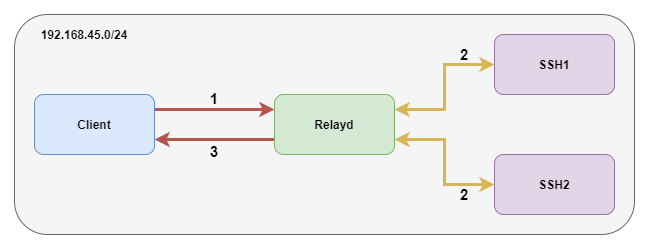
2.3.2 Le relai L7
Nous allons repartir sur un exemple basé sur le Web avec deux serveurs web (web3 et web4) situés sur le même réseau que le client. Nous créons un alias en 192.168.45.6 sur l’interface em0 du load balancer et nous lui associons le nom pleinement qualifié www-curl.lab.local. Le but de cet exemple est de bloquer les navigateurs présentant un certain « User Agent » (ici la chaîne de caractères badcurl). Voyons la configuration de Relayd :
La grosse nouveauté ici est que l’on a changé le protocole de tcp protocol vers http protocol. C’est ici que s’opère le passage du L4 de l’exemple précédent vers le L7 de celui-ci. Le passage au L7 (application) nous donne accès aux attributs de la requête HTTP et donc au champ User-Agent. C’est la seconde ligne de la section protocol qui va bloquer tous les navigateurs se présentant avec le User-Agent à badcurl. Dans la règle de relai, rien de nouveau à part la mention du mode loadbalance qui va associer mon client au serveur web3 ou web4 de façon durable à la manière du « stick-address » de la redirection, mais au niveau transport plutôt que réseau (donc un client a un couple IP/port destination plutôt qu’une IP destination seule). Voyons le résultat :
Toutes nos requêtes sont bien envoyées sur web4. Maintenant, forgeons notre User-Agent à badcurl avec l’option -A de curl :
Comme prévu, la requête échoue.
2.3.3 Le relai accélération SSL/TLS
Cette dernière section sur les relais introduit la possibilité pour Relayd d’exposer une socket SSL, recevoir du trafic dessus et le réexpédier dans un canal en clair vers les services load balancés. Nous allons réutiliser les serveurs web web3 et web4 de l’exemple précédent conformément à la figure 3 qui présente le canal chiffré entre le client et Relayd (côté gauche) et le canal en clair entre Relayd et web3/web4 (côté droit).
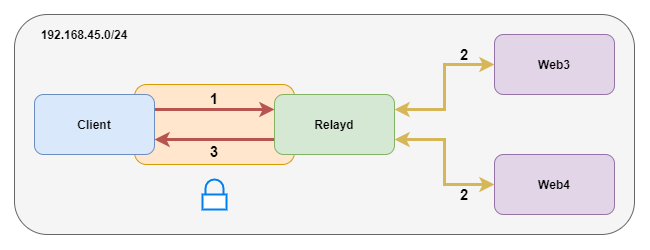
Comme d’habitude, nous créons un alias dédié sur le load balancer en 192.168.45.7 avec comme nom pleinement qualifié www-ssl.lab.local. Comme la socket créée sur le load balancer n’est pas une socket TCP standard, mais une socket SSL, il lui faut un certificat [4]. C’est la partie pas forcément bien super documentée (merci ktrace et kdump) dans les pages de man de Relayd. En effet, il faut créer un certificat de la forme @IP:Port.crt dans /etc/ssl et la clé privée associée @IP:Port.key dans /etc/ssl/private. Nous avons utilisé openssl pour générer un auto-signé :
Nous voyons que nous générons bien une clé privée (sans passphrase) dans le fichier /etc/ssl/private/192.168.45.7:443.key (eq -newkey rsa:4096 -nodes keyout) et le certificat auto-signé associé dans /etc/ssl/192.168.45.7:443.crt (-x509 -days 365 -out). Voyons maintenant la configuration de Relayd :
Nous utilisons à nouveau le processeur de protocole HTTP. Nous ajoutons des informations dans l’en-tête notamment l’origine réelle de la requête X-Forwarded-For, celle du load balancer X-Forwarded-By. Nous introduisons aussi des contraintes sur la version de TLS à utiliser (strictement supérieure à 1.0 et algorithmes forts pour les clés de session). Pour la définition du relai, la nouveauté est que l’on précise que la socket doit être créée en TLS par l’attribut tls à la fin de la ligne. Sinon c’est du déjà-vu. Pour réaliser le test avec curl, il faut lui demander d’accepter les certificats auto-signés avec l’argument -k :
On a presque du 50/50. L’accélération SSL/TLS est un succès ! Nous allons maintenant passer à la configuration de load balancers plus abstraits dans les environnements Cloud.
3. Le load balancing dans Kubernetes
Kubernetes est un orchestrateur de conteneurs populaire dans les environnements Cloud. Il permet notamment de piloter des processus applicatifs conteneurisés et distribués sur plusieurs machines, ces dernières formant ainsi un cluster. Cette technologie permet d’adresser plusieurs problématiques d’une plateforme applicative. Nous pouvons citer parmi elles et de manière non exhaustive : la tolérance aux pannes, la communication interprocessus, la topologie et l’équilibrage de charge entre ceux-ci. Dans la partie qui suit, nous détaillerons l’équilibrage de charge à plusieurs niveaux au moyen de plusieurs fonctionnalités : L4 avec la fonctionnalité Service, L7 avec Ingress et enfin nous démontrerons le caractère dynamique du load balancing lorsque nous multiplierons automatiquement le nombre d’instances de notre application via un mécanisme que nous aborderons le moment venu.
3.1 Environnement de démonstration
Afin de pouvoir jouer les démonstrations qui suivront, il faudra un cluster Kubernetes et pour ce faire, nous utiliserons minikube. Il s'agit de l'un des projets officiels de Kubernetes. Destiné à du développement et à du test, il permet de créer localement un cluster Kubernetes. Par défaut, celui-ci ne crée qu'un seul nœud, mais il peut être paramétré pour en créer plusieurs. La méthode d'instanciation peut aussi être choisie, entre virtualisation et conteneurisation, selon le pilote désigné.
Nous allons déployer un cluster de trois nœuds conteneurisés au moyen du pilote docker de minikube. La version de Kubernetes utilisée est la 1.20.2.
Une machine avec docker, minikube et kubectl installés est nécessaire, différentes distributions de ceux-ci existent selon votre environnement. Les démonstrations qui suivent ont été réalisées sur une Ubuntu 20.04 avec un noyau Linux 5.8.0.
Pour commencer, nous créons notre cluster local :
Vérification du statut des nœuds :
D'abord quelques clarifications sur la terminologie s'imposent. Nous avons déployé trois nœuds via Docker dont un master et deux worker, ces derniers sont aussi appelés minions. Avec Kubernetes, nous ne manipulons jamais des conteneurs directement, mais des pods. Un pod est une entité logique incluant un ou plusieurs conteneurs [5]. Idéalement et dans la vision des architectures de micro-services, un pod incarne un processus unique conteneurisé, possiblement assisté d'autres conteneurs, remplissant des tâches subalternes pour ce premier telles que l’extraction de logs ou bien de métriques par exemple. Un pod est atomique du point de vue du cluster et donc insécable, autrement dit, les conteneurs d'un pod seront planifiés sur un même nœud et s'il y a réplication alors tous les conteneurs seront reproduits pour chaque réplicat supplémentaire : c'est bien le pod qui est répliqué.
Maintenant, nous allons procéder au déploiement d'une application web. Pour ce faire, nous utilisons le type de ressource Deployment qui permet, entre autres, de manipuler un jeu de réplications de pods [6]. Nous instancierons trois réplicats de ladite application.
Nous utiliserons l'image publique containous/whoami:v1.5.0 du Docker Hub pour les démonstrations qui suivront dans cet article. Il s'agit d'une application web succincte affichant quelques informations sur le système comme son nom d'hôte ou encore son adresse IP. La mise en lumière du mécanisme de load balancing en sera ainsi plus évidente que si nous avions utilisé un serveur web nu. Les démonstrations peuvent cependant fonctionner avec d'autres applications web.
Il est temps de déclarer notre application via Deployment en créant un fichier whoami-deployment.yaml :
Application de notre Deployment :
Vérification :
Nos trois pods ont été déployés et sont prêts (READY 3/3). Cependant, nous n'avons pas défini encore comment y accéder. Voyons d’abord quelques notions de la gestion du réseau au sein d'un cluster Kubernetes. Il faut savoir que lorsque nous créons un pod, une adresse IP privée lui est automatiquement assignée [7]. Celle-ci est consultable de la façon suivante :
Ci-dessus, les sous-réseaux 10.244.1.0/24 et 10.244.2.0/24 correspondent respectivement à nos worker, minikube-m02 et minikube-m03. Il se peut que ces informations changent quelque peu avec votre environnement, mais la logique décrite ici devrait être conservée. Ces adresses IP sont routées par chaque nœud du cluster. Connexion au nœud master :
Sur le nœud master :
192.168.49.3 et 192.168.49.4 désignent respectivement les adresses de nos nœuds minikube-m02 et minikube-m03.
Bien que nos pods possèdent effectivement une adresse IP, ceux-ci ont un cycle de vie éphémère et, ce faisant, leurs adresses souffrent du même statut. Rien ne nous garantit que les pods de notre Deployment conserveront ces dernières. Ce sont donc des points d'entrée médiocres pour accéder durablement à notre application. Il reste donc à déterminer comment exposer durablement cette dernière et répartir la charge entre chaque instance qui la compose.
3.2 Load balancing L4 avec Service
Pour résoudre cette problématique, nous pouvons manipuler un type de ressource du cluster appelé Service. C'est une entité logique à laquelle est assignée une adresse IP virtuelle privée, durable et indépendante du cycle de vie des pods qu'elle expose [8]. Cette adresse est usuellement appelée clusterIP. Le Service remplit aussi les fonctions d'un load balancer L4, ce que nous vérifierons.
Les Services de Kubernetes ont eux-mêmes plusieurs types, chacun décrivant une méthode d'exposition. Dans l'exemple ci-après, nous utilisons un type NodePort. Celui-ci ouvre le port désiré en écoute sur chacun des nœuds du cluster. Chaque paquet destiné à ce port sur l'un de nos nœuds sera transféré dans un premier temps vers la clusterIP et le port du Service pour enfin être dispatché sur le port d'une des adresses des pods exposés.
La figure 4 illustre l'architecture que nous obtiendrons.
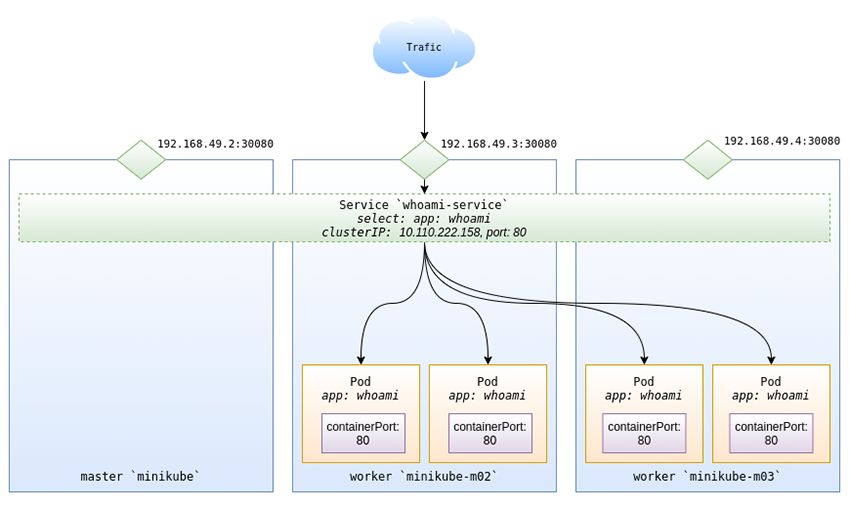
Pour commencer, nous créons un fichier whoami-service.yaml spécifiant notre service :
Application de notre Service :
Vérification :
Notre Service a bien été créé et s'est vu affecter, dans le cas présent, l'IP virtuelle (clusterIP) 10.102.158.131. Afin de démontrer plus tard le caractère dynamique du load balancing entre chaque instance de notre application, nous allons d'abord ramener le nombre de réplicats de notre déploiement whoami-deployment à un seul pod :
Vérification :
Ensuite, il nous faut récupérer l'adresse IP de l'un des nœuds de notre cluster. Nous pouvons les obtenir comme ceci :
Testons si nous arrivons à joindre notre application whoami via le port 30080 de notre nœud master minikube :
Nous pouvons tester si nous arrivons à joindre notre application via un autre nœud, prenons minikube-m03.
Maintenant nous allons ramener le nombre de réplicats à quatre pods (ou tout autre nombre de votre choix) :
Testons si le load balancing est effectif :
La variation des champs Hostname et IP prouve que le load balancing entre nos différents pods via notre Service est bien effectif.
La fonctionnalité des Services au sein du cluster est assurée par un composant appelé kube-proxy. Il est déployé sur chacun des nœuds du cluster sous la forme d'un pod. Par défaut, il est configuré pour utiliser iptables, ce mode est appelé iptables proxy mode. Le composant regarde en permanence l'état des ressources Service déclarées dans notre cluster. Pour chacune d'entre elles, il déploie des règles iptables capturant le trafic du port de la clusterIP du Service pour enfin le rediriger vers les pods exposés par ce dernier.
Quand kube-proxy est en iptables proxy mode, la sélection du pod vers lequel est redirigé le trafic est aléatoire. Il existe cependant un autre mode opératoire nous permettant de choisir d'autres méthodes de load balancing.
En effet, il est possible de configurer le composant kube-proxy pour que celui-ci opère via la fonctionnalité IPVS du noyau Linux offrant des méthodes de load balancing plus avancées. Ce mode est appelé IPVS proxy mode.
Dans ce mode, kube-proxy se sert de l'interface netlink du noyau Linux pour produire des règles IPVS. IPVS proxy mode est préféré pour sa latence de communication moindre et sa performance supérieure sur la synchronisation des règles au sein du cluster. De plus, ce mode propose diverses méthodes de load balancing, parmi elles : round robin, least connection, source hashing, destination hashing, etc.
Dans cette partie, nous avons vu comment mettre en place un load balancing L4 et, qui plus est, distribué sur plusieurs machines au moyen de Kubernetes et de sa ressource Service. Cependant, dans le cadre du déploiement d'une application web, cela reste insatisfaisant. Usuellement, nous accédons une application web en nous servant d'une route HTTP plutôt qu'en joignant un port arbitrairement défini. Dans la partie suivante, nous allons voir comment obtenir ce comportement au moyen de Kubernetes.
3.3 Load balancing L7 avec Ingress
Sans surprise, nous allons utiliser un autre type de ressource : Ingress. Typiquement, celle-ci expose des routes HTTP ou HTTPS joignables depuis l'extérieur du cluster vers un Service. Le routage du trafic est défini par des règles déclarées dans la spécification de notre ressource [9].
Similairement aux ressources Service avec kube-proxy, les Ingress ont aussi un composant du cluster associé les administrant, nommé ingress-controller. À la différence de kube-proxy, celui-ci n'est pas présent par défaut au sein d'un cluster Kubernetes. Cela étant, minikube nous permet d'en ajouter un facilement au moyen de la commande suivante :
Le composant ingress-controller livré avec minikube est in fine un NGINX, distribué spécialement pour remplir ce rôle, aussi appelé NGINX Ingress Controller. Il s'agit d'un load balancer L7 avec des fonctionnalités similaires à httpd d'Apache ou encore à haproxy. D'ailleurs, NGINX Ingress Controller n'est pas le seul modèle de composant ingress-controller existant.
Au moyen d'un Ingress, nous allons créer une route HTTP avec pour backend notre service whoami-service. Nous l'exposerons sur le chemin /whoami de notre load balancer. La figure 5 illustre notre architecture.
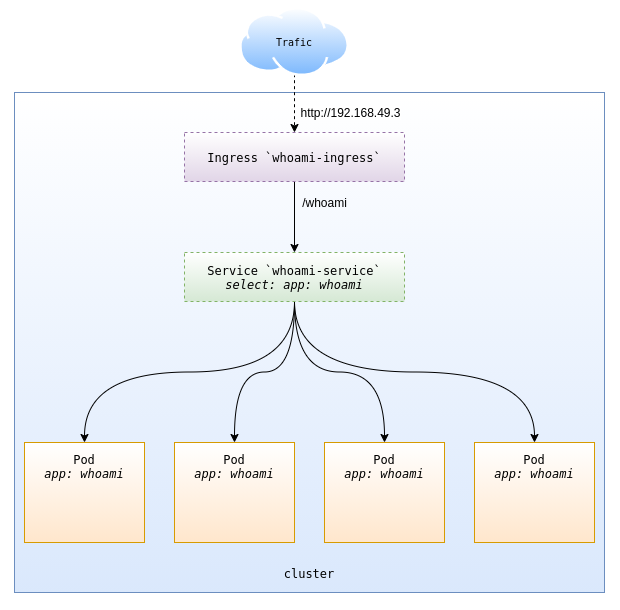
Nous commençons par créer un fichier whoami-ingress.yaml spécifiant notre Ingress :
Application de notre Ingress :
Vérification :
Testons de joindre notre service par l'adresse de notre Ingress (ici : 192.168.49.3) et en utilisant la route que nous avons définie :
Notre Ingress expose bien notre Service. Il est important de noter que ce dernier n'a plus besoin d'être en NodePort, dorénavant notre Ingress sera notre point d'entrée privilégié. De plus, il faut contacter notre route HTTP via une adresse IP précise (dans notre exemple : 192.168.49.3), a contrario du type d'exposition NodePort, où le point d'entrée était distribué sur toutes les adresses des nœuds de notre cluster.
Ceci est dû à la nature du déploiement du composant ingress-controller de minikube. Celui-ci est incarné par un pod planifié sur un seul nœud, mais il est possible d'avoir plus d'un pod ingress-controller réparti sur plusieurs nœuds du cluster, distribuant ainsi la fonctionnalité de load balancing L7 sur une plus large portion du cluster, plutôt que sur un nœud unique.
Il est utile de noter qu'il est possible de configurer une ressource Ingress pour obtenir de la persistance de session ou encore de formuler des règles pour se servir d'un nom d'hôte plutôt qu'une route comme discriminant, à la manière d'un VirtualHost dans la terminologie de httpd d'Apache.
Dans cette section, nous avons vu comment déployer un load balancer L7 avec des règles de routage HTTP redirigeant vers notre Service. Dans la suivante, nous verrons comment, en fonction de la charge CPU de notre application, nous multiplierons les backends disponibles et constaterons l’adaptation automatique de notre mécanisme de load balancing configuré auparavant.
3.4 Autoscaling horizontal avec HPA
Avec Kubernetes, il est possible d'obtenir ce que l'on appelle de l'autoscaling horizontal. C'est-à-dire que le nombre d'instances d'une application est incrémenté automatiquement en fonction d'une information [10]. On différencie l'autoscaling horizontal du vertical comme suit : l'horizontal ajoute ou supprime des instances applicatives alors que le vertical modifie l'allocation des ressources CPU et RAM d'une instance. Seul l'autoscaling horizontal sera abordé dans cet article, car il se prête à un scénario de load balancing. En effet, l'objectif ici est de répliquer automatiquement des pods et de constater que nos load balancer, énoncés dans les parties précédentes, s'adaptent.
Le type de ressource pour décrire un tel mécanisme est appelé HorizontalPodAutoscaler par Kubernetes. Souvent désigné par l'abréviation HPA, qui sera le terme utilisé pour la suite de l'article. Celui-ci pilotera notre Deployment whoami-deployment en lui commandant de créer des réplicats ou même d'en détruire si nécessaire. La figure 6 illustre notre architecture.
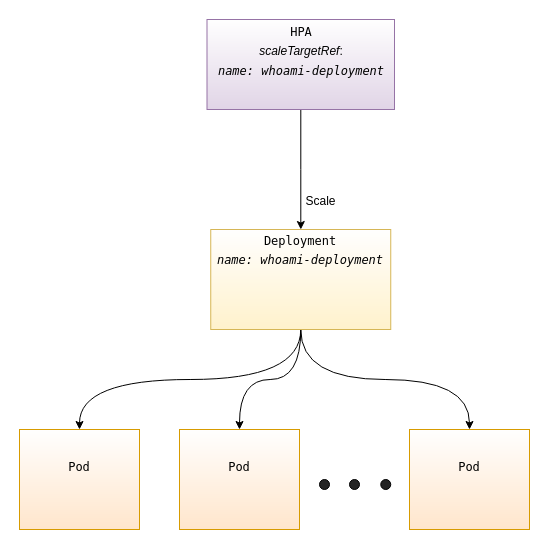
Pour notre démonstration, l'information que nous allons utiliser pour déclencher notre autoscaling sera la consommation CPU actuelle. Pour obtenir cette dernière, il faut installer un composant supplémentaire dans notre cluster appelé metrics-server. Il s'agit d'un collecteur de métriques rapportant la consommation RAM et CPU des conteneurs présents dans le cluster. Il est dévoué à l'usage des fonctionnalités d'autoscaling de Kubernetes.
Une fois encore, minikube nous facilite le travail en nous permettant l'installation du composant sous la forme d'un addon, à l'instar du composant ingress-controller :
Dans un premier temps, il nous faut modifier notre Deployment pour que l'autoscaling puisse fonctionner. Il faut ajouter la réservation CPU pour les conteneurs de ce premier, celle-ci informe le cluster quelle quantité minimale de CPU il faut pouvoir planifier pour un conteneur. Le metrics-server calcule l'utilisation CPU d'un Deployment en agrégeant la consommation CPU de chacun des conteneurs déclarés via les pods de celui-ci par rapport à leur réservation CPU respective. Modifions notre fichier whoami-deployment.yaml :
Nous repassons aussi le nombre de réplicats de notre Deployment à un pod pour la démonstration :
Nous déclarons ensuite notre HPA dans un nouveau fichier whoami-hpa.yaml :
Appliquons maintenant notre HPA :
Vérification :
La formule qu'utilise le HPA pour calculer le nombre de réplicats est la suivante :
Pour constater le fonctionnement de notre HPA, il nous faut ouvrir un second terminal. Dans le premier, nous surveillons l'état de notre HPA et le nombre de pods présent :
Dans le second, nous allons provoquer rapidement des requêtes HTTP via notre Ingress afin de faire monter la consommation CPU :
Sur le premier terminal, au bout de quelques secondes, nous observons que de nouveaux pods sont instanciés en réponse à l'augmentation de la consommation CPU relevée par le HPA :
En inspectant la sortie du second terminal, nous remarquons que nous avons obtenu des réponses à nos requêtes venant de nos nouveaux pods instanciés automatiquement :
Nous avons bien mis en place un mécanisme, au moyen de Kubernetes, permettant d'augmenter dynamiquement le nombre d'instances de notre application en fonction d'une charge CPU distribuée tout en répartissant les requêtes entrantes sur ces nouvelles instances automatiquement.
Il faut noter que ce format de HPA n'est pas le seul qui existe. Un autre plus élaboré est disponible dans la version autoscaling/v2beta2 de l'API de Kubernetes. Celui-ci permet de surveiller d'autres métriques que la consommation CPU et même des métriques personnalisées pouvant provenir de services de supervision externes. Ce format n'est cependant pas encore stable à ce jour, mais permet déjà une utilisation plus poussée tout en conservant les mêmes principes que nous avons vus plus tôt.
Conclusion
Dans cet article, nous avons couvert les load balancers traditionnels ainsi que leurs avatars contemporains dans le Cloud. Nous avons également vu comment connecter ces derniers au monitoring des ressources pour profiter de la propriété d’élasticité de l’informatique en nuage. Avec les ressources de son API, Kubernetes nous permet de définir une application web distribuée avec des fonctionnalités de load balancing dynamique, pouvant même s'adapter à des événements de celle-ci, comme l'augmentation de la consommation CPU et ce, en quelques instants. Si ces fonctionnalités ont été vues succinctement pour démontrer leur principe premier, nous vous encourageons à élaborer vos configurations pour toucher les limites de celles-ci. Vous pourriez aussi tester avec une véritable application web ou essayer de reproduire les mêmes principes de fonctionnement avec une application utilisant un autre protocole que HTTP ou encore une application avec des contraintes de persistance de session et enfin pourquoi pas essayer de mettre en place du SSL/TLS ?
Références
[2] https://www.openbsd.org/faq/pf/
[3] https://www.openbsd.org/faq/pf/rdr.html
[4] https://connect.ed-diamond.com/Linux-Pratique/LP-123/Les-certificats-de-l-emission-a-la-revocation
[5] https://kubernetes.io/docs/concepts/workloads/pods/
[6] https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
[7] https://kubernetes.io/docs/concepts/cluster-administration/networking/
[8] https://kubernetes.io/docs/concepts/services-networking/service/
[9] https://kubernetes.io/docs/concepts/services-networking/ingress/
[10] https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
