

Dans le cadre de réponses sur incidents, les CERT/CSIRT peuvent être amenés à réaliser des analyses post-mortem à partir des disques ou plus généralement de supports de stockage. Ainsi, il est proposé dans cet article d’énumérer les requis pour collecter, stocker, utiliser efficacement une copie de disque en vue d’une analyse forensique. Nous détaillerons comment le format EWF met en œuvre ses besoins, et en décrirons suffisamment les principes techniques pour savoir accéder à un secteur précis dans l’image du disque.
Avant de comprendre comment cela est mis en œuvre par le format de données, voyons d’abord ce que l’on attend d’un format capable d’imager un disque (en stocker une copie fidèle). Enfin, EWF signifie Expert Witness Format, ce qui est moins groovy qu’un groupe des années 70.
1. Propriétés nécessaires à un format d’image disque pour le forensique
Effectuer une copie secteur par secteur : c’est une méthode courante et la plus fidèle pour réaliser une image du support de stockage rapidement. Cela autorise également l’analyse ultérieure des 3 niveaux de données : 1 - l’amorce du disque, les partitions ; 2 - les systèmes de fichiers, les données effacées ou cachées ; 3 - ainsi que les métadonnées de ces 3 niveaux.
Aujourd’hui, il est courant d’avoir à copier plusieurs centaines de gigaoctets ou plusieurs téras, ainsi l’utilisation de la compression est indispensable.
Mais on doit pouvoir utiliser le fichier image comme « disque virtuel », pour notre analyse forensique, ce qui implique de pouvoir adresser directement n’importe quel secteur dans l’image, comme sur un disque physique. Cette dernière propriété est incompatible avec la compression de l’image complète. Il est donc logique de découper l’image en plusieurs parties, compressées, et il est pratique qu’elles contiennent un nombre entier de secteurs, car c’est l’unité élémentaire de stockage sur un support.
Afin de s’assurer que plusieurs copies d’un même disque sont identiques et de leur intégrité (requis par un juge dans le cadre d'une expertise judiciaire), on utilisera un algorithme de haché cryptographique comme MD5 ou SHA1. Le format devra également permettre de stocker les métadonnées du disque, comme le numéro de série, le modèle, et les propriétés du support, qu’il soit SSD ou magnétique.
Lors de la création de l’image, on doit archiver/compresser les secteurs à la volée, mais également les métadonnées nécessaires à la lecture ultérieure des secteurs « originaux ».
Le format EWF, développé vers 2002 par la société ASRDATA [ASRDATA], a été le premier format de stockage offrant les fonctionnalités citées précédemment, et qui justement font défaut au format « raw » historique : compression, métadonnées et contrôle d’intégrité.
2. Le format EWF / Encase / E01
2.1 Origines et multiples versions
Comme il existe de multiples versions du format EWF, dans la suite de l’article nous parlerons de la plus courante, la version 1, celle utilisant les caractères « E01 » comme extension pour le premier fichier de l’image, celle utilisée par Encase 4, implémentation de référence de l’éditeur Guidance Software. Aucune documentation officielle n’est disponible, hormis celle d’ASRDATA, très succincte. C’est Michael « Scudette » Cohen qui fût le premier à réaliser une implémentation open source dès 2004 [LIBEVF], travail repris en 2006 par Joachim Metz qui propose une spécification détaillée des variants EWF et une bibliothèque [LIBEWF]. Cette implémentation est utilisée par Ewfacquire [EWFACQUIRE]. FTK lmager [FTKIMAGER] utilise une implémentation maison (ADI) et compatible.
2.2 Description générale du format EWF
La description du format ne sera pas exhaustive, il y a [LIBEWF] pour cela, mais suffisante pour en comprendre les grands principes, ses avantages et ses inconvénients, et retrouver les données d’un secteur original.
2.2.1 Segments
Tout d’abord, l’image est divisée en plusieurs fichiers nommés « segments », par défaut de 1500Mo. Les extensions de fichiers de ces segments sont énumérées de E01 à E99, puis EAA, EAB, jusqu’à EZZ, puis FZZ, ... jusqu’à ZZZ, ce qui est compatible avec l’ordre lexicographique. Ceci est pratique, car lors de la création d’une image, les segments sont créés dans cet ordre, par ordre croissant des secteurs archivés. Dans l’exemple ci-dessous, on trouve l’image d’une clé USB de 4Go, découpée en 3 segments et fichiers :
2.2.2 Compression par « chunk »
Dans chaque segment, les secteurs du disque original sont regroupés en séquence, par « chunks », ces derniers pouvant être compressés si cela est utile, lorsque le chiffrement est absent, par exemple. C’est un bon compromis entre compresser chaque secteur et le disque original en entier, comme avec le format « raw ». La taille d’un chunk est de 64 secteurs par défaut. Le format et l’algorithme de compression sont Zlib/Deflate [ZLIB][DEFLATE].
À l’intérieur des fichiers segments, l’information est organisée par « sections », notamment et dans cet ordre :
- Header section : au début de chaque segment, contient le numéro de segment ;
- les sections Volume ou Disk : elles contiennent le nombre total de chunks et des secteurs de l’image, la taille d’un chunk et d’un secteur ;
- Sectors section : qui contient les chunks ;
- Table section : qui contient des pointeurs sur les chunks du segment, compressés ou non ;
- à la fin d’un segment, une section Next ou Done, pour indiquer qu’il existe un segment suivant, ou non ;
- les sections Hash ou Digest pour stocker les hachés comme MD5 et SHA1, dans le dernier segment. SHA256 est également disponible, mais non utilisé par défaut.
De même que l’ordre des segments, l’ordre des sections dans un segment est chronologique à la lecture du média original, secteur par secteur : on écrit d’abord les métadonnées (sections Header et Volume), puis les données elles-mêmes (Sectors), puis comment accéder à ces données (Table).
Examinons maintenant plus en détail les segments et les sections qu’ils contiennent.
2.3 Voyons cela d’un peu plus près
Un segment commence la chaîne signature suivante (format Python) :
puis une liste chaînée de sections comme sur la figure 1.
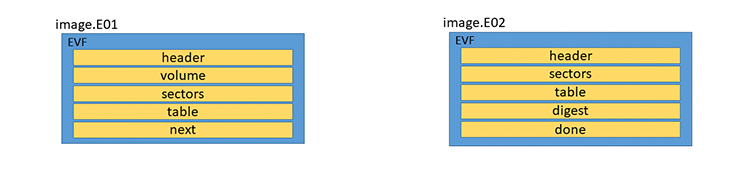
Toutes les sections commencent par une description générique, avec les données ci-dessous.
2.3.1 Entête générique des sections
|
Offset |
Type |
Taille en octets |
Champ |
Commentaire ou exemple |
|
0 |
char |
16 |
marqueur |
b'sectors\x00\x00\x00\x00\x00\x00\x00\x00\x00' |
|
16 |
long |
1 |
next |
Offset dans le segment |
|
20 |
long |
1 |
size |
Y compris l’entête |
|
24 |
char |
40 |
padding |
0 |
|
64 |
long |
1 |
Crc |
adler32 |
Voyons ensuite comment accéder aux chunks.
2.4 Quelques sections importantes
Les 2 sections les plus importantes sont Table et Sectors.
2.4.1 Section Table
Après l’entête de la section décrite précédemment, nous avons la structure suivante :
|
Offset |
Type |
Taille |
Champ |
Commentaire ou exemple |
|
0 |
long |
1 |
Chunk count |
62184 par exemple par segment |
|
4 |
byte |
4 |
padding1 |
0 |
|
8 |
longlong |
1 |
base |
Offset de la section Sectors dans le segment |
|
16 |
byte |
4 |
padding2 |
0 |
|
20 |
long |
1 |
Crc |
Adler32 of data[:64] |
|
24 |
long[] |
Chunk count |
pointers |
Pointeurs dans la section Sectors (31 bits). Le bit#31 de point fort indique la compression |
|
Chunk count+24 |
long |
1 |
Crc |
Adler32 de la table pointers[] |
Cette section est stockée 2 fois par segment, dans la section « table » et « table2 », identiques, sans doute pour redondance. En effet, il serait difficile de retrouver sans erreur le début de chaque chunk sans cette « Table ».
2.4.2 Section Sectors
Après l’entête de la section, chaque chunk est stocké tel quel, en séquence, compressé ou non. À la fin de la section se trouve une somme de contrôle Adler32, pour vérifier l’intégrité des données des chunks.
2.4.3 Sections Disk et Volume
Comme déjà écrit, elles contiennent des données sur l’image, les chunks et les secteurs, de façon similaire. La section Volume semble une évolution de la section Disk.
2.4.4 Sections Hash et Digest
Ici sont stockés les hashs cryptographiques MD5 et/ou SHA1 de l’image originale complète (avant d’être découpée en chunks). Il est possible également d’ajouter SHA256.
Maintenant que nous avons bien compris la structure de données du format EWF, passons maintenant à la pratique : comment « monter » l’image, c’est-à-dire accéder aux données des secteurs originaux.
3. Montage de l’image comme disque virtuel
À partir des éléments décrits précédemment, voici les principes pour utiliser l’image comme disque virtuel, que nous compléterons à la fin de l’article par un exemple réel.
3.1 Algorithme général
-
Énumérer les fichiers segments (ordre lexicographique)
-
Pour chaque segment, vérifier la signature et parcourir la liste de sections
-
Pour chaque section de type :
-
[Volume ou Disk] : stocker le nombre de chunk de l’image, sa taille, celle d’un secteur
-
[Sectors] : on viendra lire, comme un read(), les données des secteurs originaux ici. Y sont stockés les chunks du segment (compressé ou non, en séquence)
-
[Table] : On récupère ici le nombre de chunk du segment (taille de la table), l’offset de la section Sector (base). Dans la table, pour chaque chunk du segment, on trouve : un pointeur sur 31 bits (offset dans Sector) et le bit de point fort indiquant s’il est compressé (1=compressed)
-
Il faut créer un index des chunk pour l’image, pour retrouver dans quel segment se trouve un chunk, car la taille d’un chunk varie avec la compression. Il faut aussi noter la fin de la section Sectors, pour lire le dernier chunk du segment, car la taille compressée n’est stockée nulle part.
Voyons justement comme lire le secteur numéro « sector ».
3.2 Accès à un secteur arbitraire dans une image EWF
Pour réaliser la fonction seek_ewf(sector), voici l’algorithme :
3.3 Pas très hexy cet article
Ok, ok, voyons juste un extrait de la section sectors et de la section table, pour trouver le début d’un chunk compressé...
En figure 2, le début de la section « sectors » : en rouge le marqueur (à l’offset 0x6f2, si si), en vert (0x5db7e7cf) la section suivante qui est « table », en orange la taille de la section (0x5db7e0dd, la majeure partie du segment), en violet la valeur Adler32 et enfin en bleu, le début du chunk compressé. Comment trouve-t-on cet offset 0x73e ? Avec la section Table juste en dessous et qui suit dans le segment.

Voici, en figure 3, le début de la section « table », à l’offset prévu dans la section précédente (next en vert), on y trouve : en rouge le marqueur, en violet la somme Adler32, en orange le nombre de chunks dans le segment (0xf2e8, soit 62184) et donc combien de pointeurs dans la Table. En vert pâle, on trouve la base (offset 0x6f2 de la section Sectors), une autre Adler32 et enfin le pointeur sur le premier chunk : 0x800004c. Il est compressé et le début des données Deflate est à base=0x6f2 + 0x4c = 0x73e.

Enfin, voici quelques éléments qui montrent que le format n’a pas de description officielle : FTK Imager utilise une section Disk plutôt que Volume, et n’utilise pas le champ base de la section Table : les pointeurs stockés ont comme base 0, c’est-à-dire le début du segment. Heureusement, le champ contient cette valeur.
4. Un driver EWF minimaliste en Python
Mettons en musique ce que nous avons appris précédemment sur un véritable exemple : celui de la clé USB en 3 segments vu au début de l’article. On lance notre outil d’analyse ewf.py avec de la verbosité et le nom du premier fichier de l’image : « usb.E01 », les 2 autres segments étant « usb.E02 » et « usb.E03 ».
Le code va donc énumérer chaque fichier/segment, puis en analyser chaque section. Voici le résultat :
Ci-dessus, chaque segment commence donc par un header « EVF », puis sur les lignes suivantes, chaque nom de section est préfixé par son offset dans le segment, et suffixé par les champs next et size.
Ci-dessous, l’outil affiche ensuite quelques statistiques résultant de l’analyse des métadonnées de l’image, vous vous souvenez de notre « algorithme général » plus haut ?
À noter que la valeur md5 ci-dessus a été calculée par l’outil sur les secteurs originaux et stockée dans la section hash, visible dans le segment #3.
Et si l’on calculait à nouveau le md5 de l’image, mais en utilisant seek() et read() de notre driver EWF ?
avec la fonction suivante :
Bingo, on obtient :
Et pour les curieux/ses, le code « jouet » en question est disponible sur GitHub [MINIEWF].
Conclusion : promesses tenues pour le format EWF ?
On ne va pas divulgâcher la fin, car ce format est utilisé depuis plus de 10 ans, mais oui, dans les grandes lignes : il offre la compression (avec les chunks), l’intégrité (avec Adler32), et l’on peut l’utiliser directement comme disque virtuel.
Quelles sont ces faiblesses ? On pourrait améliorer le contrôle d’intégrité des métadonnées (avec sha256), offrir le chiffrement à la volée des données, plusieurs flux de données (comme dans une archive ZIP) et pas simplement celui des secteurs, une compression plus rapide, un stockage moderne des métadonnées (JSON ?), une « chain of custody » de l’acquisition et de l’analyse du média garantie dans la blockchain ;-) ?
Le format AFF4 [AFF4] n’offre pas encore le chiffrement par exemple, mais certaines évolutions de EWF, si : Encase 7 et EWF2 proposent ainsi la compression bzip2 et le chiffrement AES256, mais cela reste non documenté.
Remerciements
Merci à Nidhal Ben Aloui et au rédacteur en chef pour leurs relectures attentives et suggestions.
Références
[ASRDATA] E01 Compression Format, ASRDATA, around 2002, http://www.asrdata.com/whitepaper-html/
[LIBEVF] libevf code source, Michael Cohen, 2008, https://github.com/py4n6/pyflag/blob/master/src/lib/libevf.c
[EWFACQUIRE] Ewfacquire code source, Joachim Metz, 2006-2021, https://github.com/libyal/libewf/blob/main/ewftools/ewfacquire.c
[LIBEWF] EWF specification, Joachim Metz, 2006-2020, https://github.com/libyal/libewf/blob/main/documentation/Expert%20Witness%20Compression%20Format%20(EWF).asciidoc
[FTKIMAGER] https://accessdata.com/products-services/forensic-toolkit-ftk/ftkimager
[ZLIB] ZLIB Compressed Data Format Specification version 3.3, 1996, https://datatracker.ietf.org/doc/html/rfc1950
[DEFLATE] DEFLATE Compressed Data Format Specification version 1.3, 1996, https://datatracker.ietf.org/doc/html/rfc1951
[AFF4] Advanced Forensic Format v4 imager and documentation, 2017, http://docs.aff4.org/en/latest/
[MINIEWF] https://github.com/lclevy/miniEwf



