

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Pour traiter les flux JSON, l'outil de prédilection est jq, un processeur léger et puissant, mais à la syntaxe déroutante. On trouve d'innombrables cheat-sheets pour réaliser toutes sortes d'opérations, mais si vous ne voulez pas vous contenter de tours de magie, accompagnez-moi quelques pages pour démystifier cette langue et prendre le contrôle de jq.
Il est fréquent de devoir scripter la transformation d’un fichier texte ou d’un résultat de programme, pour en extraire certaines informations. Il peut s'agir d'un flux de logs, d'un code source, d'un fichier de configuration, ou de la sortie de commandes du système. Lorsque les données d'intérêt, et les conditions qui les rendent intéressantes se trouvent sur une même ligne ou à proximité, les outils awk ou sed font souvent l'affaire. Mais ces automates programmables, très puissants, s'avèrent surtout efficaces lorsque les données sont tabulaires, ou sans schéma.
Or, de nombreuses API répondent en JSON, notamment dans le monde du DevOps. On peut en théorie construire (bonne chance) un programme sed pour extraire une propriété donnée objet JSON enfouie dans un tableau à une certaine position, mais ce ne serait clairement pas le bon outil. Premier défi, et loin d’être le seul, le formalisme JSON est indifférent aux sauts de lignes et aux espacements.
On pourrait s'orienter vers l'utilisation de Node, car qui ferait mieux que lui pour manipuler des objets JavaScript ? Mais il est trop généraliste. Il serait fastidieux et surdimensionné de dédier un programme complet, qui lise l'entrée standard et accomplisse traitements et boucles, là où on a seulement besoin de griffonner une solution ad hoc, légère, dans l'esprit des outils Unix à brancher les uns dans les autres.
Nous allons étudier le petit programme jq, spécialisé dans le traitement de flux JSON, pour en percer l’esprit et la syntaxe sur des cas pratiques.
1. Présentation
On doit l'outil jq [1] à Stephen Dolan. Le projet, sous licence MIT, a vu le jour en 2012 pour fournir une solution concernant les données JSON, sur laquelle les processeurs de textes usuels s'avèrent insuffisants. Il en résulte un véritable langage de programmation fonctionnel, aux propriétés insolites. On utilise couramment le terme jq pour désigner indifféremment le langage ou l'interpréteur. On y retrouve naturellement de nombreuses inspirations issues du JavaScript.
Malgré sa force, il serait inapproprié d'écrire des applications dans cette langue. On s'en servira plutôt de façon opportuniste pour assembler des prédicats afin d'extraire et transformer des documents JSON vers des sorties diverses, dans le cadre d'un pipeline de commandes système ou au retour d'une requête API.
2. Installation et découverte
Le programme est disponible dans les dépôts des distributions (exemple : apt install jq).
On peut aussi télécharger un binaire statique sur le site du projet (exécutable de 2.2 Mo pour amd64). Nous manipulons dans cet article la version 1.7.1.
Similairement à awk, on fait passer une entrée à travers jq avec un prédicat fourni en argument, et on obtient la transformée en sortie. Mais dans jq, l’entrée n’est pas consommée ligne à ligne : elle forme un ensemble JSON, insensible au formatage.
Par exemple, pour le document {"a": 10, "b": 20}, le prédicat .a + .b produit le simple nombre 30 (qui est également un document JSON à part entière) :
Les données, tout comme le prédicat (aussi appelé programme), peuvent être des fichiers comme ceci :
Le format JSON (JavaScript Object Notation) est une sérialisation textuelle des types de données élémentaires gérés par le langage JavaScript, dont la liste exhaustive est : string, number, array, object, boolean et null. Chacun de ces types constitue un document JSON en lui-même (et bien sûr on peut les imbriquer dans les tableaux et objets).
Un document JSON, qu'il soit élémentaire ou complexe, ne contient qu'une seule donnée racine. Pour manipuler plusieurs données, il faut plusieurs documents JSON. Contrairement au YAML, le format ne prévoit pas nativement la provision de plusieurs documents dans un même flux, séparés par un marqueur standard.
Diverses propositions existent [2]. Le JSONL (pour JSON Lines), appelé parfois ND-JSON (Newline-delimited JSON), prévoit simplement que chaque document tienne sur sa propre ligne (ce qui empêche donc le Pretty Print). Le Record-Separator Delimited JSON autorise l’indentation, mais utilise un caractère de contrôle (ASCII 0x1E) entre deux documents.
Le programme jq adopte une approche selon laquelle le Pretty Print est permis, et un retour à la ligne après un document annonce le document suivant (voir plus loin le chapitre Juxtaposition). Par exemple la séquence :
contient 4 documents JSON disjoints, dans un même flux.
C'est utile par exemple pour traiter des journaux Logstash où chaque message est émis au format JSON.
Dans cet autre exemple (ne vous laissez pas intimider par la syntaxe), nous appliquons une multiplication par deux à chaque élément d’un tableau (avec le flag -c pour une sortie compacte, sans formatage) :
La fonction map, qu’on retrouve dans de nombreux langages, applique une fonction à chaque élément d’un énumérable. La particularité de jq est que l'élément courant de l’itération est anonyme (un simple point .).
Ce paradigme, la programmation tacite, est un principe général dans le langage jq.
3. Tacit Programming
La programmation tacite [3] est un style dans lequel une fonction se manipule sans nommer le paramètre.
Dans un énoncé mathématique par exemple, on pourra parler d’une fonction f, tout court, et ne mentionner un paramètre f(x) que lorsqu'il s'agit d'expliciter sa formule. Ainsi, pour exprimer la dérivée d'une fonction composée, les relations de la figure 1 sont équivalentes.
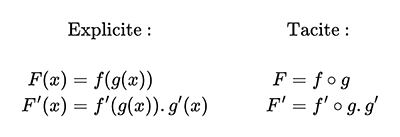
En JavaScript par exemple, map prend une fonction qui accepte en argument l'élément courant de l'énumérable en cours de traitement.
Concernant jq, nous ne donnons pas de nom au paramètre d'itération. On y fait référence par un simple point. S'il s'agit d'un objet, ses propriétés sont accessibles directement après le point (par exemple .prop).
On ne fournit plus une fonction anonyme ayant un paramètre nommé, mais directement le corps de la fonction qui agit tacitement sur l'élément en cours. La même opération s'écrit alors :
La programmation tacite permet de composer les fonctions de façon très élégante. Par exemple, avec la fonction pré-câblée add qui calcule la somme des nombres d’un tableau, et length qui en donne la longueur, on peut composer comme ceci : add / length, ce qui donne tout simplement la moyenne sans aucun besoin d’introduire un paramètre nommé d’itération.
L’entrée (ici le tableau) est tacitement aiguillée vers chaque fonction impliquée dans la composée.
Mentionnons à cette occasion que dans jq l’additivité s’étend à presque tous les types.
4. Contexte, tubes, itérations
L’élément courant sur lequel agit une opération est appelé « contexte » (NB : le manuel [4] utilise les termes current input ou call site, mais plus fréquemment le simple symbole « . »). Il peut s’agir de n’importe quel type d’élément pris en charge par JSON : un objet, un tableau, un nombre, etc.
On peut faire référence plusieurs fois au contexte dans la même formule (voir l’exemple .a+.b plus haut, où on utilise deux propriétés de l'objet-contexte).
Ainsi, s’il s’agit d’un nombre ou d’une chaîne, la formule .+. est équivalente à .*2, et retourne respectivement le double du nombre ou la chaîne écrite deux fois accolées.
La construction d’un traitement jq se fait par étages, chacun utilisant en entrée la résultante de l’étage inférieur. Ceci rappelle bien sûr le chaînage de commandes Linux, et c’est sans surprise le caractère | qui sépare les étages. Mais le concept est fondamentalement différent : l’action du tube | est de remplacer le contexte, autrement dit la donnée courante qui est tacitement représentée par . dans l’étage suivant. Certains opérateurs déclenchent une itération, ou plus précisément ils génèrent à leur sortie une suite de valeurs. Par exemple, l'opérateur .[ ] appliqué à un contexte de type array, a pour effet de provoquer la répétition de l'étage supérieur en lui donnant en entrée tour à tour chaque élément du tableau, qui devient le contexte . dans l'étage aval à chaque itération de cette boucle.
Considérons par exemple la donnée constituée par un tableau de nombres [10,23,14,…,173]. Nous allons construire un échafaudage (parmi différentes approches possibles) permettant de calculer la somme des valeurs paires supérieures à 50. On commencera par filtrer le tableau pour ne retenir que les valeurs dont le modulo 2 vaut 0, puis on enverra le tableau résultant à travers la fonction add. Le filtrage peut se faire en associant (map) chaque item à lui-même, ou à rien (la valeur spéciale empty, à ne pas confondre avec null) au moyen de la fonction select.
Si le prédicat du select est satisfait, le contexte est émis tel quel ; sinon, il est absorbé et rien n’est émis. La fonction map a produit un tableau dans lequel les valeurs impaires du tableau d’origine n’ont pas été retenues.
5. Filtres et générateurs
Nous venons d'aborder le concept du filtre, qui est l’une des deux notions essentielles de jq, avec le générateur. Expliquons-les de plus près.
5.1 Filtres
Un filtre est en fait une fonction qui agit sur une entrée et produit un résultat (potentiellement vide) en sortie. Si l'entrée est multiple, le filtre s'exécute sur chaque entrée, et fournit une suite de documents en sortie.
Le filtre .[i], où i est un nombre, s'applique à une entrée de type array, et fournit l'élément à la position i (0-based, comme ja JavaScript). La documentation précise toutes les subtilités sur les indices de tableau pour attraper le dernier élément .[-1], ou sélectionner une tranche .[4:7] (pas comme en JavaScript !).
Si l'entrée est un objet {"cle":"valeur"}, le filtre .cle fournit en sortie la "valeur" de cette propriété (guillemets compris, car il s’agit d’une donnée de type string).
On peut aussi utiliser comme en JavaScript la même notation d’indirection que pour les tableaux, mais avec le nom de la clé entre guillemets. C’est d’ailleurs nécessaire si son nom a évolué, comme ceci :
On peut enchaîner les indirections, pour accéder directement à une propriété imbriquée. Par exemple, considérons la réponse de docker container inspect :
Sur ces données, le script jq suivant :
répond "172.19.0.21", et c'est exactement équivalent au chaînage :
puisque le pipe restreint le contexte pour l'étage suivant à la valeur d'une certaine clé du contexte précédent.
5.2 Générateurs de documents
Le générateur quant à lui est un opérateur qui produit de nouveaux documents (zéro ou plus), à partir du contexte (ou à partir de rien).
5.2.1 Dissociation et construction de tableaux et objets
Le générateur .[ ] (sans indice, sinon il s'agirait d'un filtre) est un opérateur qui éclate le contexte-tableau en une série de ses éléments. Si c'est le dernier étage du pipeline, la sortie de la commande fournira autant de lignes (en fait, autant de documents) que d'éléments du tableau. Si ce générateur est tubé dans un autre étage, celui-ci exécutera plusieurs itérations.
L’opération contraire, produire un tableau à partir d’une suite d’éléments dissociés, se note simplement : [ elt1,elt2,elt3 ] (attention : sans point avant le crochet ouvert).
À l’instar de la construction de tableau, la syntaxe courante du JavaScript pour construire un objet (i.e. un dictionnaire clés : valeurs) est reprise dans jq. Il s’agit de placer une liste de propriétés entre une paire d’accolades { }. Tout le contexte courant est disponible lors de la création, ce qui permet d’effectuer des transformations de façon très expressive.
Par exemple, si l’entrée est un tableau, dont les deux premiers éléments sont des nombres, et le troisième est un objet aux propriétés x et y, comme ceci :
et que nous souhaitons transformer ce flux en cet objet JSON :
nous pouvons rédiger ce programme jq :
Autre façon de l’écrire, dans laquelle pour calculer la somme x+y du troisième item du tableau, nous restreignons localement le contexte :
Mais étudions un exemple plus concret. La commande :
renvoie un tableau JSON dont chaque élément représente une image, sous cette forme :
Nous nous proposons d'obtenir une liste de noms d'images accompagnés de la taille et du nombre de layers, par taille décroissante. Pour le nom d'image, nous retiendrons la première valeur du tableau de tags associés à l'image.
Nous allons traiter en bloc toutes les descriptions des images locales. Docker peut nous les fournir rassemblées dans un seul tableau JSON via cette commande :
Créons le script jq dans un fichier docker-img-size.jq comme ceci :
Dans ce script, nous faisons passer tout le tableau de la commande docker image inspect à travers la map pour obtenir un autre tableau, dans lequel chaque élément est construit comme un objet à trois propriétés. La clé name reprend simplement la première chaîne de la liste RepoTags du contexte de l’itération. La propriété layers compte la longueur du tableau imbriqué (i.e. on fait passer ce tableau à travers la fonction length).
Enfin, le résultat de cette map est passé dans l'opérateur sort_by qui trie un tableau par un prédicat donné : ici, pour obtenir un ordre décroissant, l'opposé de la size (notez le s minuscule, de la propriété de notre propre objet après transformation, pas celle du contexte amont).
Autres formalismes de requêtage
Il est sans doute possible d'arriver aux résultats de ces exemples Docker en utilisant le formalisme Go Templates [5], que la commande prend en charge avec l'argument --format. À titre personnel, je n'apprécie pas ce format pour manipuler du JSON, car sa syntaxe est éloignée du JavaScript. Chez AWS, les outils CLI supportent aussi une méthode de formatage via l'argument --query [6] à l'aide de la notation JMESPath [7]. Dans un cas comme dans l'autre, ces options me semblent moins élégantes que jq, et beaucoup plus limitées.
5.2.2 Séquence
Certains générateurs n'utilisent pas le contexte, mais génèrent plutôt des valeurs en fonction d'un argument. Notamment l'opérateur range, qui produit une suite de nombres (pas un tableau !), indépendamment de toute valeur d'entrée.
Par exemple :
Je profite de cette occasion pour présenter le flag --null-input (ou -n) qui spécifie qu'il n'y a pas d'entrée à lire. Il sert surtout à utiliser jq comme calculateur, ou pour produire des documents à partir de variables externes (voir 7.1 Arguments valorisés).
Par exemple, si l'on est perdu dans un terminal et qu'on souhaite rapidement connaître la somme des 10,000 premiers entiers au cube (1³ + 2³ + 3³ etc.), on peut exécuter (je la time pour le plaisir) :
La fonction pow accepte deux paramètres : dans jq, on les sépare par un point-virgule ; car la virgule a une autre signification, comme nous le verrons juste après. Vous devriez vous sentir déjà familier avec cette formule, dans laquelle on enveloppe la suite de documents du range (après transformation de chacun) dans un tableau, sur lequel on applique la réduction pré-câblée add.
La fonction range existe aussi dans une version à deux paramètres, pour fournir le début et la fin, exclue, d'une séquence d’entiers. On demande ici l’affichage compact (-c) et l’on constate que les documents disjoints sont alors séparés par une virgule.
5.2.3 Juxtaposition
La virgule est donc omniprésente en JSON : entre deux propriétés d'un objet, entre deux éléments d'un tableau et, comme nous venons de le voir, entre deux documents JSON juxtaposés, c'est-à-dire assemblés comme un tuple de documents, qui constituent autant d'entrées pour l'étage suivant.
Par exemple, considérons le filtre ' . * 2 ' auquel on fournit l'entrée ' 5, 6 ' :
L'outil voit bien les deux documents que sont le nombre 5 et le nombre 6 : il a calculé le filtre pour chacun, et fourni deux réponses disjointes, comme si l'on avait exécuté séparément la commande sur une entrée à la fois.
L'opérateur virgule est donc un générateur qui sert à construire une suite. On ne peut qu’être séduit par l'élégance et la cohérence de la chose, car c’est bien cette même virgule qui apparaît dans l'opérateur [ ... ] pour construire un tableau ad hoc, car alors la syntaxe est : [5 , 6], qui se trouve être précisément celle du JavaScript ! Ce n'est bien sûr pas un hasard.
En outre, la juxtaposition que permet la virgule ne se réduit pas aux types élémentaires comme les nombres, mais est valable pour n'importe quel document.
Ainsi, l'entrée suivante :
est valide, et fournit à jq deux objets JSON. Cette notation complète la capacité du programme à traiter des documents séparés par un newline, et permet donc d'alimenter des entrées sur une même ligne, séparées par des virgules.
En conclusion de ce grand chapitre, il me semble important de souligner que les générateurs ne produisent pas d’emblée leurs éléments. Plutôt, ils sont émis un par un, et fournis chacun comme entrée à l'étage suivant. Ce comportement est similaire à celui des générateurs des langages de programmation (souvent introduits par le mot-clé yield). Le bloc aval est donc exécuté de façon multiple, séparément, pour chaque élément exprimé par le générateur. Si un générateur est la dernière commande d’un programme, alors jq émettra des sorties indépendantes à mesure que le générateur produit ses données.
Ainsi, dans le programme détaillé en figure 2 (et qui n’a qu’un intérêt didactique ici), est illustrée la séquence d’exécution, qui met en œuvre une sorte de pile d'appel, que la documentation appelle backtracking.
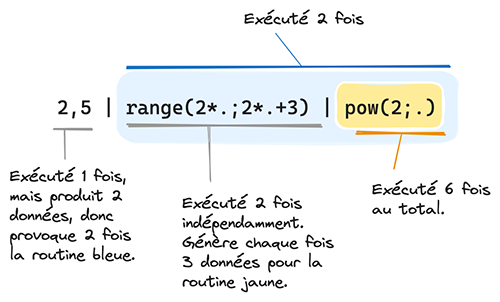
« 2, 5 » | « range(2*.; 2*.+3) » | « pow(2; .) » | Sortie | |
2 | range(2*2; 2*2+3) | 4 | pow(2; 4) | 16 |
5 | pow(2; 5) | 32 | ||
6 | pow(2; 6) | 64 | ||
5 | range(2*5; 2*5+3) | 10 | pow(2; 10) | 1024 |
11 | pow(2; 11) | 2048 | ||
12 | pow(2; 12) | 4096 | ||
6. Affectation et manipulation d’objets
Nous avons évoqué le générateur { } pour créer un objet. Parfois nous ne le créons pas de toutes pièces, mais souhaitons transformer certaines propriétés d’un objet existant.
Le JavaScript offre la notation ... pour reprendre le contenu d’un objet et surcharger certaines clés, comme ceci :
Ce code construit obj2 en recopiant toutes les propriétés de obj1, mais en remplaçant la valeur de b et en ajoutant un champ d.
En jq, si l’objet obj1 ci-dessus se trouve être le contexte, nous pouvons produire la sortie obj2 en utilisant l’opérateur = sur les champs b et d, comme ceci :
Ce programme réplique l’objet initial deux étapes. Tout d’abord, par l’affectation du champ b, nous nous retrouvons avec un contexte calqué sur le précédent, mais avec la nouvelle valeur pour b. Cette copie intermédiaire est tubée dans une opération similaire sur le champ d, qui n’existe pas encore et que l’affectation ajoute.
Notons que jq travaille en interne avec des données immuables et un système de pointeurs au niveau des propriétés. Le programme n'effectue pas de recopies inutiles, ce qui garantit de bonnes performances.
L’affectation se décline intuitivement en incrémentation += et multiplication *=, et l’on peut évidemment référencer d’autres éléments du contexte, comme ceci :
Ceci s’avère commode notamment avec les chaînes et les tableaux, sur lesquels jq étend le signe + pour signifier la concaténation. Étant donnée l’entrée suivante :
voici comment ajouter la nouvelle couleur à la liste des couleurs. L’opérateur del projette une réplique du contexte, privée de la clé spécifiée :
Attention, notez que la concaténation de tableaux opère sur... des tableaux ! (contrairement au push du JavaScript, auquel on passe les éléments à ajouter comme autant d'arguments individuels). Nous devons donc fournir le tableau [.nouvelle] comme opérande droit.
De plus, il est possible de faire une affectation à n’importe quel niveau imbriqué :
Enfin, il existe un opérateur supplémentaire pour la modification : le tube-égal |= qui restreint le contexte de l’opérande droit à la valeur de la propriété en cours de modification. Comparez par exemple ces deux formes, équivalentes :
et
7. Utilisation avancée
Le langage comporte entre autres le support du if...else, les boucles while, et la définition de fonctions personnalisées. L’objet de cet article n’est pas de couvrir toutes les capacités, mais nous allons parler des variables, et terminerons par un exercice de mise en pratique.
7.1 Arguments valorisés
Les documents entrants ne contiennent pas toujours toute l’information nécessaire pour produire la sortie. Par exemple, certaines données peuvent provenir d’arguments de la ligne de commandes, ou de variables d’environnement.
L’outil jq offre l'objet $ENV qui représente l’environnement d’exécution. On s’en sert comme n’importe quel autre objet dans les formules. De même, on peut lancer la commande avec des options --arg Name1 Value1, répétées si nécessaire, pour fournir des valeurs dans un objet $ARGS.named.
7.2 Variables
Dans certains cas, le contexte d’un étage donné ne suffit pas à lui seul pour la réalisation de son calcul. Il arrive que des données provenant du contexte d’un étage en amont, soient requises.
jq permet l’utilisation de variables, repérées par un $, afin de capturer des valeurs à n’importe quel niveau, et les laisser disponibles, en supplément du contexte, pour tous les étages en aval.
La syntaxe générale est :
À l’instar de l’opérateur d’assignation, lorsqu’un étage positionne une variable, il transmet quand même son propre contexte intact à l’étage suivant.
Cette particularité est notamment très utile pour réaliser des boucles dont on compte le numéro d’itération.
Voyez plutôt :
Le premier étage, où l’on déclare la variable $i, transfère son contexte (ici l’entrée standard) à l’étage suivant. Celui-ci positionne une nouvelle propriété au sein de l’objet-contexte, qui continue de passer en cascade à l’étage suivant, ainsi que toutes les variables déjà déclarées.
Une variable peut contenir tous les types de données prises en charge par JSON, simples ou complexes, et même des listes de documents.
7.3 Résultat tabulaire
L'outil dispose de quelques filtres de sortie, pour transformer le format JSON en autre chose. Ils sont repérés par le préfixe @. Nous trouvons par exemple l'opérateur de sérialisation @json qui produit la même chose que le JSON.stringify du JavaScript ; ou encore le format @csv qui transforme des séries de tableaux représentant les lignes.
Nous allons ici illustrer le format @tsv pour un affichage tabulaire. Pour cet exercice, nous utiliserons la fonction builtins qui produit un tableau de tous les noms de fonctions pré-câblées, avec leur arité. Nous voulons obtenir un résultat qui ne soit pas une simple liste, mais des colonnes tabulées à sortir dans la console. Le nombre de colonnes sera paramétrique. Les items seront triés, mais affichés en colonnes, comme sur la figure 3.
Comme dans cet exemple, où nous indiquons les indices des valeurs :
Comme nous devons fabriquer une liste de lignes, nous allons transformer le array unidirectionnel en une liste de tableaux JSON : ici 4 lignes (car 10 valeurs sur 3 colonnes). Nous entrelaçons les indices initiaux comme ci-dessus : la première ligne [0, 4, 8], etc. Dans jq, les indices inexistants dans un tableau répondent gracieusement la valeur null, que @tsv affiche comme une chaîne vide, donc nous n’avons pas de traitement spécial à faire pour les lignes du bas, dont la colonne de droite comporte des trous.
Le nombre de lignes est égal à la division entière de la longueur totale par le nombre de colonnes désirées, arrondi à l'entier supérieur. Nous produisons des lignes constituées chacune par un tableau dont les éléments reprennent ceux de la liste initiale, aux indices donnés par la formule (zero-based) :
Nous invoquons notre script avec le nombre de colonnes en argument, et utilisons l'outil GNU column -t qui optimise l'affichage en produisant des colonnes de largeur égale, pour obtenir le résultat en figure 3.
L’utilisation du flag -r (--raw-output) fait que les données de type string sont affichées brutes, sans séquences d'échappement JSON pour les caractères spéciaux, et sans les guillemets (pratique pour capturer le texte ou comme ici le passer à un autre programme).
Conclusion
Le projet jq a rencontré un vif succès ; la commande est préinstallée dans pratiquement toutes les plateformes de CI/CD (GitHub Actions, CircleCI, les Web Shell AWS et GCP, etc.).
Il a inspiré son équivalent yq [8] pour le monde YAML, et il existe même un projet jc [9] qui convertit à la volée la sortie de très nombreux outils GNU, chacun dans son schéma JSON adapté, ce qui ouvre d’innombrables horizons d’extractions et filtrages par jq :
De fait, la manipulation de JSON comme citoyen de première classe du système devient vite indispensable une fois l’habitude prise.
Références
[1] Site du projet jq : https://github.com/jqlang/jq
[2] Les propositions JSON Lines : https://en.wikipedia.org/wiki/JSON_streaming
[3] Tacit Programming sur Wikipédia : https://en.wikipedia.org/wiki/Tacit_programming
[4] Le manuel complet jq : https://jqlang.github.io/jq/manual/v1.7/
[5] Les Go Templates pour le formatage : https://pkg.go.dev/text/template
[6] La spécification de filtrage pour les sorties AWS CLI :
https://docs.aws.amazon.com/cli/latest/userguide/cli-usage-filter.html
[7] La syntaxe JMESPath pour requêter des documents JSON : https://jmespath.org
[8] Le projet YQ pour le traitement du YAML : https://github.com/mikefarah/yq
[9] Le projet JC pour JSONifier Linux : https://github.com/kellyjonbrazil/jc



