

Les mesures de confinement prises par le gouvernement mi-mars 2020 pour contrer la propagation du Covid-19 ont poussé les entreprises et administrations de toutes tailles à promouvoir le télétravail. Cet article présente le retour d’expérience d’une partie de l’équipe EDF en charge des « accès distants sécurisés » pendant cette période.
Introduction
À l’instar de nombreuses organisations, l’usage du télétravail à EDF est fondé sur des accès VPN et avait, avant la crise sanitaire, comme objectif principal de faciliter les situations de mobilité, le nomadisme des collaborateurs induit par l’évolution des contrats de travail et des partenaires de l’entreprise. Le travail en présentiel était toutefois la norme.
Ce paradigme a brutalement changé au printemps 2020, avec la nécessité de garantir, dans un délai contraint et à un niveau de sécurité conforme aux attendus de la politique groupe, un accès à distance à un très grand nombre d’utilisateurs simultanés pour simplement assurer le fonctionnement de processus de l’entreprise. La capacité de réagir à cette situation, entrevue à un niveau bien moindre lors des grèves de décembre 2019 en région parisienne, n’était plus en phase ni avec les infrastructures disponibles ni avec l’organisation en charge de leur gestion.
Dans ce retour d’expérience (REX) qui se concentre sur la partie VPN, nous vous présenterons l’évolution majeure mise en œuvre pour la mise en place d’une organisation robuste capable de maîtriser la montée en charge progressive des passerelles dans des situations exceptionnelles, puis les éléments qui ont contribué au succès de la solution et aux prises de décisions rapides, mais également certaines activités courantes réalisées durant la crise. L’ensemble a permis d’assurer un accès serein et sécurisé aux ressources de l’entreprise dans ce contexte très contraignant.
1. Covid-19 : de l’importance de l’anticipation
1.1 Contexte de ce REX
Quelques semaines avant le confinement, à la suite de réflexions liées au contexte international du Covid-19 et à l’expérience récente des grèves de décembre 2019, la direction des systèmes d’information du groupe a décidé l’augmentation des capacités d’accès aux ressources de l’entreprise depuis l’extérieur. Cette décision s’est révélée pertinente, car il était bien difficile, à ce moment-là, d’imaginer le déclenchement d’un confinement total de la France, qui s’est produit dans le cadre du plan pandémie quelques semaines plus tard.
Dans le contexte de l’entreprise, ces accès reposent sur une solution de VPN individuel supportant des profils configurés par type de populations utilisatrices : agents EDF, prestataires sous contrat ou partenaires. À chaque profil est associée une politique de contrôle d’accès.
Sur le plan des accès, une particularité notable du dispositif est le choix du mode full tunnel chez EDF (par opposition au split tunneling) imposant à la globalité des flux issus du poste de travail connecté en VPN d’être encapsulés dans le tunnel établi. Toutefois il est quand même intéressant de rappeler que le choix du mode full tunnel a un fort impact sur les solutions de type visioconférence majoritairement utilisées dans les entreprises de toute taille dans le sens où le fait de diriger tous les flux dans le tunnel détériore la qualité des échanges surtout en période de forte montée en charge à cause de la latence induite par le VPN. Et on contraint également les utilisateurs à ne pas pouvoir utiliser des solutions distantes classiques telle qu’une imprimante réseau par exemple. Cela permet d’éviter que le poste puisse servir de pont entre le réseau local (par extension à Internet) et le réseau d’entreprise permettant ainsi à des attaquants potentiels de contourner les mécanismes de sécurité périmétriques du système d’information.
Pour préciser la demande, augmenter les capacités d’accès à distance revenait à assurer un service stable capable d’accueillir 50 000 utilisateurs de manière simultanée (sur plus de 100 000 utilisateurs ayant un profil VPN). Ces derniers ont parfois besoin d’accéder à des applications très consommatrices de bande passante telles que des applications utilisant des flux voix (téléconseillers), voire vidéos, ou des applications de type CAO. L’enjeu est de taille pour la direction IT du groupe qui doit permettre aux directions métiers d’assurer la continuité de leurs activités pendant la crise. À titre de comparaison, le dernier record avant cette crise sanitaire a eu lieu lors de la grève SNCF du 5 décembre 2019 avec un pic de connexions enregistrées à hauteur de 18 500 utilisateurs.
1.2 L’anticipation
Un projet de refonte des accès distants avait été initié en janvier 2018 en réponse à l’évolution des usages en interne et à un accord qui visait la démocratisation du télétravail. Ce dernier était jusque-là très occasionnel, seulement ouvert aux cadres sur la base d’une vingtaine de jours par année. Dans le cadre de ce projet, un état des lieux avait permis de faire ressortir les irritants et les risques qui pesaient sur la disponibilité de l’infrastructure de l’époque :
- La nécessité, pour les directions métiers, de disposer de connaissances techniques sur le SI lors des demandes d’accès VPN rendait cette tâche fastidieuse, voire faisait abandonner certains demandeurs. Un travail colossal a alors été engagé pour repenser les accès et le modèle d’habilitation (profils) afin de les rendre plus intelligibles.
- L’augmentation importante des conventions de télétravail par les salariés de la direction IT du groupe a induit un redimensionnement nécessaire de l’infrastructure d’accès pour supporter la charge.
- Le nombre de règles de filtrage réseaux liées au VPN était en augmentation constante de 20 % par an à cause de la multiplicité des profils, du nombre d’utilisateurs et de la quantité d’applications à accéder à distance, présentant un risque à moyen terme sur le maintien en condition de sécurité, d’exploitabilité et d’auditabilité de la solution.
L’existence de ce projet et la disponibilité de ces éléments sortants sont à la fois le fruit d’un heureux hasard et le reflet d’une réelle stratégie de long terme portée par l’entreprise sur le sujet du télétravail.
1.3 Les facteurs de succès
Tous ces travaux réalisés, entre 2018 et 2019, ont contribué à la bonne préparation de l’infrastructure et des équipes face à la situation inédite à laquelle toutes les entreprises allaient devoir faire face. À l’instant T, il nous a été possible de savoir :
- comment prioriser le traitement des profils VPN les plus critiques pour l’entreprise ;
- quelle était l’importance de la communication vers les utilisateurs (salariés ou partenaires) qui se connectent par l’intermédiaire de nos accès distants pour accéder à leurs ressources ;
- s’il fallait dédier des équipements à des usages qui nécessitent une consommation de bande passante importante (téléconseiller) et qui représentent un risque pour la disponibilité de l’infrastructure ;
- quelle visibilité supplémentaire nous pouvions apporter aux équipes du SOC afin d’améliorer la surveillance et le renforcement de la sécurité.
Il faut également noter le rôle clé lié de la culture du télétravail dans l’entreprise. Comme énoncé au paragraphe 1.2, il était déjà possible de faire du télétravail de manière occasionnelle et par conséquent avoir recours à des outils collaboratifs pour maintenir tous les besoins de communication nécessaires au bon fonctionnement d’une organisation (réunion d’équipes, réunions de projet, etc.). La préexistence et l’acceptation de ce mode de travail et des outils de communication, collaboration ou encore de management sont autant de dispositifs à ne pas déployer en urgence. Le VPN n’est en effet pas le seul outil nécessaire au travail à distance et les équipes doivent déjà être acculturées à ces modes de fonctionnement.
En plus de l’anticipation, la capacité à s’appuyer sur des compétences présentes qui répondent au besoin constaté, indépendamment de l’existence de la solution en amont, est déterminante. Il faut savoir faire confiance à ses équipes dans ce genre de situation.
Le contexte particulier du groupe EDF et son historique permettent à celui-ci d’être préparé à des crises d’envergure. Les processus dédiés sont en place et l’organisation rapidement mobilisable. Un aspect similaire qui nous semble important est l’implication bienveillante du management et de la direction du groupe auprès des équipes. La capacité à faire comprendre l’importance de l’enjeu, sans pour autant « mettre la pression » tout en limitant les perturbations internes liées à certains aspects de la vie d’un grand groupe qui peuvent être pénalisantes dans ce genre de situation.
Il nous semble important de souligner cette capacité à sortir des processus normaux de l’entreprise qui est un réel facteur de succès et permet une réaction rapide et efficace des équipes. En contrepartie, ce mode de fonctionnement nécessite une reprise a posteriori de ce qui a été fait en temps de crise, dans un contexte spécifique et urgent, en vue de réintégrer le système mis en œuvre dans les standards du système d’information.
2. La gestion de crise
2.1 Comment mettre en place du télétravail à grande échelle
Il a fallu très vite désigner un coordinateur global ainsi que ses homologues stratégiques et techniques pour débuter la réflexion. Pour ne pas être limité par les processus habituels internes, parfois complexes comme dans beaucoup de grands groupes, le ton était déjà donné par la direction : « à situation exceptionnelle, mesures exceptionnelles ! ».
Après une étude préalable fondée sur tous les entrants (décrits dans le paragraphe 1.2), l’équipe stratégique et technique a présenté le plan d’actions nécessaires aux objectifs donnés en présence des experts, pilotes opérationnels, chefs de projets et exploitants de solutions. La présence de tous les intervenants des briques d’infrastructures transverses concernées par les accès distants a permis de mesurer les impacts, affiner le plan d’actions et de constituer la task force destinée à piloter les opérations et la production à venir. Après validation en séance, les travaux ont débuté dans la foulée.
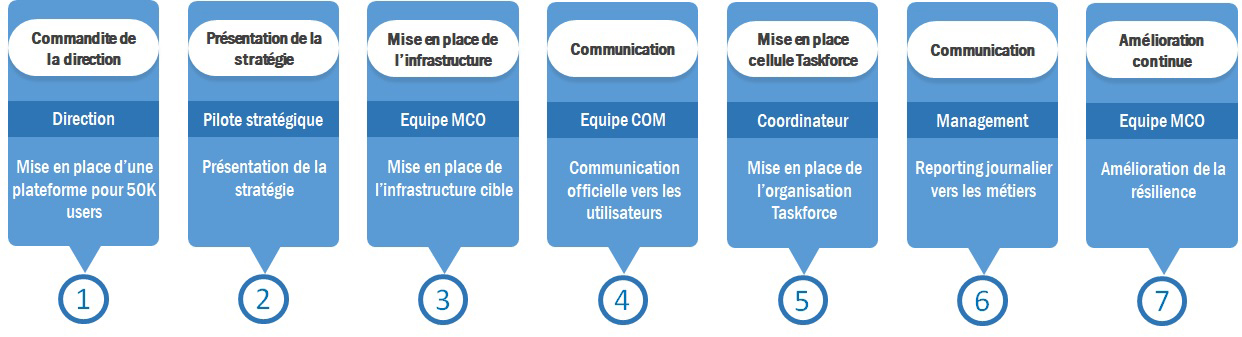
L’infrastructure était opérationnelle deux jours avant le confinement annoncé par le gouvernement. Vous l’aurez compris, nous sommes bien loin des circuits habituels de validation. La mise à profit de l’intelligence collective et l’implication forte de la direction ont permis une mise en place efficace.
2.2 Quels moyens et quelle organisation pour le projet ?
L’essentiel a été fait : l’infrastructure est prête et opérationnelle. Avec l’expérience acquise grâce au projet de refonte de l’infrastructure VPN et à quelques optimisations, nous avons réussi à aller au-delà de l’objectif donné (50 000 utilisateurs) et nous avons monté une plateforme capable d’accueillir 70 000 utilisateurs simultanés. À ce stade, cela ne suffisait pas, il devenait nécessaire de surveiller la montée en charge du système et d’agir en cas d’alerte. Comme rappelé précédemment, une cellule task force a été montée dans le cadre suivant :
- un point audio régulier chaque heure afin de surveiller l’état de santé des infrastructures de la chaîne de connexion en dehors de la supervision classique conservée toutefois en l’état ;
- un reporting quotidien du nombre de connexions simultanées aux différentes entités du groupe, contenant des informations importantes pour les métiers, mais aussi pour la direction IT et les prises de décision nécessaires (comme la priorisation des accès essentiels) en cas de soucis sur l’infrastructure ;
- une communication massive sur les bonnes pratiques d’accès à distance (sensibilisation) ;
- une cellule d’étude et d’expertise pour améliorer la résilience de l’infrastructure ;
- une cellule d’étude d’expertise spécifique dans le but de proposer un plan de priorisation des accès VPN en cas de gros soucis sur l’infrastructure ;
- l’interdiction de toute modification en dehors des besoins de sécurité ou d’un éventuel problème grave affectant le système d’information du groupe (les dérogations pouvant être autorisées sous réserve d’un accord de la direction).
2.3 Les similarités avec la réponse à incident
Comme on commence à le voir, cette crise du Covid-19 ressemble plus à un incident de sécurité qu’à un projet informatique « traditionnel » :
- le Covid-19 est un perturbateur externe et non maîtrisé par l’organisation ;
- il est nécessaire de fournir (et documenter) une réponse dans un délai court ;
- on cherche à minimiser l’impact sur le métier et les dégâts pour le SI ;
- il faut gérer la communication interne et externe ;
- on fonctionne en mode état des lieux puis plan d’action rapide, ce qui rappelle fortement les cas de réponse à incident : audit, investigations puis remédiation ;
- il est important de faire un retour d’expérience.
On retrouve aussi l’utilisation d’une task force prioritaire au lieu des organisations projets traditionnelles. Celle-ci intègre une grande partie des intervenants courants en réponse à incident, à savoir : les acteurs réglementaires (conformité/juridique), l’exploitation informatique et réseaux, le management, les ressources humaines et les experts de chaque sujet (support niveau 3, SOC, CERT, CSIRT, etc.).
Finalement, on s’aperçoit que les modes de fonctionnement utilisés pour gérer la crise Covid-19 ressemblent par bien des aspects à une réponse à incident en bonne et due forme.
3. Reporting, alerting et pilotage opérationnel et de sécurité
3.1 Les challenges pour le SIEM
Si rendre le service VPN était bien la priorité numéro une, de nombreux sujets annexes sont également concernés par ce changement rapide des usages et des infrastructures. Une des difficultés qu’il a fallu surmonter au SOC est l’augmentation massive du volume de logs en provenance des VPN. L’infrastructure a dû faire face à une multiplication par 3 du volume de ces logs en quelques jours.
Pour gérer cela, il a fallu déployer en urgence des collecteurs syslog supplémentaires dédiés aux passerelles VPN et répartir l’envoi des journaux vers ces derniers de manière à lisser la charge. De même, les capacités de stockage et de traitements dédiés à ces logs ont dû être augmentées. Le dernier point concerne la verbosité des logs, leur fréquence d’émission et certains contrôles qu’il a fallu ajuster pour adapter le SIEM à cette charge inhabituelle.
Ce que nous pouvons retenir c’est qu’il est indispensable d’avoir une infrastructure SIEM maîtrisée et capable d’évoluer rapidement, il faut en particulier disposer d’une couche de collecte syslog indépendante de l’outil retenu (QRadar, Splunk, ELK…), comme un ensemble de serveurs rsyslog positionnés stratégiquement dans le réseau. En s’affranchissant d’une couche propriétaire sur ces éléments, il est possible de gagner en agilité, y compris lors des renouvellements de marché de ces outils SIEM.
3.2 Mise en place d’une plateforme de supervision dédiée
Quelques jours avant le confinement, le management a demandé à avoir une capacité de reporting dédiée pour la solution. Le VPN bénéficiait déjà d’une supervision de sécurité au SOC, néanmoins la particularité de la crise et la variété des besoins exprimés hors du périmètre sécurité ont poussé le management à faire un appel à compétences pour renforcer les capacités de reporting et d’alerting sur l’infrastructure VPN.
Deux réponses ont été apportées, l’une à base de briques open source autour de MongoDB, l’autre avec le logiciel Splunk. C’est cette dernière que nous allons détailler ici, dans la mesure où il s’agit de celle mise en œuvre par vos serviteurs.
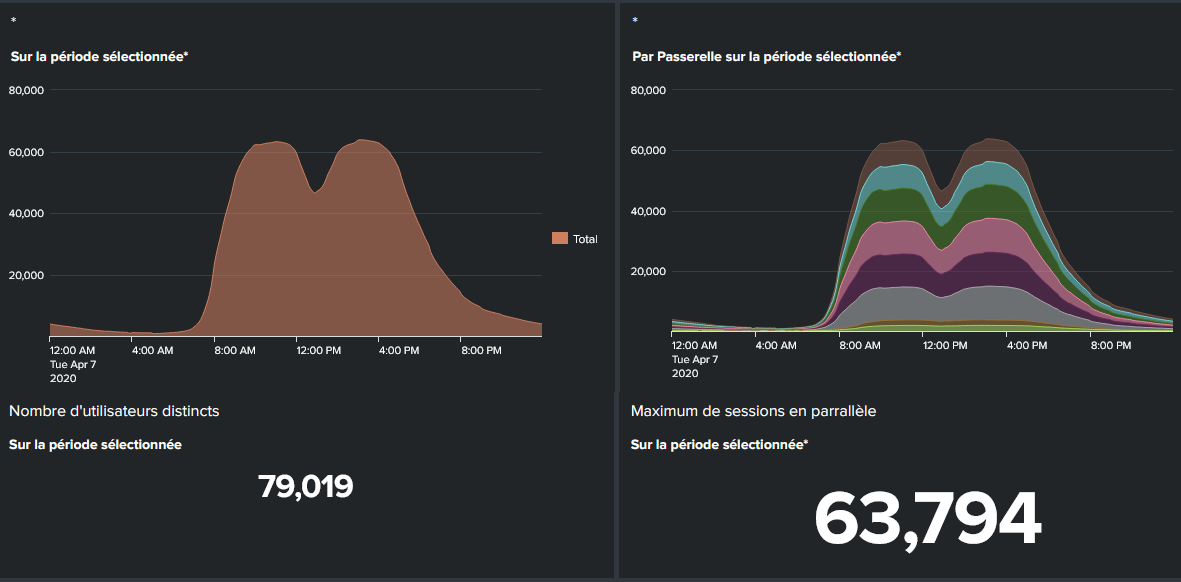
Nous ne reviendrons pas en détail sur les briques d’une infrastructure Splunk, celles-ci ayant été abordées à plusieurs reprises dans MISC [1] [2]. La plateforme a pu être déployée en moins de 48 heures (entre la décision et la mise en production avec réception des logs des passerelles VPN). Il est important de noter que dans ce cadre particulier cette action a pu se faire sans se soucier de l’urbanisation, des achats et du processus de déploiement habituel comme expliqué précédemment.
La solution a permis de suivre la montée en charge de l’infrastructure VPN modifiée et de répondre entre autres aux demandes suivantes de la task force du 16 mars jusqu’à aujourd’hui :
- fournir des informations de reporting consolidées et des rendus visuels facilement interprétables à la direction ;
- fournir des zooms détaillés pour certaines MOA ;
- faire un suivi en temps réel de l’activité sur les passerelles ;
- pouvoir identifier les anomalies de manière proactive ;
- compléter les capacités d’alerting existantes ;
- donner de l’agilité dans le traitement des demandes.
3.3 Alertes Land Speed Violation sur le VPN
Afin de préciser notre présentation, il nous semble intéressant de nous attarder sur une des alertes qui a été mise en place à l’aide de Splunk. Celle-ci est tirée de l’App Splunk Security Essentials [3] et utilise la géolocalisation IP pour calculer les positions GPS et le pays d’origine des IP sources des clients du VPN et ainsi lever une alerte si une distance trop importante est détectée sur un court laps de temps. À la fois simple à mettre en œuvre et avec un taux de faux positifs faible, elle a l’inconvénient de repérer les utilisateurs à l’étranger qui utilisent un accès internet local et une connexion 4G d’un opérateur français (en partage Wi-Fi sur le smartphone par exemple).
La version simple de cette recherche peut s’écrire simplement en SPL (Search Processing Language [4][5]) en recherchant les utilisateurs avec des IP en provenance de 2 pays dans une journée :
La version avancée de cette alerte permet de rechercher des sessions simultanées depuis 2 IP sources différentes et peut s’écrire ainsi en utilisant en particulier la fonction streamstats pour générer un compteur de session par utilisateur.
Évidemment d’autres alertes ont pu être mises en place avec cet outil et à la demande de la DSI ou des filières sécurité : inventaire des versions clients, adhérences entre les versions des clients VPN, des boîtiers pour l’exposition à certaines vulnérabilités, etc.
3.4 Quelques adhérences indirectes
Avant de conclure, nous voulions rappeler que beaucoup d’éléments d’un SI ne sont pas dépendants des infrastructures VPN en temps normal. Dans le contexte du confinement lié au Covid-19, de nombreuses questions sont apparues en lien avec :
- la mise à jour des postes : faut-il se connecter au serveur WSUS de l’entreprise au travers du VPN ? Faut-il exposer ces serveurs depuis l’extérieur ? Accepter de patcher directement depuis les serveurs de l’éditeur au risque de perdre la maîtrise du patch management et de créer des incidents sur certaines applications ?
- le maintien en condition de sécurité de l’antivirus et de l’ensemble des services d’infrastructure un tant soit peu consommateurs de bande passante ;
- l’application des correctifs de sécurité sur les passerelles VPN pendant la crise par rapport au risque associé d’une coupure de service : peut-on réutiliser d’anciennes passerelles avec une vulnérabilité connue si le risque est compensé par un autre moyen de protection ?
Toutes ces questions n’ont malheureusement pas de réponse absolue et dépendent du contexte, du niveau de préparation à la crise, des capacités de supervision ou de reporting que chaque entreprise aura dû trouver pendant cette période.
Conclusion
Au terme de ce retour d’expérience, il nous semblait important de mettre en évidence quelques éléments clés qui ont contribué au succès des opérations VPN et Covid-19 à EDF :
- un zeste de chance ;
- la capacité à ne pas suivre le livre de recettes habituel ;
- une brigade en mode task force transverse ;
- des chefs bienveillants ;
- quelques vieilles cartes à reproposer ;
- la mise en œuvre d’une stratégie de priorisation quand le coup de feu arrive.
Mais tout ne s’est malheureusement pas terminé le 11 mai 2020, le Covid-19 est toujours là. Si le spectre d’un reconfinement total ne semble plus à l’ordre du jour (au moment où nous écrivons ces lignes), il est clair que nous n’avons pas terminé de gérer les perturbations liées à cette crise sanitaire. Nous espérons donc que ce REX vous aura donné quelques pistes constructives de travaux afin de concevoir des moyens mobilisables lors des prochaines crises.
Remerciements
Nous souhaitons remercier particulièrement Stephen, Thomas, Frédéric, Sabine, Pascal et Marion pour leur aide dans la rédaction de cet article.
Références
[1] Détection d’attaques avec Splunk – MISC n° 89 – janvier 2017 – Tricaud Sébastien : https://connect.ed-diamond.com/MISC/MISC-089/Detection-d-attaques-avec-Splunk
[2] Prise en main du machine learning avec Splunk – MISC n°110 – juillet 2020 – Wassim BERRICHE, Françoise SAILHAN & Stefano SECCI : https://connect.ed-diamond.com/MISC/MISC-110/Prise-en-main-du-machine-learning-avec-Splunk
[3] Splunk Security Essentials : https://splunkbase.splunk.com/app/3435/
[4] Search Processing Language : https://www.splunk.com/fr_fr/resources/search-processing-language.html
[5] Security Ninjutsu Series, David Veuve : https://davidveuve.com/splunk.html



