

Le web scraping, c’est l’activité qui consiste à gratter (to scrap) du code HTML pour en extraire des données exploitables. Node.js se prête particulièrement bien à l’exercice, aussi je vous propose d’apprendre à gratter de la donnée avec ce formidable outil.
Le terme « scraping » en anglais désigne le grattage, le raclement. À ne pas confondre avec « scrapping » avec deux « p », qui désigne la mise au rebut, l’abandon. Je préfère préciser, car j’ai trouvé plusieurs fois cette confusion dans des forums. Certains auteurs préfèrent le terme de « harvesting » (récolte), mais c’est quand même assez rare.
Il existe de nombreuses manières de faire du web scraping. La plupart des langages de programmation permettent de se livrer à cette activité (Ruby, PHP, Python, etc.), mais il existe aussi des extensions pour navigateurs, qui offrent des mécanismes de scraping plus ou moins avancés. J’ai ouï-dire qu’il existe aussi des solutions commerciales (destinées aux non-développeurs), assez coûteuses.
Pour ma part, j’ai eu l’occasion de faire du web scraping en diverses occasions (j’y reviendrai), la plupart du temps en PHP. Mais récemment, je me suis demandé comment je m’y prendrais pour faire la même chose avec Node.js. L’article que vous êtes en train de lire est le fruit de cette réflexion.
Cet article ne nécessite pas d’avoir une forte expertise en JavaScript, mais pour en tirer profit, il est préférable que vous ayez une petite pratique de Node.js, et si possible quelques connaissances en matière de manipulation du DOM (j’essaierai de vous donner quelques rudiments sur ce point).
1. Le kézako du web scraping
1.1 Le web scraping, à quoi ça sert ?
Il faut savoir que le web scraping est une pratique courante dans les startups, où les personnes ayant un profil de type « growth hacker » (hacker de croissance) l’utilisent pour collecter des données sur les sites internet des partenaires et des concurrents, et cela pour diverses raisons.
Pour ma part, j’ai fait mes premières expériences de web scraping, il y a environ 13 ans. À l’époque j’étais missionné pour aider un distributeur de matériel de jardinage à sortir son catalogue produit des griffes d’un hébergeur peu aimable. Le distributeur voulait se débarrasser de cet hébergeur et confier la gestion d’un nouveau site web à ma société. Si l’hébergeur était disposé à fournir ses données à mon client, c’était dans un format inexploitable (genre format PDF). J’avais donc écrit un petit script PHP qui grattait l’ensemble des pages du site internet de référence, pour récolter les données propres au catalogue produit. J’avais besoin de récupérer le descriptif détaillé de chaque produit, les tarifs, et les photos. Je dois dire que j’avais adoré faire ça, je trouvais cette activité très fun (mais vous allez peut-être vous demander pourquoi).
En fait, gratter le contenu de pages HTML nécessite de faire un travail d’investigation plus ou moins poussé (c’est l’aspect que je préfère). Par exemple, dans le cas du grattage d’un catalogue produit, il faut comprendre comment est structuré le code HTML, quelles sont les balises présentes sur chaque page qui vont pouvoir servir de point d’ancrage, afin d’aller récupérer les données réellement utiles (c’est là où des connaissances en manipulation du DOM se révèlent précieuses). Il faut aussi réfléchir à la manière de parcourir le catalogue en ligne de manière à rater le moins de produits possible.
Faire du web scraping, c’est finalement une activité pas très éloignée de celle qui consiste à analyser une vieille base de données pour identifier les données qui doivent être extraites et réinjectées dans une nouvelle base (par exemple, pour le remplacement d’un logiciel). C’est une activité que j’ai aussi pratiquée souvent, et au-delà du pur exercice de style, l’intérêt c’est d’abord et avant tout d’épargner aux utilisateurs des saisies (ou ressaisies) de données longues, fastidieuses, et souvent sources d’erreur.
Avertissement
Attention, on ne peut pas gratter n’importe quelles données, et dans n’importe quel but. Il faut savoir faire preuve d’éthique, aussi bien d’un point de vue technique que juridique.
Tout d’abord, le point de vue technique : si vous avez besoin d’extraire des données des 200 pages d’un site web, vous ne balancez pas 200 requêtes HTTP à la seconde, vous étagez vos requêtes gentiment, par exemple par paquets de 10 toutes les 10 ou 20 secondes. Bref, vous calibrez intelligemment vos requêtes pour ne pas mettre en difficulté le serveur web de votre site internet cible (et accessoirement pour ne pas vous faire repérer).
Voyons maintenant le point de vue juridique : extraire le catalogue d’un concurrent pour le comparer avec son propre catalogue, c’est une chose qui est compréhensible. Mais extraire ce catalogue pour le réutiliser à l’identique dans sa propre boutique en ligne, c’est déjà beaucoup plus problématique. Je ne suis pas juriste, aussi je ne vais pas m’étendre là-dessus, mais je vous invite à lire la page Wikipédia consacrée au web scraping, car elle fournit quelques éléments de réflexion sur ce sujet [1].
J’espère que vous ne m’en voudrez pas si dans la suite de l’article, j’emploie le terme de « grattage » en remplacement de « scraping ».
Ah, mais au fait, il me faut une cible pour mes petites expériences. J’ai jeté mon dévolu sur la newsletter de l’éditeur américain Manning [2]. J’aime bien cet éditeur, il a d’excellents bouquins à son catalogue, notamment sur JavaScript et sur plein d’autres sujets. En tant que client de Manning, je reçois presque quotidiennement une newsletter contenant l’offre promotionnelle du jour, toujours accompagnée d’une petite anecdote historique (liée au monde de l’informatique), anecdote qui s’est produite le même jour, quelque part dans le passé. Vous l’aurez compris, ce sont ces anecdotes historiques que je vais utiliser pour cible.
Par exemple, la newsletter du 21 janvier 2020 évoque la machine analytique de Charles Babbage [3] (voir figure 1).

C’est parfait comme cible pour mes petites expériences. Il y a du texte à extraire, en l’occurrence un titre, une date, et un paragraphe explicatif... plus une image, c’est génial !
Pour le 21 janvier, l’URL [3] de la newsletter se termine par ceci : .../on-this-day-01-21/.
Si vous vous amusez à changer de date manuellement, vous découvrirez d’autres anecdotes historiques, toutes présentées dans le même moule, donc on peut s’attendre à ce que le code HTML soit structuré toujours de la même façon. C’est la configuration idéale pour faire du grattage de données à grande échelle (comme on pourrait le faire pour un catalogue produit).
Bon, on a le contexte, on a la cible, alors maintenant, on passe au code.
1.2 La trousse à outils du gratteur de pages
Je pars du principe que vous avez déjà installé Node.js sur votre machine. Mais si vous l’avez peu utilisé et que vous avez un trou de mémoire, je rappelle que l’initialisation d’un projet Node se fait via la commande suivante :
Pour faire du grattage de site web, on a besoin de plusieurs outils :
- Un outil permettant de lancer des requêtes HTTP ou HTTPS, selon le type de site ;
- Un outil permettant de manipuler le code HTML récupéré par les requêtes HTTP (ou HTTPS) de manière à en extraire la substantifique moelle ;
- Un outil permettant de stocker la substantifique moelle sur disque (en l’occurrence au format JSON pour les données textuelles, et bitmap pour les images).
Pour les points 1 et 3, Node.js a tout ce qu’il faut en natif, par contre pour le point 2, on aura besoin de compléter Node.js par l’ajout d’un package NPM (nous verrons ce point un peu plus loin).
1.2.1 Les requêtes HTTPS
Pour l’exécution de requêtes HTTPS, Node.js a tout ce qu’il faut en natif. Ce n’est pas la peine d’aller chercher des packages quelconques, comme j’ai pu le voir dans certains tutos. En l’occurrence, la newsletter de Manning est stockée sur un site web répondant au protocole HTTPS, donc je vais utiliser l’API native https de Node.js. La documentation officielle de Node.js n’est pas réputée pour être très « user friendly », mais en ce qui concerne l’extension https, elle contient quelques exemples de code intéressants [4].
Pour voir comment cela fonctionne, je vous propose de commencer par un petit script contenant les lignes ci-dessous. Vous noterez que dans ce script de test, j’ai défini l’URL avec une date fixée en dur (en l’occurrence au 21 janvier, mais vous pouvez le modifier si vous voulez) :
L’exécution du script peut se faire en ligne de commande (via la commande node suivie du nom du script) ou via votre environnement de développement (IDE) préféré. L’important, c’est de bien vérifier à l’exécution que la console vous renvoie du code HTML lisible, avec lequel nous allons pouvoir travailler.
Il s’agit d’un script assez simple, très inspiré des exemples fournis dans la doc officielle. Le point qui peut surprendre quand on n’a pas l’habitude, c’est la manière dont la variable rawData est alimentée. Elle est d’abord initialisée, puis complétée par concaténation, paquet (de données) après paquet, via l’événement data associé à l’objet res :
Ce n’est que quand l’événement end intervient que l’on sait que tous les paquets sont réceptionnés et que l’on peut afficher le contenu de la variable rawData dans la console :
Bon pour les requêtes HTTPS, on a vu l’essentiel, passons à la suite.
1.2.2 Le grattage des données
J’écrivais précédemment qu’il nous faut un outil permettant de manipuler le DOM.
Pour être maintenant plus précis, il nous faut un outil capable d’analyser le flux HTML réceptionné comme si c’était le DOM (Document Object Model) d’un navigateur [5]. Il nous faut en effet identifier certaines balises (pour en extraire des données) et en ignorer d’autres.
Lors de mes premières recherches, j’étais tombé sur un tuto présentant l’utilisation du package NPM cheerio. Je l’ai testé, mais il ne m’a pas convaincu. Non pas que l’outil soit mauvais, mais je cherchais un outil qui serait plus proche des fonctions que j’ai l’habitude d’utiliser quand je manipule le DOM du navigateur. Je suis finalement tombé sur un package NPM beaucoup plus intéressant à mes yeux, j’ai nommé jsdom.
La documentation du package jsdom est bien faite, et présente plusieurs exemples qui m’ont tout de suite intéressé, notamment celui-ci :
La première ligne ci-dessus nous montre comment créer un DOM virtuel à partir d’un code HTML quelconque (plus simple, tu meurs).
La seconde ligne nous montre que ce DOM virtuel a toutes les caractéristiques d’un DOM réel, et cerise sur le gâteau, on découvre dans l’exemple qu’il est possible d’utiliser l’API querySelector pour lancer des recherches dans ce DOM virtuel, afin d’en extraire le contenu textuel (via la propriété textContent). Franchement, c’est plus que je n’osais espérer.
Je charge donc le package jsdom dans mon projet Node avec la commande suivante :
La documentation de jsdom indique comment importer le composant dans les scripts dans lesquels on en a besoin. Il faut ajouter ces deux lignes au début de notre script :
En parcourant la documentation de jsdom, je découvre une fonctionnalité qui m’avait échappé en première lecture : l’objet JSDOM possède une méthode lui permettant d’exécuter des requêtes HTTP et HTTPS, c’est la méthode fromURL (cf. exemple suivant) :
Je peux donc confier à jsdom le soin de charger la page. Je n’aurai pas besoin d’utiliser l’extension https pour cette étape, par contre j’aurai besoin de cette extension pour le chargement des images (point que l’on abordera à la fin de l’article).
Un point très intéressant avec la méthode fromURL, c’est qu’elle génère une promesse (promise en anglais). Cette promesse, on va pouvoir la stocker dans un tableau, avec toutes les autres promesses du même type, et on passera ce tableau à la méthode Promise.all. Grâce à cette technique, on saura précisément à quel moment toutes les promesses ont terminé leur travail, et on saura quand sauvegarder l’ensemble des données récupérées.
Concrètement, si l’on suppose que la variable periods est un tableau contenant l’ensemble des dates à traiter, et que la fonction scraping (que l’on va écrire dans un instant) renvoie une promesse produite par la méthode fromURL, alors le gros de notre traitement se résume à ça :
Puisqu’on a l’outil qui va bien pour le grattage, penchons-nous maintenant sur la structure HTML d’une des pages de cette fameuse newsletter, en l’occurrence celle du 21 janvier. Cela nous permettra aussi d’aborder la manière dont le package jsdom permet d’analyser le contenu d’une page HTML.
Si vous n’avez jamais exploré le DOM d’un navigateur, c’est le moment ou jamais de vous y mettre. Tout en plaçant votre souris sur le titre (« Babbage's Analytics Engine Operates For The First Time »), faites un clic droit et sélectionnez l’option Inspecter l’élément (si vous êtes sur Firefox), ou Inspecter (si vous êtes sur Chrome). Quel que soit le navigateur, vous devriez voir à peu près la même chose, c’est-à-dire une partie d’écran similaire à ce qui est présenté en figure 2.
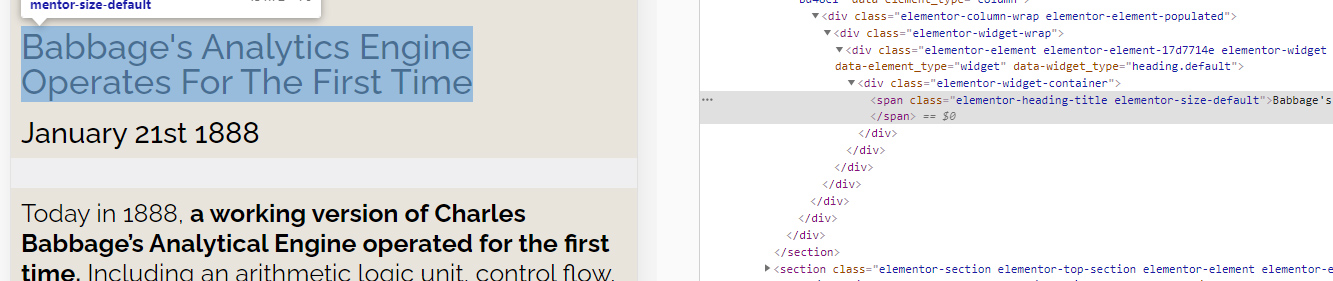
À gauche, vous avez le code HTML côté « scène », à droite le même code HTML côté « coulisses ». Si vous baladez la souris sur différentes lignes de la fenêtre de droite, vous verrez que le navigateur change le focus automatiquement dans la partie gauche, pour mettre en bleu la partie que vous avez ciblée dans la fenêtre de droite avec votre souris. C’est très pratique pour comprendre comment la page est structurée, et repérer les balises qui vont me permettre d’extraire plus facilement les données qui m’intéressent.
À partir de là, j’ai essayé de trouver le bon angle d’attaque pour gratter les données de ma newsletter. Après quelques minutes de recherche, j’ai constaté que les données qui m’intéressaient se trouvaient toutes à l’intérieur de balises <section> distinctes, et que ces balises <section> avaient un point commun : elles étaient toutes affectées à la classe CSS elementor-widget-container.
J’ai donc utilisé le package jsdom avec l’instruction suivante :
… ce qui m’a permis de récupérer un tableau JavaScript dont chaque item contenait une des balises <section>.
Après analyse, j’ai constaté que le titre se trouvait dans le 4e item du tableau (c’est à dire le numéro 3, puisque les items dans un tableau sont numérotés à partir de zéro). La date se trouve dans le 5e item (donc, le numéro 4), l’histoire détaillée dans le 7e item (donc, le numéro 6) et l’image dans le 8e item (donc, le numéro 7). À partir de là, les choses sont devenues assez simples, le grattage des données se résumant finalement aux quelques lignes suivantes :
Vous noterez que pour récupérer l’image qui se trouve dans une balise <img>, j’ai dû procéder un peu différemment. Ce que je veux récupérer dans la newsletter, c’est l’attribut src de la balise <img>, attribut qui contient l’URL permettant de récupérer cette image. Et il se trouve que cette balise <img> se trouve à une certaine profondeur dans le DOM, du coup, je lance un nouvel appel à la méthode querySelector à partir du niveau où je me trouve :
Eh oui, on peut relancer une recherche avec la fonction querySelector à partir de n’importe quel niveau, tout comme on le ferait dans un vrai DOM. Vous commencez à comprendre pourquoi le package jsdom me plaît tant ?
Concernant la génération des dates de la période à traiter, l’idéal serait de disposer d’une fonction s’acquittant de cette tâche. Cela tombe bien, j’en ai une sous le coude, récupérée sur un projet plus ancien, elle fera l’affaire :
Mais comme elle renvoie des dates au format ISO, et que ce qui m’intéresse ici, c’est de récupérer uniquement les numéros de mois et de jour, je lui « colle » derrière une petite fonction de filtrage avec la méthode map, complétée d’un substring, comme ceci :
J’ai parlé d’une fonction scraping, que met-on dedans ? Ma foi, rien de nouveau. On va juste encapsuler l’appel de la méthode JSDOM.fromURL, et renvoyer la promesse qu’elle génère, afin de pouvoir ultérieurement déterminer à quel moment toutes les promesses ont terminé leur travail (ça, on le verra dans la section suivante). Voici le code de la fonction scraping :
La fonction scraping stocke les données dans une variable de type tableau, la variable stories. Il s’agit d’une variable globale, il ne faut pas oublier de l’initialiser au début de notre script :
Toute la mécanique étant en place en ce qui concerne le grattage de page, il nous reste à aborder la question du stockage des données, après grattage.
1.2.3 Le stockage des données
On pourrait utiliser une base de données pour stocker les données résultant du grattage, et le faire date par date, peut être quelque part dans la fonction scraping (vue à la fin de la section précédente). Mais j’ai choisi la simplicité, en décidant de stocker mes données dans un fichier au format JSON, une fois que toutes les pages ont été grattées. On a vu que le grattage se fait dans la fonction scraping, et que cette dernière renvoie une promesse.
On avait vu également qu’il était possible de déterminer à quel moment toutes les promesses seraient terminées, au moyen d’un code de ce genre :
Il nous reste à remplacer l’appel de console.log par quelque chose de plus intéressant, à savoir l’écriture dans un fichier JSON du contenu du tableau stories :
Dans le code précédent, nous faisons appel à l’objet fs. Il s’agit de l’objet instancié par l’import de l’API du même nom. Cette API est un composant natif de Node.js, dédié à la lecture et au stockage de fichiers. Puisque nous utilisons cette API, nous devons l’importer au début de notre script, via l’ajout de la ligne suivante :
Vous noterez que dans le code qui précède, j’ai laissé en commentaire l’appel d’une fonction que j’ai appelée stockerImages, car nous ne l’avons pas encore écrite. Il est donc temps de se pencher sur la récupération et le stockage des images… et c’est là que l’API https va se révéler utile.
Je colle dans la suite le code de la fonction stockerImages, et je le commente juste après :
Notre point de départ, c’est le tableau global stories, car c’est lui qui contient les URL des images. Donc pour chaque poste de stories, on va déclencher une requête HTTPS qui va récupérer l’image correspondante, selon un mécanisme très proche de celui que nous avions étudié au début de l’article. La seule différence réside dans le fait que nous récupérons des données binaires, et non textuelles, ce qui nous oblige initialiser la variable data avec un objet de type Stream, plutôt qu’avec du texte :
Pour pouvoir utiliser ce type d’objet, nous devons ajouter la déclaration suivante au début de notre script :
Pour le stockage des images, j’ai opté pour la méthode fs.writeFileSync (stockage de fichier en mode synchrone), c’est le mode le plus simple, mais il est très efficace et convient parfaitement dans notre cas.
Pour savoir si toutes les images sont sauvegardées, et envoyer un message de circonstance dans la console, j’ai opté pour une technique qui relève plutôt de la bidouille, avec la décrémentation de la variable nb_images, initialisée au départ avec le nombre de postes du tableau stories. Une manière plus élégante de faire consisterait à encapsuler le lancement des requêtes HTTPS dans des promesses, de stocker ces promesses dans un tableau et d’appliquer un Promise.all sur ce tableau, afin de savoir quand toutes les images sont récupérées. J’ai écarté cette solution plus élégante, mais aussi plus verbeuse, afin de ne pas transformer cet article en roman-fleuve. J’espère que vous voudrez bien me pardonner ;-).
Conclusion
Je sais que beaucoup de développeurs n’ont jamais entendu parler de web scraping, donc je pense que c’est un sujet très rarement enseigné dans les écoles. C’est dommage, car il me semble que le web scraping a un gros potentiel en tant qu’outil pédagogique, du fait des différentes techniques qu’il nécessite de connaître et de mettre en œuvre.
La méthode de web scraping que je vous ai présentée ici n’est pas la seule manière de faire. Si elle a le mérite d’être simple et rapide à mettre en œuvre, elle a cependant une grosse limite. En effet, si elle est très bien adaptée au grattage de pages générées par un serveur, en revanche elle n’est pas adaptée au grattage de données générées dynamiquement par du JavaScript, tel que l’on peut en trouver dans une application de type SPA (Single Page Application).
Si vous êtes confronté à la problématique de devoir gratter des pages générées dynamiquement par une application de type SPA, il vaut mieux vous tourner vers une solution comme le projet Puppeteer [6] [7], qui est embarqué dans le package NPM du même nom. Puppeteer n’est pas une solution dédiée au web scraping, mais on peut l’utiliser pour cela, j’essaierai d’aborder ce sujet dans un prochain article.
Références
[1] Le web scraping vu par Wikipédia : https://fr.wikipedia.org/wiki/Web_scraping
[2] Le site de l’éditeur Manning : https://www.manning.com
[3] Lien vers la newsletter du 21 janvier : https://freecontent.manning.com/on-this-day-01-21/
[4] Documentation de l’API HTTPS de Node : https://nodejs.org/dist/latest-v14.x/docs/api/https.html
[5] Définition du DOM : https://fr.wikipedia.org/wiki/Document_Object_Model
[6] Lien vers le package NPM du projet Puppeteer : https://www.npmjs.com/package/puppeteer
[7] T. COLOMBO, « Automatisation de l'extraction d'information d'une page web nécessitant une authentification », GNU/Linux Magazine n°229, septembre 2019 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-229/Automatisation-de-l-extraction-d-information-d-une-page-web-necessitant-une-authentification



