

Aperçu de quelques logiciels et applications essentiels gravitant autour du langage C.
Introduction
Depuis sa sortie dans les années 70, le langage C et la programmation en général ont bien évolué. De nombreux outils sont venus se greffer pour améliorer la qualité de production, réduire les risques de bugs, faciliter la maintenance et la gestion des projets. Parmi ces outils, on trouve en premier lieu ceux liés au compilateur gcc, comme le débogage avec gdb, la couverture de code avec gcov ou le profilage de code avec gprof. Mais l'on trouve également des utilitaires de compilation comme make, des analyseurs de code, de fuite de mémoire, des utilitaires de tests unitaires, de tests d'intégration, de modélisation, de vérification formelle, des générateurs de documentation, sans oublier des bibliothèques, des environnements de développement, des interfaces graphiques, des outils de gestion de versions et de management de projets.
Dans cet article, nous nous proposons de faire un rapide survol des outils GNU/Linux rattachés au langage C : une liste non-exhaustive – on ne pourra pas lister toutes les applications et bibliothèques existantes – mais assez représentative, pour mener à bien un projet de développement en C.
1. GCC on the fly
Parmi les options du compilateur GCC disponibles, version GNU libre développée par Richard Stallman du compilateur CC, on trouve notamment des options liées au débogage (-g), à la couverture de code (--coverage), au profilage de code (-pg), et également des options de détection d'erreurs (man gcc).
1.1 Détection des erreurs
Une erreur détectée par GCC interrompt la compilation d'un fichier objet ou l'édition des liens du programme. Elles peuvent être dues à des erreurs de syntaxe, de grammaire (utiliser un type long char par exemple), de déclarations, de constantes (réassigner une constante), de cast entre différents types incompatibles, des erreurs de linkage (un symbole externe non résolu, une librairie non renseignée ou introuvable).
En plus de détecter ces erreurs, GCC peut aussi analyser le code plus en détails et alerter sur de possibles problèmes à venir. Ces alertes, ou warnings, peuvent être assez importantes. Pour activer la plupart des alertes, ajoutez l'option -Wall à la compilation. Dans ce cas, GCC détectera les variables déclarées mais non utilisées, les erreurs d'adresses, de limites de tableau, d'énumérations, de commentaires, de déclarations implicites, de parenthèses et bien d'autres encore. Certaines alertes ne sont pas activées par l'option -Wall, comme celles de l'option -Wextra (cf. man gcc).
1.2 Débogage
La compilation ne garantit pas que le programme va fonctionner dans tous les cas. Aussi, une vérification consiste à passer le débogueur GDB (The GNU debugger) pour vérifier l'état des variables, des pointeurs et des sorties de fonctions.
Pour ce faire, on ajoute l'option -g à la ligne de commandes GCC, ce qui a pour effet d'ajouter des symboles de débogage au fichier binaire, ce qui augmente également sa taille. Par contre, cette option est à proscrire durant la compilation du programme de production si vous voulez protéger le code source. C'est pourquoi, en principe, on définit deux environnements de compilation : l'un pour la production, l'environnement Release, l'autre pour le débogage, l'environnement Debug.
Nous utiliserons le code d'exemple suivant (exemple.c) :
#include <stdlib.h>
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int afficher(const char *message)
{
char erreur[1] = {0};
long c = erreur;
erreur = printf("%s\n", message);
if (erreur < 0) {
return FALSE;
}
return TRUE;
}
int main(int argc, char *argv[])
{
const char *p = NULL;
if(argc > 1){
p = argv[1];
}else{
p = "C is sexy";
}
if (!afficher(p))
{
perror("afficher");
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
Pour ajouter les symboles de débogage :
$ gcc exemple.c -g -o Debug/exemple
On peut à présent utiliser le débogueur GDBavec ce fichier binaire. Pour vérifier l'état du programme à un endroit précis du code, on doit placer, avec gdb, des points d'arrêt (ou breakpoints) aux lignes de code souhaitées (break Ligne ou break Fonction). Une fois les points d'arrêt placés, on lance le programme sous gdb (commande r), qui se mettra en pause au premier breakpoint. À partir de là, on peut utiliser les commandes de gdb pour connaître la valeur d'une variable (commande display), de la mémoire, d'une fonction, mais l'on peut également suivre le programme instruction par instruction (commandes s, n) jusqu'au bogue, si bogue il y a, ou sauter vers le prochain breakpoint.
Exemple d'utilisation en ligne de commandes :
$ gdb Debug/exemple
[...]
Reading symbols from /home/dams/Debug/exemple...done.
(gdb) break main
Breakpoint 1 at 0x40058c: file exemple.c, line 20.
(gdb) r
Starting program: /home/dams/Debug/exemple
Breakpoint 1, main (argc=1, argv=0x7fffffffea48) at exemple.c:20
20 const char *p = NULL;
(gdb) s
22 if(argc > 1){
(gdb) s
25 p = "C is sexy";
(gdb) s
27 if (!afficher(p))
(gdb) s
afficher (message=0x400688 "C is sexy") at exemple.c:9
9 int erreur = 0;
(gdb) s
11 erreur = printf("%s\n", message);
(gdb) n
C is sexy
12 if (erreur < 0) {
(gdb) display erreur
1: erreur = 10
(gdb) k
(gdb) q
On retrouve souvent les principales commandes gdb intégrées aux environnements de développement, ce qui facilite le débogage, mais on trouve également des interfaces pour gdb, comme Ddd et Cgdb [1].
1.3 Couverture de code
La couverture de code permet de lister les instructions exécutées durant le déroulement d'un programme, et a contrario, celles qui n'ont jamais été exécutées, i.e. le code mort. C'est très utile pour les tests unitaires, pour lesquels un exécutable de test est créé incluant la librairie à tester : on sait ainsi quelles parties du code furent testées, i.e. la couverture de code, un indicateur principal de qualité du logiciel.
gcov est une application GNU/Linux de référence pour la couverture de code. Dans le principe, pour utiliser gcov, il faut compiler la librairie ou le programme à tester avec GCC et l'option --coverage. Ensuite, durant l’exécution, deux fichiers .gcno et .gcda, contenant les informations de couverture de code et pouvant être lus par gcov, sont générés (cf. man gcc, man gcov).
Par exemple :
$ gcc --coverage exemple.c exemple
$ ./exemple
C is sexy
$ gcov exemple.c
File ‘exemple.c’
Lines executed:73.33% of 15
Creating ‘exemple.c.gcov’
$ less exemple.c.gcov
...
1: 18:int main(int argc, char *argv[])
-: 19:{
1: 20: const char *p = NULL;
-: 21:
1: 22: if(argc > 1){
#####: 23: p = argv[1];
-: 24: }else{
1: 25: p = "C is sexy";
-: 26: }
1: 27: if (!afficher(p))
-: 28: {
#####: 29: perror("afficher");
#####: 30: return EXIT_FAILURE;
-: 31: }
1: 32: return EXIT_SUCCESS;
-: 33:}
On lit ci-dessus que les lignes 23, 29 et 30 du code n'ont pas été exécutées (caractères #), et que les lignes 25, 27, 31 ont été exécutées une fois, pour une couverture de code de 73.33 %.
Il existe également l'application Lcov qui génère une interface graphique pour afficher ces informations de façon plus conviviale [2].
1.4 Profilage de code
Le profilage de code renseigne sur les ressources (processeur et mémoire) utilisées par un programme, de façon à déterminer les fonctions à optimiser, entre autres. Le premier utilitaire que l'on pourrait citer est l'utilitaire gprof, qui nécessite également GCC. Pour utiliser gprof, il faut compiler le programme avec l'option -pg (cf. man gcc). Ensuite, l’exécution du programme générera un fichier gmon.out, qui pourra être lu et analysé par gprof (on indique à nouveau le programme exécutable en paramètre).
Par exemple :
$ gcc -pg exemple.c -o exemple
$ ./exemple
C is sexy
$ gprof --brief exemple
...
% cumulative self self total
time seconds seconds calls Ts/call Ts/call name
0.00 0.00 0.00 1 0.00 0.00 afficher
Call graph
granularity: each sample hit covers 2 byte(s) no time propagated
index % time self children called name
0.00 0.00 1/1 main [7]
[1] 0.0 0.00 0.00 1 afficher [1]
-----------------------------------------------
Index by function name
[1] afficher
Avec un programme aussi court, l'information n'est pas très pertinente, mais sur un programme plus complexe, on visualiserait ainsi les fonctions requérant le plus de temps processeur et donc, les moins optimisées.
D'autres logiciels de profilage de code existent, en particulier le logiciel Oprofile, qui enregistre l'utilisation des ressources système durant une session de profilage et sprof, comme gprof, mais pour les bibliothèques partagées [3, 4].
2. Les Makefiles
Devenus incontournables pour les projets de développement, les fichiers Makefiles sont des fichiers textes utilisés par le moteur de production GNU Make pour faciliter la compilation et l'installation d'un programme. Après une première compilation, seuls les fichiers sources modifiés sont recompilés, ce qui apporte un gain de temps non négligeable.
Un fichier nommé Makefile doit être édité – soit directement, soit en passant par des outils comme les autotools (ou GNU build system) – de façon à renseigner les fichiers sources à compiler et leurs commandes decompilation. Chaque commande doit être précédée d'une tabulation (sans espaces). Les étiquettes (labels) des opérations sont suivies de deux points. Par défaut, c'est l'opération all qui s'exécute.
Exemple de fichier Makefile :
all: exemple4
exemple4: exemple4.o fonctions.o
<-TAB->gcc exemple4.o fonctions.o -o exemple4
exemple4.o: exemple4.c
gcc -o exemple4.o -c exemple4.c
fonctions.o: fonctions.c
gcc -o fonctions.o -c fonctions.c
clean:
rm -rf *.o exemple4
$ make
gcc -o exemple4.o -c exemple4.c
gcc -o fonctions.o -c fonctions.c
gcc exemple4.o fonctions.o -o exemple4
$ make clean
rm -rf *.o exemple4
Les projets les plus complexes font appel à des générateurs de fichiers Makefiles, comme les autotools (automake, autoconf), et possèdent en principe une phase de configuration (configure), de compilation (make), d'installation (make install) et de désinstallation (make uninstall).
3. Les environnements de développement
Les environnements de développement (EDI, ou IDE, Integrated Development Environment), sont des interfaces avec des outils intégrés pour faciliter le développement. Dans cette catégorie, on trouve des éditeurs de textes à coloration syntaxique, mais aussi des systèmes complets de développement avec moult plugins et accessoires.
3.1 Les éditeurs de textes
Les premiers EDI furent des éditeurs de textes optimisés pour la programmation, comme Vim (Vi Improved, de Bram Moolenaar) et Emacs (développé à l'origine par Richard Stallman sur un PDP-10). Ces éditeurs étant légers, rapides à lancer et à utiliser, sont parfaits pour une édition de code ponctuelle.
Vim gère plusieurs modes d'édition (commande, insertion, remplacement, visualisation) et s'utilise en console. Il s'ouvre par défaut en modecommande. Pour se placer en mode d'insertion de texte, il faut appuyer une fois sur la touche I ; pour se remettre en mode commande, la touche ESC ; pour le mode remplacement de texte, la touche R ; et pour le mode visualisation, la touche V. Pour quitter, se placer en mode commande, puis saisir les caractères :q (ou :wq pour enregistrer et quitter). Ensuite, il existe une multitude de raccourcis clavier pour le traitement de texte et autres opérations, comme par exemple CTRL-W V pour diviser la fenêtre verticalement, CTRL-W F sur un #include pour ouvrir le fichier inclus, ou CTRL-W I sur une fonction pour retrouver sa déclaration, dd (delete) pour couper une ligne, yy (yank) pour la copier, p (put) pour la coller, u (undo) pour revenir en arrière, etc.
De plus, Vim (voir figure 1) est hautement paramétrable et possède de nombreux modules, ce qui en fait un éditeur de premier choix pour ses utilisateurs expérimentés.
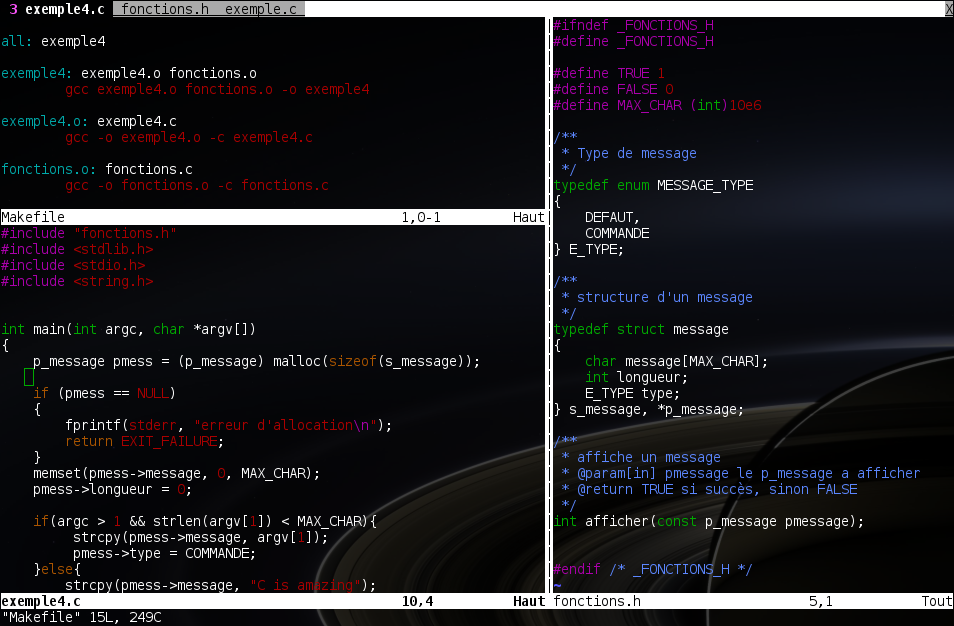
Fig. 1 : Édition de code sous Vim
Emacs, quant à lui, gère plusieurs tampons de textes (buffers), des macros (d'où le nom Emacs, pour Editing MACroS), plusieurs modes d'édition, et se lance par défaut avec une interface graphique. Emacs dispose aussi de nombreux raccourcis clavier, dont les suivants : CTRL-X CTRL-C pour quitter, CTRL-Z pour suspendre la session, CTRL-S pour une recherche, CTRL-/ pour un undo, CTRL-X CTRL-S pour enregistrer, CTRL-W pour couper, Alt+W pour copier, et CTRL-Y pour coller. Ensuite, Emacs est lui aussi hautement paramétrable et possède de nombreux modules [6].
De plus, il existe aujourd'hui de nombreux éditeurs de textes à coloration syntaxique pour la programmation, comme Gedit (l'éditeur de GNOME), Kate (l'éditeur de KDE), Nedit, Nano, Scribes ou Scite.
Sous Linux, et Unix en général, il est recommandé de connaître les commandes de base de l'éditeur Vi, qui peuvent, par exemple, être nécessaires sur un ancien serveur.
3.2 Les environnements graphiques
Il s'agit de logiciels dédiés au développement, contenant en général de nombreuses fenêtres, de l'auto-complétion et divers outils. Plus complets sur certains points, mais aussi plus lourds à charger, ils ont l'avantage de centraliser les ressources (fichiers sources, plugins) nécessaires au développement dans un unique projet de développement. Il en existe un bon nombre sous GNU/Linux.
L'un des plus connus est probablement Eclipse, projet open source qui possède de nombreux forks commerciaux, davantage utilisé pour le développement Java, mais qui possède cependant un plugin CDT pour les langages C et C++. Eclipse (voir figure 2) possède de nombreux plugins et tourne sous une JVM (Java Virtual Machine), aussi requiert-il pas mal de ressources système [7].
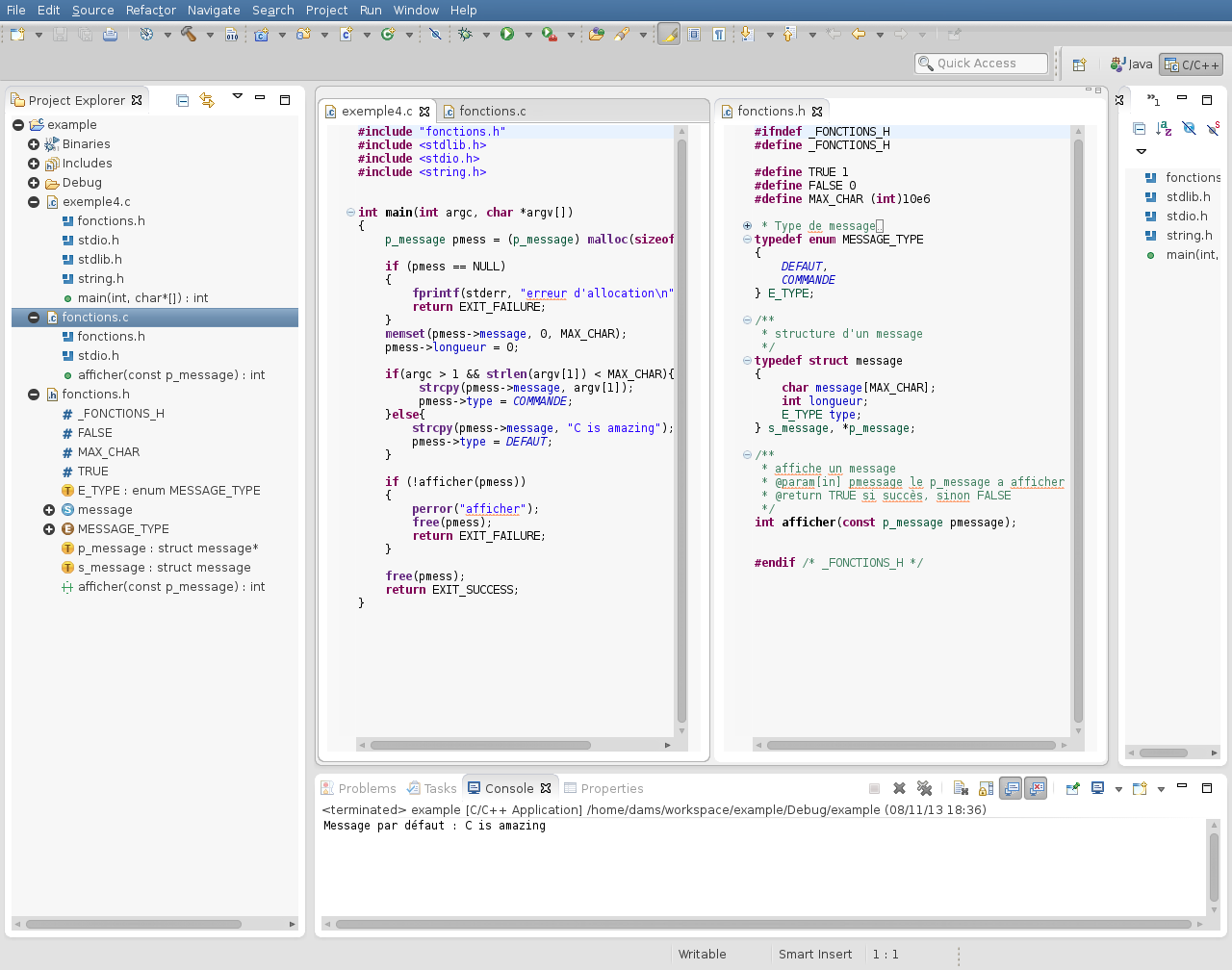
Fig. 2 : Eclipse Kepler avec le plugin CDT
Très connu également sous GNU/Linux, CodeBlocks est également bien fourni, avec de nombreux plugins à portée de clic, et il gère nativement les projets en langage C. On trouve également Anjuta, Geany, CodeLite, NetBeans (concurrent d'Eclipse pour Java, gère également les projets C), Kdevelop (l'IDE de KDE), Qt-Creator (pour les projets Qt) et bien d'autres [8, 9].
4. Les analyseurs de code
En plus des avertissements et analyses de GCC, il existe des logiciels dédiés à l'analyse de code, en particulier pour du code C. L'un des plus anciens est probablement le programme Lint, ancêtre de nombreux analyseurs Lint-like, développé dans les Laboratoires Bells par Stephen C. Johnson, et dont la plupart des détections ont été portées sous GCC [10].
Il existe aujourd'hui bon nombre d'analyseurs de code statiques, certains fournissant également des indicateurs de métrologie, ou metrics, d'autres intégrant également de la vérification formelle, et certains sont même de véritables plateformes de vérification.
Parmi les solutions libres ou open source les plus connues, on peut citer CppCheck, intégré dans de nombreux EDI en tant que plugin et qui fonctionne pour le C et le C++ ; Splint, une version évoluée de Lintgérant également la vérification formelle ; Frama-C et SonarQube qui sont tous deux des plateformes de vérification, ainsi que Sparse, de Linus Torvalds – le créateur du système Linux –, dédié à l'analyse des noyaux Linux. Mais il en existe de nombreux autres en versions commerciales, complets, certifiés ou récompensés, et indispensables pour les applications industrielles critiques comme Veracode, Polyspace, KlockworkInsight, QA·C ou CodeSonar. La plupart font référence à la norme MISRA C pour les règles industrielles de codage en C [11].
On trouve également l'excellent et open source CCCC (C and C++ Code Counter), davantage spécialisé pour les metrics (lignes de code, commentaires par ligne de code, complexité de code), et qui produit également une interface HTML.
Pour un premier analyseur de code, CppCheck, qui s'utilise d'un clic de souris avec CodeBlocks par exemple, indiquera, entre autres, si une variable peut être réduite de portée, si elle est obsolète, ou si elle risque de générer une fuite de mémoire.
5. Les détecteurs de fuite de mémoire
Lorsqu'un programme ne libère pas ses allocations mémoire (avec des appels à la fonction free) et qu'en plus, il requiert de plus en plus de mémoire durant son déroulement, le système risque d'être à court de mémoire disponible, générant un ralentissement, voire une panne système. Pour éviter ce phénomène de fuite de mémoire, il existe des détecteurs, qui permettent entre autres de savoir si une allocation mémoire avec un appel à la fonction malloc n'a pas été libérée par un free.
De façon générale, sous GNU/Linux, on peut vérifier l'état de la mémoire du système via de nombreuses commandes et applications permettant d'afficher la mémoire consommée par les processus, allant de la commande ps à la commande top, en passant par vmstat, ou la lecture d'un fichier statm d'un dossier de processus du répertoire virtuel /proc/. Il existe également des moniteurs système comme gnome-system-monitor, ksysguard, conky ou gkrellm, des serveurs de monitoring comme Nagios, Munin ou mon, et une multitude d'applets de bureau comme adesklets ou gdesklets.
Cependant, pour obtenir précisément la liste des instructions d'un programme à l'origine d'une fuite de mémoire, il faut passer par des débogueurs de mémoire (memory debuggers) comme Valgrind ou des outils pour Gcc comme Mudflap, Mcheck, Mprobe et Mtrace. On trouve aussi dans le domaine commercial des outils comme Purify, BoundsChecker et Insure++ [12, 13, 14].
Valgrind possède plusieurs outils intégrés comme Memcheck, qui est utilisé par défaut, Cachegrind pour la mémoire cache, Callgrind pour les graphes d'appels et Hellgrind pour les threads. L'outil Memcheck renseigne notamment sur la mémoire heap allouée, les fuites de mémoire possibles et les variables non initialisées. Par exemple :
$ valgrind ./exemple4
==7180== Memcheck, a memory error detector
==7180== Copyright (C) 2002-2011, and GNU GPL’d, by Julian Seward
et al.
==7180== Using Valgrind-3.7.0 and LibVEX; rerun with -h for
copyright info
==7180== Command: ./exemple4
...
Message par défaut : C is amazing
==7180== HEAP SUMMARY:
==7180== in use at exit: 0 bytes in 0 blocks
==7180== total heap usage: 1 allocs, 1 frees, 10,000,008 bytes
allocated
==7180==
==7180== All heap blocks were freed -- no leaks are possible
...
Entre caractères '==' on trouve l'identifiant du processus, tandis que le résumé nous informe qu'il y a bien eu une allocation et une libération de mémoire d'un espace de 10 Mo, et qu'aucune fuite n'a été détectée (no leaks are possible).
6. Les tests unitaires
Les tests unitaires vont permettre de tester les fonctionnalités du code, dans les cas prévus, les cas d'erreurs et les cas limites, pour s'assurer que le programme fonctionne bien selon ses spécifications.
En principe, il faudra fournir une bibliothèque du programme dont les fonctions exportées pourront être testées par un programme de test linké avec celle-ci et une bibliothèque de tests unitaires. Une fois les tests unitaires réalisés, en exécutant ce programme de tests, ils pourront être à nouveau utilisés pour s'assurer de la compatibilité des nouvelles versions (tests de non-régression). Au niveau des EDI, on ajoute généralement un projet spécifique pour les tests unitaires – que l'on trouve parfois dans la liste des types de projets disponibles – qui sera dépendant du projet de développement principal et linké avec une bibliothèque de tests unitaires (comme CUnit).
Il existe de nombreux frameworks de tests unitaires pour le C, comme Check et CUnit, voire des frameworks pour C++ réutilisables sous un projet de tests C++, en ajoutant des balises externes C autour des #include de fichiers d'en-têtes de la librairie C à tester [15].
Au niveau du programme de tests, celui-ci repose sur une suite d'assertions qui doivent être vérifiées pour valider les tests. Par exemple, avec Check, pour tester une fonction afficher :
...
START_TEST (afficher)
{
fail_if (afficher(NULL) == TRUE, "doit retourner FALSE si
argument NULL");
fail_if (afficher("test") == FALSE, "doit retourner TRUE si
argument valide");
}
END_TEST
...
Les tests unitaires sont souvent utilisés en milieu industriel et sont intégrés dans des normes de qualité de logiciel avec, en plus, une certaine couverture de code à respecter selon la criticité du projet (cf. IEEE Standard for Software Unit Testing (IEEE 1008-1987), la norme aéronautiqueED-12B, la norme industrielle IEC 61508 ou la norme spatiale européenne ECSS-E-40). Ils font également l'objet d'une certification internationale pour les testeurs professionnels : l'International Software Testing Qualifications Board (ISTQB).
7. Les gestionnaires de versions
Pour faciliter le suivi du développement du projet (modifications, ajouts de fichiers, versions), il existe des gestionnaires de versions (Version Control System ou Revision Control Software). Ces derniers sont devenus indispensables pour tout projet de développement.
Au niveau open source, l'un des premiers et des plus connus à être utilisé fut le système CVS(Concurrent Versions System). CVS peut en effet s'utiliser en local ou en client-serveur, un serveur stockant un dépôt de fichiers sources, tandis qu'un client peut à distance rapatrier une version sur son poste (commande checkout), mettre à jour cette version locale (commande commit), puis mettre à jour la version du serveur (commande merge). On trouve également le gestionnaire Subversion(SVN) du groupe Apache, qui permet de gérer des branches spécifiques de dépôts.
Mais le gestionnaire de versions du moment est certainement Git, conçu par Linus Torvalds. Git apporte davantage de souplesse, de robustesse et de contrôle, et on le retrouve dans de nombreux projets open source, comme ceux des sites GitHub et Gitorious. Au niveau de ses interfaces graphiques, on trouve des interfaces comme Gitk (et son module Git-gui, inclus avec Git). Git-cola, Giggle, Qgit, Gitg, et bien d'autres. Il est également bien utile de disposer d'une interface web pour suivre les dépôts du serveur. Pour cela, on trouve des interfaces web comme Gitweb (distribué avec Git), GitStat, Viewgit, et des interfaces plus commerciales comme Gitorious, GitHub et Stash d'Atlassian [16, 17].
8. Sans oublier...
8.1 Les générateurs de documentation d'API
Des générateurs de documentation comme Doxygen ou Docurium généreront de la documentation d'API à partir des commentaires des fichiers sources compris entre des balises spécifiques. La figure 3 montre un exemple d'une telle documentation générée avec Doxygen. Les documents peuvent également être centralisés et partagés grâce à des wikis comme DokuWiki, MediaWiki ou WikiWikiWeb, mais aussi des solutions plus commerciales comme BrainKeeper, Confluence ou SocialText [18, 19, 20].
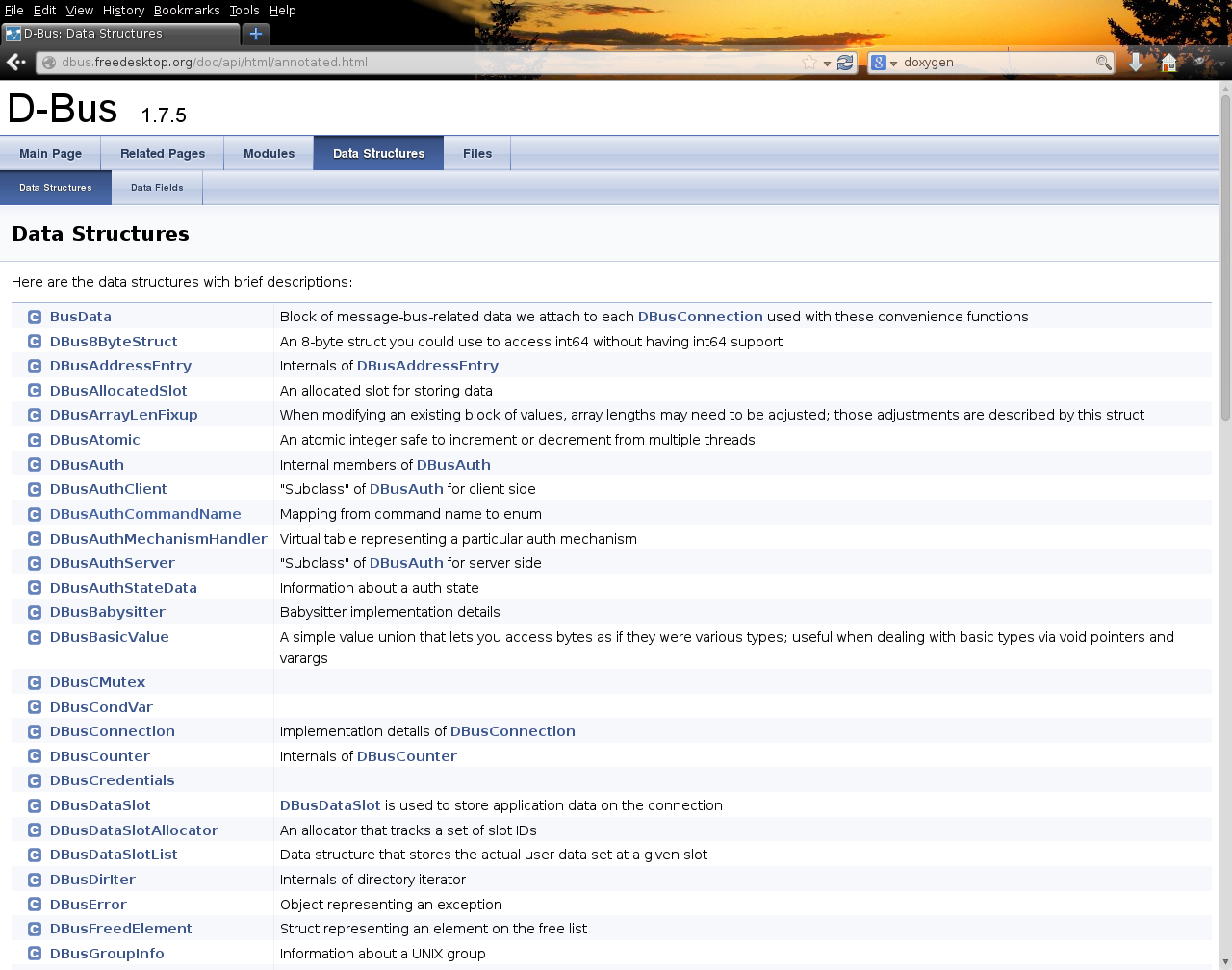
Fig. 3 : Exemple de documentation avec Doxygen, pour l’API de D-Bus
8.2 Les gestionnaires de projets
Pour les projets nécessitant d'importantes ressources humaines, pour faciliter la gestion des tâches et le planning de chacun, un gestionnaire de projets peut s'avérer indispensable. Parmi ceux-ci, on trouve des gestionnaires spécialisés dans le suivi des tâches, souvent utilisés pour la gestion des incidents, bugs et améliorations, comme Bugzilla, Redmine ou Mantis, mais aussi des outils commerciaux comme Zendesk ou CodeBeamer. On trouve également des gestionnaires tout-en-un, avec gestion de ressources humaines, planning et gestion des incidents intégrés, comme CalligraPlan de KDE, 2-plan, FusionForge, OpenProject ou des outils commerciaux comme MetaTeam d'Atlova, 10,000ft, Jira d'Atlassian [21, 22].
8.3 Les outils de modélisation UML
Au niveau de la conception, il existe des langages normalisés, dont le plus connu est UML (Unified Modeling Language). Bien que les diagrammes UML soient davantage utilisés pour les langages orientés objets (diagrammes de classes), une bonne partie des diagrammes sont réutilisables pour un projet C, comme les diagrammes d'activité, les diagrammes de séquences, les diagrammes de cas d'utilisation. Ce sont des outils libres ou open source comme Dia, Umbrello, Modelio (voir figure 4), EclipseUML2Tools ou ArgoUML, ou des outils commerciaux comme EnterpriseArchitect, Poseidon ou Rhapsody d'IBM. L'utilisation de schémas normalisés facilite la reprise du projet et rend la documentation compréhensible par d'autres équipes.
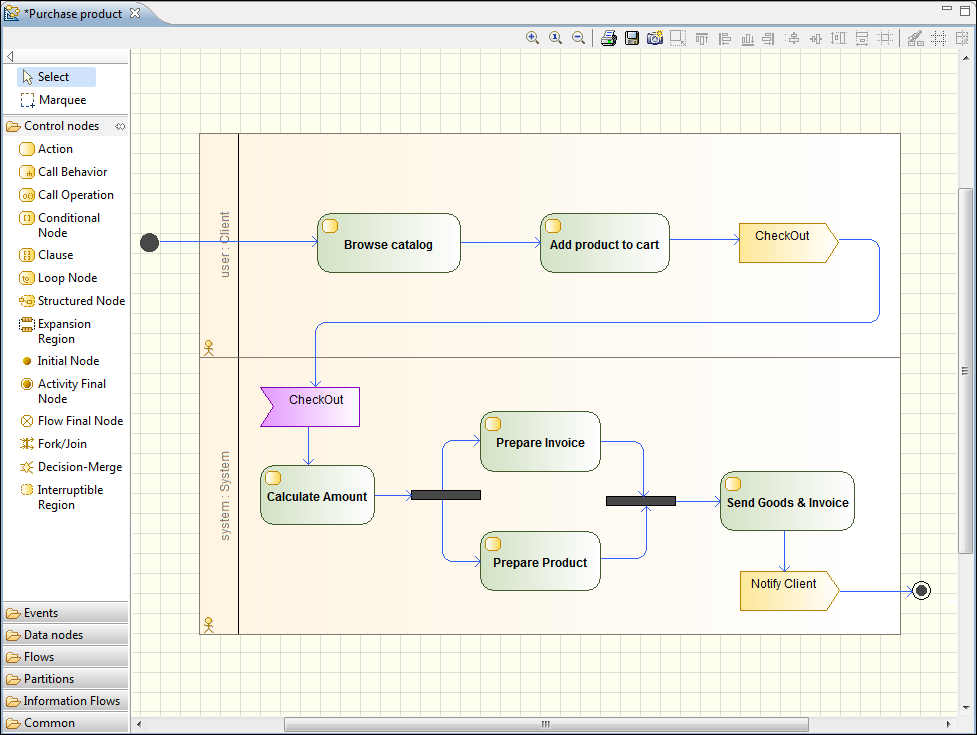
Fig. 4 : Diagramme UML d’activité, avec Modelio
8.4 Les logiciels de tests d'intégration
Les tests d'intégration ne doivent pas être oubliés : ils permettent de s'assurer de la qualité d'un livrable avec des logiciels comme Jenkins (open source), Apache Continuum (voir figure 5) ou TeamCity (commercial). En principe, un test d'intégration va récupérer les sources du projet depuis un dépôt (Git, SVN), lancer la commande de compilation, exécuter les tests unitaires et exécuter la commande de génération du package final. Si tout se passe bien, le test d'intégration est validé, mais à la moindre erreur (une erreur de compilation ou un test unitaire qui ne passe pas) c'est l'ensemble du test qui échoue. L'avantage, c'est qu'il s'agit d'un processus automatisé, et que l'on dispose d'une traçabilité et de la version la plus récente du projet.
Fig. 5 : Apache Continuum
8.5 Les validations formelles et model-checkers
Pour les projets les plus complexes, des model-checkers comme Spin ou Smv permettront de valider un modèle du programme. Pour les projets les plus critiques, il existe également des outils de validation formelle permettant de valider formellement, avec des annotations spécifiques, le projet, prouvant ainsi sa fiabilité et sa sûreté. On trouve par exemple les modules Jessie et Wp pour Frama-C, les logiciels Splint, BLAST ou l'Atelier-B de ClearSy [23].
8.6 Les gestionnaires d'exigences
Un projet bien étudié comporte au préalable une phase d'étude et de rédaction d'un cahier des charges, dans lequel le client et la maîtrise d'œuvre doivent définir certaines exigences pour le produit final (fonctionnalités, normes, sécurité, internalisation, performance, ergonomie, etc.). Le nombre des exigences peut être assez conséquent et pour faciliter leur suivi, leur maintenance et leur gestion, il existe des gestionnaires d'exigences, souvent intégrés dans une solution globale de conception, comme PTC Integrity de MKS, Reqtify de Dassault Systemes, Visure Requirement de Visure Solutions ou Rational DOORS d'IBM.
Conclusion
Il existe de nombreux outils gravitant autour d'un projet de développement en C, dont certains sont essentiels, voire indispensables, comme le débogueur Gdb, le moteur de production Make, le débogueur de mémoire Valgrind et le gestionnaire de versions Git.
Cependant, on trouve aujourd'hui des outils pour satisfaire la plupart des besoins les plus exigeants, de la conception au développement, en passant par la gestion de projets. La liste ci-présentée n'est pas exhaustive, mais elle offre un aperçu de l'état actuel du marché. Il en existe encore bien d'autres, autant dans le domaine libre et open source que commercial.
Références
[1] BODOR D., « Petit tutoriel du débogueur GDB », GNU/Linux Magazine France Hors-Série n°55, 2011
[2] The Linux Test Project, LCOV, http://ltp.sourceforge.net/coverage/lcov.php, 2013
[3] LEVON J., ELIE P., OPROFILE, http://oprofile.sourceforge.net/news/, 2013
[4] WIKIPEDIA, List of performance analysis tools, http://en.wikipedia.org/wiki/List_of_performance_analysis_tools, 2013
[5] GNU.org , The GNU Make Manual, http://www.gnu.org/software/make/manual/make.html, 2013
[6] WIKIPEDIA, Emacs, http://fr.wikipedia.org/wiki/Emacs, 2013
[7] The Eclipse Foundation, CDT Project, http://www.eclipse.org/cdt/, 2013
[8] Oracle Corporation, NetBeans IDE Features (C and C++ Development), https://netbeans.org/features/cpp/, 2013
[9] Digia Plc, Qt Project, http://qt-project.org/, 2013
[10] WIKIPEDIA, Lint (software), http://en.wikipedia.org/wiki/Lint_(software), 2013
[11] WIKIPEDIA, List of tools for static code analysis, http://en.wikipedia.org/wiki/List_of_tools_for_static_code_analysis, 2013
[12] GNU.org, Heap Consistency Checking, http://www.gnu.org/software/libc/manual/html_node/Heap-Consistency-Checking.html, 2013
[13] WIKIPEDIA, Memory debugger, http://en.wikipedia.org/wiki/Memory_debugger, 2013
[14] The Valgrind Developers, Memcheck : a memory error detector, http://valgrind.org/docs/manual/mc-manual.html, 2013
[15] WIKIPEDIA, List of unit testing frameworks, http://en.wikipedia.org/wiki/List_of_unit_testing_frameworks, 2013
[16] WIKIPEDIA, List of revision control software, http://en.wikipedia.org/wiki/List_of_revision_control_software, 2013
[17] Git, Interfaces, frontends, and tools, https://git.wiki.kernel.org/index.php/InterfacesFrontendsAndTools, 2013
[18] Docurium, https://github.com/libgit2/docurium, 2013
[19] WIKIPEDIA, Comparison of documentation generators, http://en.wikipedia.org/wiki/Comparison_of_documentation_generators, 2013
[20] Bugzilla, http://www.bugzilla.org, 2013
[21] WIKIPEDIA, Comparison of issue-tracking systems, http://en.wikipedia.org/wiki/Comparison_of_issue-tracking_systems, 2013
[22] WIKIPEDIA,Comparison of project management software, http://en.wikipedia.org/wiki/Comparison_of_project-management_software, 2013
[23] The Blast Team, BLAST, http://mtc.epfl.ch/blast, 2013



