

Actuellement, les processeurs que l'on trouve dans nos ordinateurs ont, pour la plupart, au moins deux cœurs. Aujourd'hui, il est courant de trouver 32 cœurs dans une machine d'un cluster de calcul. Malgré cela, de nombreux programmes sont encore monolithiques et ne s'exécutent que sur un unique cœur. Ils ne profitent pas de la puissance disponible auprès des autres cœurs inoccupés. C'est le cas de nos programmes favoris de compression tels gzip et bzip2. Cet article est consacré à leurs équivalents « parallèles » et à deux autres outils relativement plus récents.
Par défaut, un programme n'est pas assigné à un cœur donné d'un processeur donné lorsqu'il s'exécute sur une machine possédant plusieurs processeurs à un ou plusieurs cœurs.
1. pbzip2
Ce programme est la version « parallèle » du programme bzip2. Comme lui, il tire parti de l'algorithme de Huffman [Huffman] après une réorganisation des données par la transformée de Burrows-Wheeler [BW]. Il utilise par défaut tous les cœurs de tous les processeurs disponibles d'une machine. Il comporte trois options qui paraissent intéressantes pour la gestion de cette « parallélisation » :
- -l qui permet de déterminer le nombre de cœurs à utiliser en fonction de la charge de la machine.
- -p N, où N représente le nombre maximal de cœurs que le programme pourra utiliser. Dans les faits, cette option fixe le nombre de cœurs utilisés.
- -r est une option plus anecdotique qui va lire entièrement le fichier en mémoire puis partager le traitement entre les cœurs. Dans les tests que j'ai effectués, cette option crée un surcoût en temps qui est lié au temps de chargement en mémoire du fichier. En effet, pendant tout ce temps de chargement, les cœurs du processeur ne font rien… Finalement, il s'agit de temps perdu pour la compression du fichier.
La « parallélisation » telle qu'elle est écrite dans pbzip2 est linéaire, comme le montre la figure 3 dont l'échelle est logarithmique.
À noter qu'il existe également une version utilisable avec MPI. Il s'agit là d'une vraie version parallèle utilisable entre plusieurs machines, par exemple sur un cluster.
2. pigz
Pigz est la version parallèle du programme gzip. L'auteur indique qu'il faut prononcer « pig ziiii » (probablement pour ne pas confondre, en anglais, avec le pluriel de « porc » ?!). Il est basé sur la même combinaison d'algorithmes, à savoir, LZ77 [LZ77] et le codage de Huffman.
Les options du programme pigz sont quasiment les mêmes que celles du programme gzip pour des raisons de compatibilité. De cette manière on remplacera directement et sans crainte gzip par pigz dans les scripts existants. Il propose également quelques options spécifiques qui me semblent intéressantes :
- -i qui permet la compression indépendante des blocs. En cas de problème dans le fichier, comme par exemple une lecture partielle, cela permet la décompression des autres blocs entiers subsistants dans le fichier.
- -R qui permet une synchronisation des blocs pour un usage avec rsync. Avec cette option, le nombre de blocs modifiés est minimisé.
- -p N où N représente le nombre maximal de cœurs que pourra utiliser pigz pour faire son travail. Par défaut, en l'absence de cette option, pigz utilisera tous les cœurs disponibles indépendamment de la charge de la machine.
Comme c'est le cas avec pbzip2, la « parallélisation » de pigz est linéaire et d'un facteur 2 (Fig. 3). En effet, si le support de stockage peut soutenir le débit, multiplier le nombre de cœurs par deux divise le temps d'exécution par deux également.
Attention, il ne sert à rien de dépasser le nombre de cœurs réels de la machine. En effet, dans ce cas, le programme se fait concurrence à lui-même pour l'obtention des cœurs et une partie des processus attend que des cœurs soient libérés. Lorsque c'est le cas, les processus qui attendaient s'exécutent et inversement ceux qui s'exécutaient attendent leur tour… L'efficacité n'est pas meilleure. Le plus souvent, cela s'avère même pire !
3. xz
La version 4.9.999 bêta de xz sur mon système de tests ne supporte pas la compression multi-cœur. Il est nécessaire de récupérer les sources de la version 5.1.2 alpha, de les compiler et de les installer pour en bénéficier. Cela s'effectue sans difficulté grâce aux scripts fournis.
Avec les valeurs par défaut, il existe une différence de l'efficacité de la compression entre les deux versions. En effet, la dernière version compresse légèrement moins que la précédente. Cela n'a finalement que peu d'incidence et il vaut mieux pouvoir diviser le temps de compression. En effet, cet algorithme, très efficace côté gain de place, est surtout extrêmement lent !
xz utilise l'algorithme de compression LZMA2 tel qu'il est implémenté dans le kit de développement logiciel (SDK) LZMA écrit pour 7z.
On notera que l'option qui permet de sélectionner le nombre maximal de cœurs utilisé (-T) n'était pas documentée dans l'aide de la commande. L'auteur de cet article ayant proposé un patch, cet « oubli » est maintenant réparé. Cette option est toutefois documentée dans le manuel (man xz) qui comporte l'ensemble des options de la commande.
Les tests réalisés démontrent que, comme pour pigz et pbzip2, la « parallélisation » de xz est bien linéaire.
4. Et les autres logiciels ?
4.1. p7zip
p7zip est la version Unix du logiciel 7zip initialement écrit pour Windows. Il fonctionne parfaitement sous GNU/Linux mais son système d'options qui semble tout droit hérité de feu arj est assez complexe et déroutant pour l'habitué de getopt que je suis devenu. Heureusement, le manuel (man 7z) regorge d'informations et une documentation supplémentaire est fournie avec le paquet [7zdoc].
La « feature request » n° 846 du 21 mars 2009 [7z] demandant la « parallélisation » de 7z est toujours ouverte. Toutefois, cette « parallélisation » est effective pour certaines méthodes de compression. En effet, 7z permet d'utiliser des algorithmes de compression différents et notamment ceux de gzip, bzip2, xz et, avec son propre format de fichier 7z, LZMA et LZMA2 notamment.
En ce qui concerne ce format 7z (option -t7z), l'algorithme par défaut est LZMA. Malheureusement, cet algorithme ne peut utiliser plus de 3 cœurs… Pour utiliser plus de cœurs, il faut demander à 7z d'utiliser l'algorithme LZMA2. Il s'agit de l'algorithme utilisé par xz. L'option à utiliser est -m0=LZMA2. Attention, les options sont sensibles à la casse. Aussi, il convient de bien mettre en majuscules le mot LZMA2. De plus, pour indiquer le nombre Nde cœurs souhaités, il faut invoquer la commande avec l'option -mmt=N. Par défaut, 7z utilise tous les cœurs présents dans la machine.
Étrangement, les tests réalisés font ressortir un taux de compression qui varie avec le support utilisé. 12 octets de plus sur support NFS que sur le disque en mémoire vive, mais surtout 300 Mo de moins sur le disque local ! Cette différence, aussi étrange soit-elle, a été prise en compte dans les calculs.
Les tests réalisés démontrent une bonne linéarité. Avec les options par défaut, le taux de compression de 7z est meilleur que celui de xz (version 5.1.2 alpha) tout en étant légèrement plus rapide. Pour utiliser l'algorithme LZMA2, mieux vaut passer par 7z !
4.2. lrzip
lrzip est un logiciel basé sur rzip. Son principe est de pouvoir repérer des chaînes identiques d'au moins 31 octets sur de grandes « distances ». En effet, sa fenêtre de recherche est de 900 Mo ! Il semble bien adapté pour la compression de gros fichiers, notamment ceux qui pourraient contenir plusieurs fois la même donnée. Il permet l'utilisation de nombreux algorithmes de compression au choix. J'ai choisi ZPAQ car l'auteur indique que c'est l'algorithme qui a le meilleur taux de compression.
Hélas, le test dans la configuration la plus favorable indique que lrzip est plus de 10 fois plus lent que xz, qui est un des programmes testés les plus lents. De plus, même si le taux de compression est bon, il est toutefois moins bon que celui d'xz (sur le fichier considéré).
L'option -n peut sembler intéressante dans le sens où elle ne fait que réorganiser le fichier sans le compresser. Malheureusement, cette partie du code n'est pas « parallélisée ». Elle explique à elle seule la « lenteur » du programme. En conséquence, je n'ai pas fait faire la batterie de tests à ce programme.
5. Les tests réalisés
Tous les tests ont été réalisés sur le même fichier. Il s'agit d'une archive tar de 20 Go. Cette archive est constituée de nombreux fichiers : des petits au format texte et des gros au format binaire réputés difficiles à compresser. Ce dernier point explique le « faible » taux de compression observé quelle que soit la méthode utilisée. Il s'agit d'un « petit » fichier qui représente bien ce que j'archive régulièrement. Les fichiers réels sont toutefois beaucoup plus imposants ainsi, pour moi, le facteur temps est tout aussi important que le taux de compression.
Les essais ont été réalisés sur un seul fichier. Comme la compression dépend fortement du contenu, il est possible de trouver des résultats différents avec d'autres fichiers. C'est là tout l'intérêt de faire ses propres tests afin de trouver quel est le programme le plus adapté.
Les essais ont été réalisés sur une architecture machine unique. Sous l'impulsion de Denis Bodor, rédacteur en chef d'un célèbre magazine, les essais ont été réalisés sur trois supports de stockage différents afin de mesurer l'influence de ce paramètre. Il s'agit de compresser ce fichier à partir d'un serveur NAS [Nas] accédé à travers NFS, du disque local à la machine et d'un disque en mémoire vive ou « ramdrive ».
Le serveur NAS étant en production, c'est-à-dire non dédié à la réalisation des tests, les temps trouvés peuvent ne pas êtres optimums. La machine sur laquelle s'effectue le test est reliée avec un seul lien gigabit, ainsi le débit maximal possible est de 120 Mo/s au mieux.
Le disque dur local de la machine est de classe entreprise, de type SATA et tourne à 7 200 tours par minute. Le débit maximal de tels disques est réputé être entre 150 et 200 Mo/s.
La mémoire des machines est suffisamment grande pour contenir le fichier testé plusieurs fois. La vitesse de transfert maximale du bus est de 6,4 Gbit/s, soit 800 Mo/s.
Chacun des programmes a été lancé avec 2, 4, 8, 16 et 32 threads. En effet, l'architecture machine comporte 4 processeurs de 8 cœurs. Pour chaque exécution, il a été noté le taux de compression, le temps total écoulé et le pourcentage total de CPU obtenu par le processus.
Aujourd'hui, la taille mémoire des machines n'est plus vraiment un problème pour ces programmes de compression qui sont plutôt optimisés de ce côté-là. Du coup, ce critère n'a pas été pris en compte dans les résultats des essais.
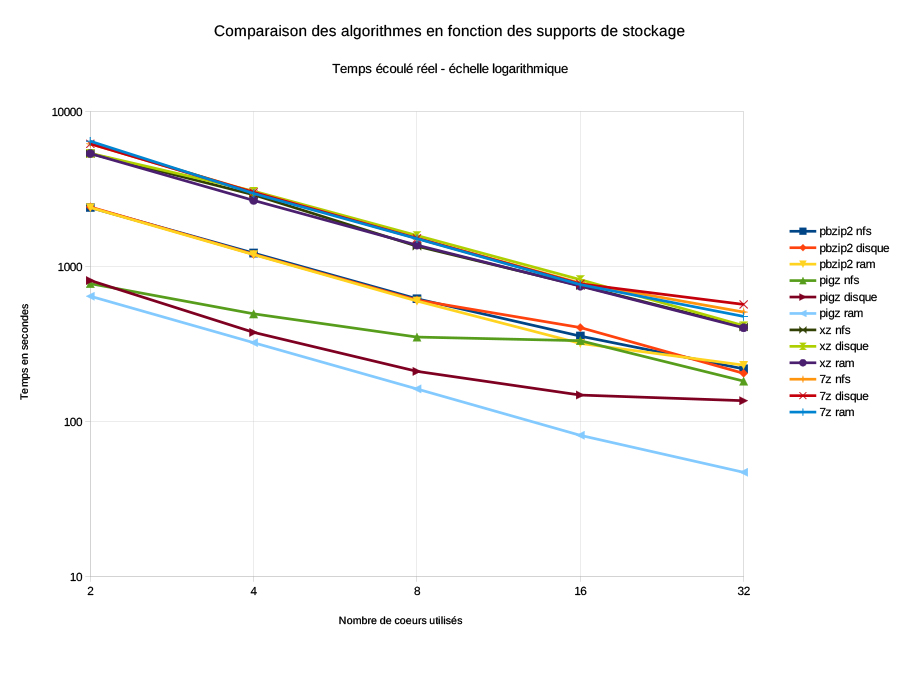
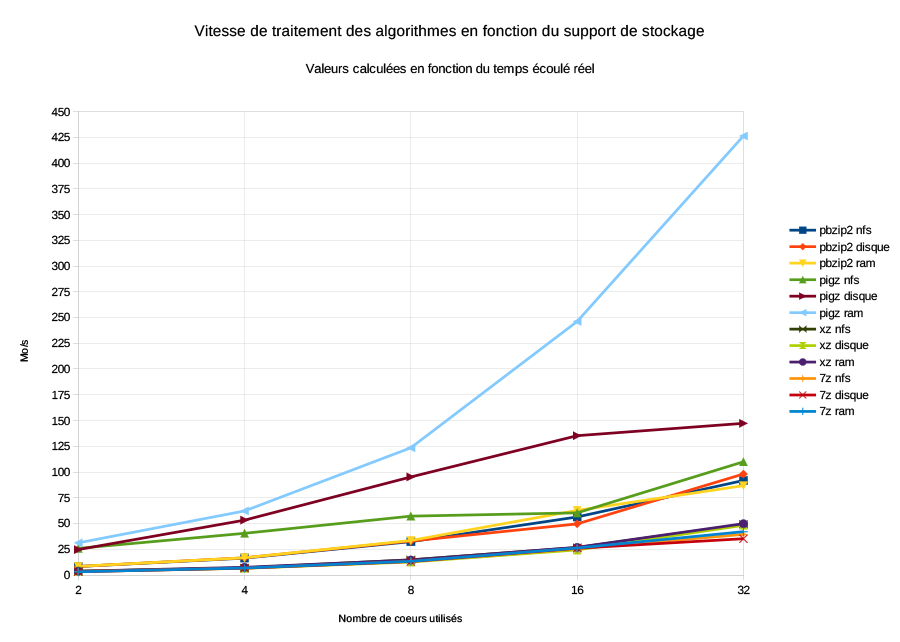
Dans leur ensemble, les valeurs obtenues reflètent bien la tendance de l'implémentation de l'algorithme (Fig. 1). On remarque que seul l'algorithme de pigz était bridé par le débit des supports (voir la courbe « pigz disque » des figures 1 et 2). En effet, les temps d'exécution des autres programmes restent très similaires quel que soit le support utilisé. En revanche, pigz tire bien parti du bus mémoire et améliore nettement ses performances (Fig. 2).
Cela semble vouloir suggérer que pour pigz, le bus mémoire de notre architecture serait limite avec 64 cœurs et qu'il n'est pas utile d'aller au-delà de 32 cœurs pour les autres supports de stockage. En revanche, pour les autres programmes, quel que soit le support de stockage utilisé, on peut s'attendre à des gains de performance significatifs en passant à 64 voire 128 cœurs.
6. Meilleur compromis…
La méthode de calcul utilisée est un peu particulière mais semble adaptée pour tenir compte à la fois du taux de compression et du temps mis pour réaliser le travail. Ce calcul a pour but de minimiser les effets liés à l'activité de la machine.
À cette fin, le calcul a été fait en prenant le temps total écoulé et le pourcentage CPU obtenu. À partir de ces valeurs, on calcule un « temps corrigé ». Ce « temps corrigé » est celui qui aurait été obtenu si le pourcentage CPU avait été maximal. Par exemple pbzip2 met, sur disque et avec 16 threads, 404,53 secondes et obtient 1218 % de CPU sur les 1600 au maximum possible (16 threads). Le temps corrigé est alors de 404,53*(1218/1600) = 307,95 secondes.
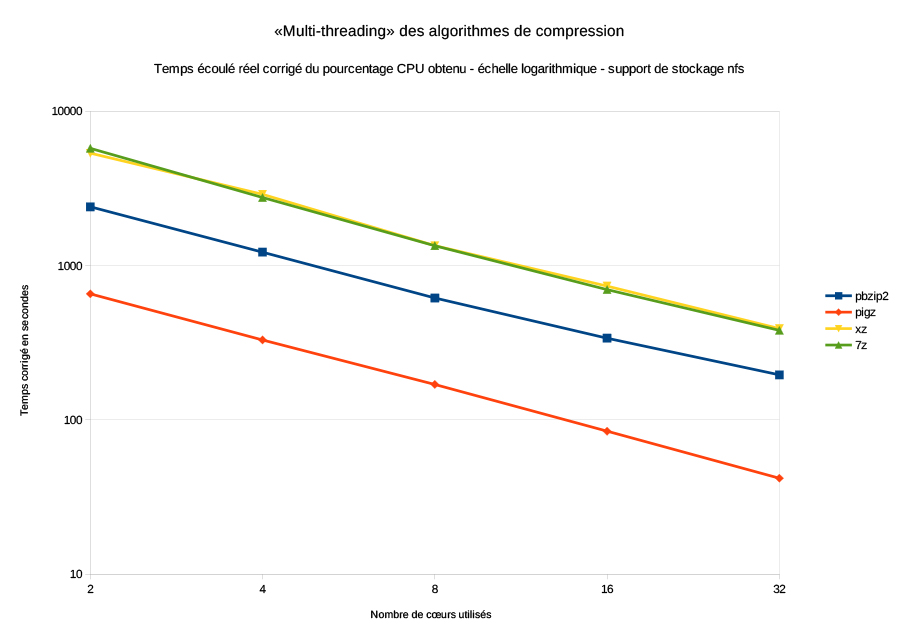
Les figures 3 et 4 sont réalisées sur la base du temps corrigé et ne montrent que les résultats obtenus pour NFS. En effet, en temps corrigé, le support de stockage n'a quasiment aucune influence et les courbes sont pratiquement identiques pour NFS, le disque local ou le disque en mémoire vive.
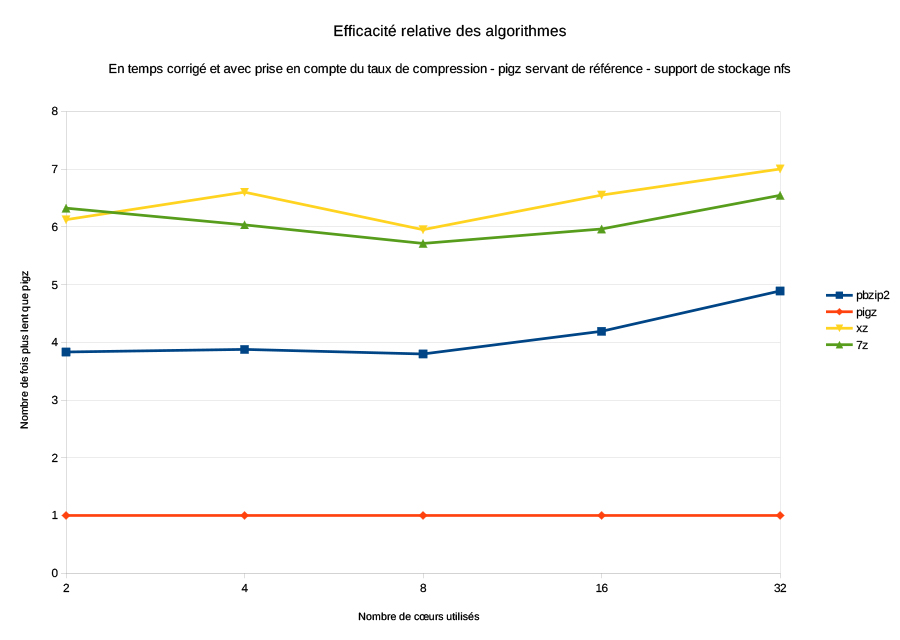
Le taux de compression a été calculé pour chaque fichier produit. Le taux de compression et le temps corrigé obtenus par le programme pigz sont utilisés comme références. Le taux de compression et le temps corrigé des autres programmes sont exprimés en pourcentage relativement à ces références. Ces deux pourcentages (taux de compression et rapidité par rapport à pigz) multipliés entre eux donnent une sorte de valeur d'efficacité par rapport à pigz (Fig. 4). La valeur 1 étant l'efficacité de pigz et la valeur 2, par exemple, indiquant une efficacité deux fois moins bonne.
Pour chacun des programmes testés, le taux de compression est fixe quel que soit le nombre de cœurs utilisés.
Avec 32 cœurs, l'algorithme de pigz est si rapide que le lien réseau de la machine est quasiment saturé (presque 110 Mo/s), que le disque local donne son maximum (presque 150 Mo/s) et que le bus mémoire est exploité à la moitié de sa capacité (plus de 420 Mo/s) (Fig. 2). Ce support de stockage permet à pigz de compresser le fichier tar de 20 Go en un fichier tar.gz de 15 Go en moins de 48 secondes !!
Finalement, c'est bel et bien le format gzip et le programme pigz qui remportent la victoire. En effet, pigz n'a pas le meilleur taux de compression mais l'algorithme est clairement beaucoup plus rapide (entre 5 et 7 fois plus rapide que xz). Du coup, la rapidité compense largement le relatif faible taux de compression.
7. Et ensuite ?
Ces quelques tests sur la compression des fichiers ne doivent pas faire oublier qu'un jour, il faudra décompresser les fichiers obtenus. De manière générale, il n'est pas possible de décompresser en « parallèle » un fichier qui n'aurait pas été compressé en « parallèle ». C'est le cas pour les programmes pigz et pbzip2. En ce qui concerne 7z et xz, il semble qu'ils ne supportent pas la décompression en parallèle. En effet, d'une part les quelques essais réalisés n'ont pas permis de décompresser le fichier généré sur plus d'un cœur, d'autre part les documentations n'indiquent pas clairement que cela est faisable. Au contraire, la documentation de 7z semble dire que ce n'est pas possible…
Pour moi, même si je décompresse nettement moins souvent que je ne compresse, ce dernier point fait pencher un peu plus la balance du côté de pigz et du format gzip.
Références
[LZ77] http://www.cs.duke.edu/courses/spring03/cps296.5/papers/ziv_lempel_1977_universal_algorithm.pdf
[Huffman] http://fr.wikipedia.org/wiki/Codage_de_Huffman
[BW] http://en.wikipedia.org/wiki/Burrows-Wheeler_transform
[7z] http://sourceforge.net/p/sevenzip/feature-requests/846/
[7zdoc] /usr/share/doc/p7zip-full/DOCS/
[Nas] http://en.wikipedia.org/wiki/Network-attached_storage
[Pigz] http://zlib.net/pigz/
[Pbzip2] http://compression.ca/pbzip2/